


The most common example when talking about sparse tables is the following problem:
"Given an array of $$$N$$$ integers, your task is to process $$$Q$$$ queries of the form: what is the minimum value in range $$$[a,b]$$$?"
A brute-force approach would be to iterate over all of the elements of each query interval. This approach has $$$O(NQ)$$$ time complexity and is quite slow. One way to improve the time complexity would be to precompute the minimum value for various intervals and then use this information to speed up the queries. For what intervals should we precompute the minimum value?
For a start, let's try precomputing it for all intervals of length $$$2$$$, $$$4$$$, $$$8$$$ and so on. More formally, let $$$rmq[h][i]$$$ be the minimum value on the interval $$$[i, i + 2^h - 1]$$$. One simple and efficient way to precompute this table is by observing that one interval whose length is a power of $$$2$$$ can be split into $$$2$$$ smaller intervals. This observation translates into the following recurrence relation: $$$rmq[h][i] = min(rmq[h - 1][i], rmq[h - 1][i + 2^{h-1}])$$$ . Below is an example of one such sparse table:
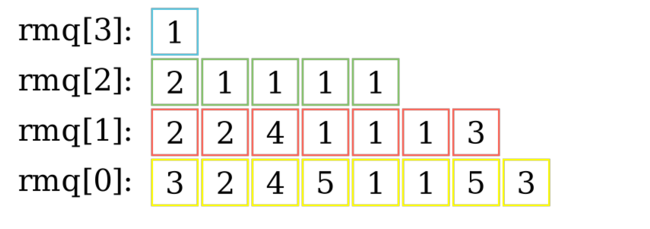
How can we actually use this to solve the queries? We could try splitting the queried interval into $$$logN$$$ disjoint intervals of length power of $$$2$$$. However, in this case we can do better. The $$$min$$$ operation is an idempotent operation. This may sound complicated, however this is simply a fancy math term for an operation that can be applied multiple times without changing the result beyond the initial application. Examples of common idempotent functions include: min, max, gcd, binary and, binary or.
The main advantage of these idempotent functions is that we no longer have to split the queries interval into disjoint intervals. Let $$$[a, b]$$$ be the queried interval and $$$P$$$ the largest power of $$$2$$$ that is smaller than or equal to the length of this interval. To find the minimum on $$$[a, b]$$$ we can simply look at the minimum on $$$[a, a + P - 1]$$$ and $$$[b - P + 1, b]$$$. Since $$$P$$$ is the largest power of $$$2$$$ that fits in $$$[a, b]$$$, these two intervals completely cover $$$[a, b]$$$.
To find the largest power of $$$2$$$ smaller than or equal to some value we can precompute it or simply use language-specific bit tricks. For example in C++ we can use the __builtin_clz function to count the leading zeros, then we can use this value to find the exponent of the largest power of 2 smaller than or equal to the original number. One thing to be careful of is that __builtin_clz(0) is undefined. Rust also has a function that counts the number of leading_zeros.
This allows us to solve the problem in $$$O(NlogN + Q)$$$ time complexity. The link to the problem can be found here and a link to a sample solution can be found here.
What if the function was not an idempotent one? In this case, we could have used disjoint sparse tables to achieve the same complexity. More about this topic can be found in the blog Video about Disjoint Sparse Table or how to answer all queries in constant time by peltorator (Unfortunately, the audio is in russian-only at the moment, however it has english subtitles). A text explanation about this topic can also be found here.
Regarding performance
One often forgotten detail is the fact that there is a time difference between using $$$rmq(h, i)$$$ and $$$rmq(i, h)$$$. This difference stems from the fact that $$$rmq(h, i)$$$ is cache-friendly. For example, see the following pieces of code:
for(int h = 1; h <= lgmax; h++)
for(int i = 1;i <= n - (1 << h) + 1; i++)
rmq[h][i] = std::min(rmq[h - 1][i], rmq[h - 1][i + (1 << (h - 1))]);
for(int h = 1; h <= lgmax; h++)
for(int i = 1;i <= n - (1 << h) + 1; i++)
rmq[i][h] = std::min(rmq[i][h - 1], rmq[i + (1 << (h - 1))][h - 1]);
To understand the performance difference of the above pieces of code, we first have to think about how memory is allocated in C++. A simple array is allocated in a contiguos memory block, but what about multidimensional arrays such as our rmq matrix. The short answer is that a matrix is also allocated this way by placing its lines one after another, thus transforming it into an array. How does this affect us? Let's say that we first access the element $$$rmq[h][i]$$$ and then $$$rmq[h][i + 1]$$$, since these locations in memory are close to each other we can go from one to another extremely fast. Now consider the elements $$$rmq[h][i]$$$ and $$$rmq[h + 1][i]$$$, these elements may seem extremely similar, however there is a whole matrix line between them. These memory jumps may seem inconsequential, but they too affect time efficiency.
Another advantage of $$$rmq[h][i]$$$ over $$$rmq[i][h]$$$ is that the former can be vectorized. In simple terms, this means that since the we apply the same transformation to a line of elements we can process multiple elements at once. Vectorization is something mostly done by the compiler.(In this case vectorization doesn't happen since the compiler cannot vectorize std::min). More information about this can be found in the blog About performance of sparse tables by sslotin.
Memory optimizations
If the queries are given in a offline manner (We receive all of the queries at the beginning) we can separate the queries into $$$logN$$$ groups. In the $$$i$$$-th group we will have the queries with lengths in the interval $$$[2^i, 2^{i + 1} - 1]$$$. To solve all of the queries in the $$$i$$$-th group we only need the minimums over all intervals of length $$$2^i$$$. The minimums over all intervals of length $$$2^i$$$ only depend on the minimum of all intervals of length $$$2^{i - 1}$$$. Thus, we can simply process the groups in increasing order while maintaining the minimums over all intervals of the corresponding power of $$$2$$$. This approach reduces memory to $$$O(N + Q)$$$, a sample submission implementing this idea can be found here.
One major downside to the above method is that the queries have to be given in an offline manner. We can sacrifice time efficiency to obtain a method that doesn't have this downside. A short explanation of one way to achieve this is the following. We can group the elements of the array in blocks of length $$$logN$$$, compress those blocks into an array of length $$$\frac{N}{logN}$$$ and compute a sparse table over this compressed array. We should also precompute the results for all prefixes/suffixes inside a block. To solve a query $$$[a, b]$$$, we have to consider two cases. First, if $$$a$$$ and $$$b$$$ are part of different blocks we can extract the answer by looking at the suffix of $$$a$$$'s block, at the prefix of $$$b$$$'s block and at the interval of complete blocks between $$$a$$$ and $$$b$$$. The suffixes and the prefixes are already computed and to extract information about the interval of blocks we can simply look into our sparse table over blocks. If $$$a$$$ and $$$b$$$ are in the same block we can simply iterate over all the elements in the interval $$$[a, b]$$$ in $$$O(logN)$$$ time complexity. Thus, the total time complexity is in the worstcase is $$$O(N + QlogN)$$$.
Note that a segment tree solution has the same complexity and that the only queries not solved in $$$O(1)$$$ are those completely included in blocks. In some cases, it is possible to optimize those queries to $$$O(1)$$$. An example of such a special case is the find minimum on interval operation. More information on this particular case can be found in the blog Range minimum query in O(1) with linear time construction by brunomont.
Reverse RMQ
One interesting modification is the reverse problem:
"You are given an array of $$$N$$$ elements. You have to process $$$Q$$$ updates $$$(x, y, val)$$$ which transform the array in the following way: For every position $$$i$$$ in the interval $$$[x, y]$$$, $$$v[i]$$$ becomes equal to $$$max(val, v[i])$$$. What is the array after all of the operations have been processed?"
This problem can easily be solved using Segment Trees in $$$O(N + QlogN)$$$. However, if $$$Q$$$ is significantly bigger than $$$N$$$ we can do better.
To solve this, we can use the same idea as before of using the intervals with length power of $$$2$$$. However, this time we will use those intervals to propagate information. Since the max operation is idempotent we can split each update interval into $$$2$$$ intervals with length power of $$$2$$$. Now, we can process the largest intervals by splitting them into $$$2$$$ smaller intervals and propagating the information forward. It may seem that each query contributes to the creating of $$$O(N)$$$ smaller interval, however since we only process intervals of length power of $$$2$$$ the total number of actually created intervals is $$$O(NlogN)$$$.
Thus, the total time complexity of this approach is $$$O(NlogN + Q)$$$. This problem can be found here and a sample solution here.
A more abstract application of reverse RMQ
Sometimes, this technique will be not be as obvious as previously. For example, check out the following problem:
"In this problem you are dealing with strings of length $$$N$$$ consisting of lowercase letters of the English alphabet. Each string should respect $$$M$$$ restrictions of the form:
- $$$(len,x,y)$$$ the two substrings starting at $$$x$$$ and $$$y$$$, having a length of $$$len$$$, are equal.
Count the number of strings respecting all the $$$M$$$ restrictions. Print your answer modulo $$$10^9+7$$$."
A brute force approach would build a graph where each letter of the string is represented by a node and there is an edge between $$$x$$$ and $$$y$$$ if their corresponding characters have to be equal. Let $$$K$$$ be the number of connected components in this graph. Then, the number of valid strings is $$$26^K$$$. We can build such a graph in $$$O(NM)$$$, however that would be far too slow. We can observe that all $$$M$$$ restrictions can be split into $$$2$$$ equivalent restrictions of length power of $$$2$$$.
From here on, we can organize the restrictions into groups. The $$$i$$$-th group will contain all queries with length between $$$2^i$$$ and $$$2^{i + 1}-1$$$. We can process the restriction groups in decreasing order. For each restriction group there are only at most $$$O(N)$$$ relevant restrictions of the form substring $$$[x, x + 2^i - 1]$$$ is equal to substring $$$[y, y + 2^i - 1]$$$. (The other restrictions are irrelevant since they are implied). For each group we have to propagate our restrictions to the next group. For the group $$$i$$$ each restriction $$$(x, y)$$$ creates the restrictions $$$(x, y)$$$ and $$$(x + 2^{i - 1}, y + 2^{i - 1})$$$ for the group $$$i - 1$$$. To determine for each group what the relevant restrictions are we can use DSU. We can observe that we can reuse the same DSU for all groups since the restrictions of each group represent a superset of the restrictions of the previous groups.
The problem can be found here: Substring Restrictions and my solution can be found here. A similar approach is also discussed in its editorial.
Conclusion
I hope that you liked this blog and that you learned something useful from it. If you have any other sparse table tricks or problems, please share them.







I've been enjoying your blogs recently but I've noticed a significant lack of anime references in them. Needless to say I am dissapointed.
NO
I've been enjoying your
blogscomments recently but I've noticed a significant lack of anime references in them. Needless to say I am dissapointed.I've been enjoying your replies recently but I've noticed a significant lack of anime references in them. Needless to say I am dissapointed.
Way to go stranger!
No animations? (Reference to that megamind meme)
I LOVE __builtin_clz
Great tutorial!
very useful information! thank you for the blogpost, kind sir
I couldnt understand this part "A brute force approach would build a graph where each letter of the string is represented by a mode and there is an edge between x and y if their corresponding characters have to be equal. " could you explain it little bit more?
It was a typo. Instead of mode it was supposed to be node. I corrected it now.
The main idea is that a restriction that $$$2$$$ strings have to be equal can be expressed in at most $$$N$$$ individual restrictions that $$$2$$$ characters have to be equal.
We create a graph where each character in the string is represented by a node. If $$$2$$$ arbitrary characters have to be equal, then we can draw an edge between their corresponding nodes.
If $$$2$$$ nodes have a path between them, that means that those $$$2$$$ character have to be equal in all possible strings. Thus, all the elements in a connected component have to be the same letter.
Since there are $$$26$$$ distinct letters in the alphabet, there is a total of $$$26^K$$$ distinct colorings, where $$$K$$$ is the number of connected components.
I hope that this explanation makes things easier to understand.
Oh ok, i got it now! Thanks!
btw, also thanks for your blog!
I really love reading your blogs. Thanks a lot :)
Another problem
Hello sir! Amazing tutorial! Thanks you! BUT does this am not binary lifting?
Thanks! This is very useful.
Huge props for this. I've seen many people incorrectly using $$$rmq(i, h)$$$, or correctly using $$$rmq(h, i)$$$ without knowing why it's better. We often hear the words "cache-friendly" thrown around without really knowing what they mean. How/why do you know an algorithm is "cache-friendly"?
While some might argue that this topic shouldn't really be in the minds of people when they write code (when the problem given is already hard enough; one shouldn't be thinking about cache-friendly approaches), they should know that the time difference between a cache-friendly algorithm and one that is not, can lead to hundreds if not thousands of milliseconds.