


Tutorial is loading...
Writer: PrinceOfPersia
Tutorial is loading...
Writer: PrinceOfPersia
Tutorial is loading...
Writer: PrinceOfPersia
Tutorial is loading...
Writer: PrinceOfPersia
Tutorial is loading...
Writer: PrinceOfPersia
Tutorial is loading...
Writer: Reyna
Tutorial is loading...
Writer: PrinceOfPersia

















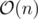


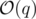

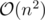

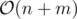
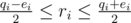 . Denote
. Denote 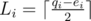 and
and 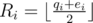 . So
. So 
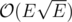 (Karzanov's theorem) and because
(Karzanov's theorem) and because 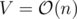 and
and 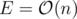 Dinic's algorithm works in
Dinic's algorithm works in 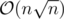 .
.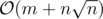

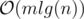 suits because
suits because 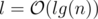 and we need an extra log for sorting events and using set, so the total time complexity is
and we need an extra log for sorting events and using set, so the total time complexity is 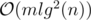 .
.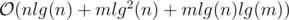

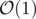

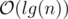 since the height of the tree is
since the height of the tree is 
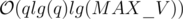

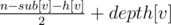 (
( . Suppose
. Suppose 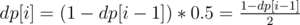 .
. 
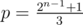 and
and 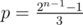 and
and 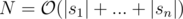 ) and state
) and state 
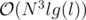 .
.
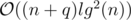
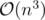 Algorithm:
Algorithm:

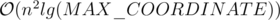



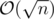 ). If answer is
). If answer is 

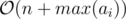 is easy:
is easy: 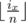 ).
).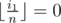 and
and 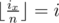 . Of course, for every
. Of course, for every 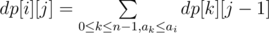

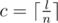 and
and 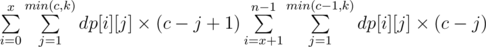 (there are
(there are 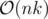
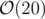 . And then delete the extra values (more than 10).
. And then delete the extra values (more than 10).
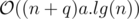
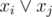 .
.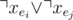 for each pair. But it's not efficient.
for each pair. But it's not efficient.
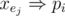 . To make sure about this, we can add two clauses for each
. To make sure about this, we can add two clauses for each 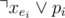 and
and 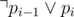 (the second one is only for
(the second one is only for 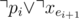 (there are no two
(there are no two 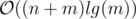 (but slow, because of the constant factor)
(but slow, because of the constant factor) is a Kheshtak of
is a Kheshtak of 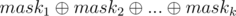 equals to
equals to 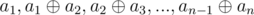 .
.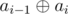

 each element from sequence
each element from sequence 
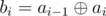 . Let's solve these two problems:
. Let's solve these two problems: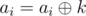
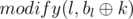 and
and 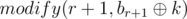 .
.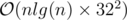 =
= 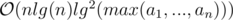
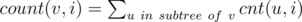 .
.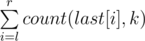 .
.
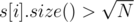 , collect queries (like struct) in a vector of queries
, collect queries (like struct) in a vector of queries  of these numbers, so it can be done in
of these numbers, so it can be done in 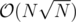 . After doing these, erase
. After doing these, erase 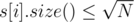 , collect queries (like struct) in a vector of queries
, collect queries (like struct) in a vector of queries 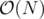 and from the second type is
and from the second type is 


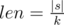 . Then answer is "Yes" if and only if for each
. Then answer is "Yes" if and only if for each 
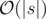 .
.
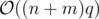

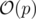

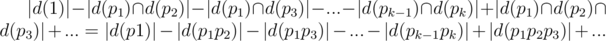

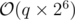 .
.
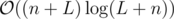
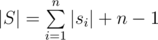 .
.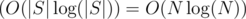 and show it by
and show it by 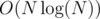 and show it by
and show it by 
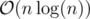
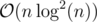 )
)

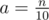 and
and 

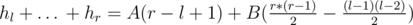 .
.
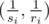 in the Cartesian plane. So, the time a competitor finishes the match is
in the Cartesian plane. So, the time a competitor finishes the match is 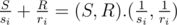 .
.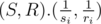 is the scalar product that is smaller if the point
is the scalar product that is smaller if the point 
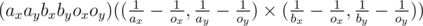 (it's from order of
(it's from order of 



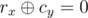 so add an edge between
so add an edge between 