


103633A — The Hatchet
Author: tibinyte
Subtask 1 : $$$N \le 10^2$$$
This subtask is easy : Iterate through all pairs an check whether they are winning or not. If you do the check in $$$O(N)$$$ , the total time complexity will be $$$O(N^3)$$$.
Subtask 2 : $$$N \le 10^3$$$
Here we need to find a better way to find if the pair is winning or not. We can use data structures such as : segment tree , RMQ , treaps... The easiest way to do this whatsoever is to just calculate the maximum values "in-place" as you walk through the pairs. Thus we get $$$O(N^2)$$$.
Subtask 3 : $$$N \le 10^5$$$
Let's use a divide and conquer algorithm. Let's say $$$solve(st,dr)$$$ gives us the answer for the range $$$st...dr$$$. Let $$$mid = \frac{st+dr}{2}$$$. Add $$$solve(st,mid)$$$ and $$$solve(mid+1,dr)$$$ to the answer. The only sequences we've not counted are the ones passing through $$$mid$$$. So , we need to find the number of pairs $$$(i,j)$$$ such that $$$mid$$$ is in range $$$i...j$$$ and they hold the propriety. One can notice that every such pair is a reunion of a suffix in $$$st...mid$$$ and a prefix in $$$mid+1...dr$$$. The maxim value in $$$A$$$ will be present in either a prefix or a suffix. Let's iterate through it , and count the good sequences using binary search in the other half. We will count duplicates... But fortunately , we can get rid of them by just using the following trick : When we refer to the position of the maximum value , we will be talking about its leftmost appearance. One can see that this solution runs in $$$O(N \cdot log^2N)$$$
Subtask 4 : $$$N \le 10^6$$$ ( Credits to Gheal )
Let $$$dp_k$$$ store the number of winning pairs (i,j) such that $$$i=k$$$. We need to look for the next "event". By event we mean when either the maximum value in $$$A$$$ changes or the maximum value of $$$B$$$ changes. We need to always go to the next event and use the dp from there. To count the number of pairs until we reach the next event ,we just need to check whether the current maximum in $$$B$$$ is greater or equal to the one in $$$A$$$. Having next[k] = the index where the next change happens if we currently are at index $$$k$$$ , we conclude the recurrence
To calculate $$$next$$$ we can just use two stacks with complexity $$$O(N)$$$. Thus , our final time complexity will be $$$O(N)$$$.
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const ll NMAX = 1e6 + 5;
ll a[NMAX], b[NMAX], nxtgt[NMAX], nxtge[NMAX], dp[NMAX];
ll nxt[NMAX];
int main()
{
ios_base::sync_with_stdio(false); cin.tie(0);
//freopen("in.txt","r",stdin);
ll n;
cin >> n;
for (ll i = 0; i < n; i++)
cin >> b[i];
for (ll i = 0; i < n; i++)
cin >> a[i];
stack<ll> cndgt, cndge;
for (ll i = n - 1; i >= 0; i--) {
while (!cndgt.empty() && a[i] >= max(a[cndgt.top()], b[cndgt.top()]))
cndgt.pop();
nxtgt[i] = (cndgt.empty() ? n : cndgt.top());
while (!cndge.empty() && b[i] > max(a[cndge.top()], b[cndge.top()]))
cndge.pop();
nxtge[i] = (cndge.empty() ? n : cndge.top());
nxt[i] = (a[i] >= b[i] ? nxtgt[i] : nxtge[i]);
cndge.push(i), cndgt.push(i);
}
ll ans = 0;
for (ll i = n - 1; i >= 0; i--) {
dp[i] = dp[nxt[i]] + (nxt[i] - i) * (a[i] >= b[i]);
ans += dp[i];
}
cout << ans;
return 0;
}
103633B — Floor Or Xor
Author: tibinyte
Subtask 1 : $$$N \le 50$$$
For this subtask it is enough to loop through all possible tuples and increment the answer if a valid tuple is found. Time complexity $$$O(N^4)$$$.
Subtask 2 : $$$N \le 2000$$$
We can easily notice how $$$\lfloor \frac{A_i}{A_j} \rfloor$$$ and $$$\lfloor \frac{A_k}{A_l} \rfloor$$$ are basicly indpendent. Thus make an array containing $$$\lfloor \frac{A_x}{A_y} \rfloor$$$ for every pair $$$(x,y)$$$ and count the number of solutions that sum up to $$$T$$$. This can be easily done in $$$O(N^2)$$$ or $$$O(N^2logN)$$$.
Subtask 3 : $$$A_i \le 10^5$$$
We will use the fact that $$$\lfloor \frac{A_x}{A_y} \rfloor$$$ for a fixed $$$A_x$$$ has at most $$$2 \cdot \sqrt{A_x}$$$ distinct values. We will use prefix sums on a frequency array to update the count of each value. This way , we can get an $$$O(10^5 \sqrt{10^5})$$$ time complexity per worst case.
Subtask 4 : $$$A_i \le 5 \cdot 10^5$$$
We can try to go through $$$A_y$$$ instead of $$$A_x$$$. We can see that $$$\lfloor \frac{A_x}{A_y} \rfloor$$$ equals $$$0$$$ in the range $$$0...A_y-1$$$ , equals $$$1$$$ in range $$$A_y....2 \cdot A_y - 1$$$ and so on. Thus we will go through multiples of each value and with the help of prefix sums we can compute the answer quickly.
Time complexity $$$O(5 \cdot 10^5 \cdot log(5 \cdot 10^5))$$$.
#include <bits/stdc++.h>
using namespace std;
int main() {
cin.tie(nullptr)->sync_with_stdio(false);
int n, t, mod;
cin >> n >> t >> mod;
vector<int> a(n + 1);
for (int i = 1; i <= n; ++i) {
cin >> a[i];
}
int maxi = *max_element(a.begin() + 1, a.end());
vector<int> f(maxi + 1);
for (int i = 1; i <= n; ++i) {
f[a[i]]++;
}
for (int i = 1; i <= maxi; ++i) {
f[i] += f[i - 1];
}
function<int(int, int)> query = [&](int st, int dr) {
if (st == 0) {
return f[dr];
}
return f[dr] - f[st - 1];
};
vector<int> cnt(maxi + 1);
for (int i = 1; i <= maxi; ++i) {
if (query(i, i)) {
for (int j = 0; j <= maxi; j += i) {
int st = j;
int dr = min(maxi, j + i - 1);
cnt[j / i] += (1ll * query(i, i) * query(st, dr)) % mod;
if (cnt[j / i] >= mod) {
cnt[j / i] -= mod;
}
}
}
}
int st = 0, dr = t;
int ans = 0;
while (st <= t) {
if (st <= maxi && dr <= maxi) {
ans += (1ll * cnt[st] * cnt[dr]) % mod;
if (ans >= mod) {
ans -= mod;
}
}
st++;
dr--;
}
cout << ans;
}
103633C — Yet Antother Constructive Problem
Author: Gheal
When do we know for certain that no solution exists?
If a solution exists, then pretty much any greedy approach works.
First and foremost, any element $$$ans[i][j]$$$ occurs exactly once in the product of all $$$a_i$$$, and exactly once in the product of all $$$b_j$$$. Therefore, we can conclude that, in order to have a solution, $$$a_1 \cdot a_2 \cdot \ldots a_n$$$ must be equal to $$$b_1 \cdot b_2 \cdot \ldots b_m$$$.
This properity gives us the following inefficient greedy algorithm:
- Initialize all $$$ans[i][j]$$$ with $$$1$$$;
- Select some prime divisor $$$k$$$ of $$$a_1 \cdot a_2 \cdot \ldots a_n$$$;
- Find some indices $$$i$$$ and $$$j$$$ ($$$1 \le i \le n$$$, $$$1 \le j \le m$$$) for which both $$$a[i]$$$ and $$$b[j]$$$ are multiples of $$$k$$$;
- Divide both $$$a[i]$$$ and $$$b[j]$$$ by $$$k$$$ and multiply $$$ans[i][j]$$$ by $$$k$$$;
- Repeat steps $$$2$$$ through $$$4$$$ until all $$$a[i]$$$ are equal to $$$1$$$.
The $$$2,3,4$$$ loop in the previous algorithm can be greatly optimized, as follows:
- For all pairs of indices $$$(i,j)$$$, find the largest prime number $$$k$$$ that is a divisor of both $$$a[i]$$$ and $$$b[j]$$$.
- Divide both $$$a[i]$$$ and $$$b[j]$$$ by $$$k$$$ and multiply $$$ans[i][j]$$$ by $$$k$$$;
- Repeat until there are no primes remaining which are divisors of both $$$a[i]$$$ and $$$b[j]$$$.
This algorithm is already much better, giving us a time complexity of $$$O(N \cdot M \cdot \sqrt{VMAX})$$$, or $$$O((N \cdot M + VMAX)\cdot log(VMAX))$$$, if a sieve is used to precompute the largest prime divisor for all numbers up to $$$VMAX$$$.
Coming up with a more efficient solution requires the following observation: For every pair of indices $$$(i,j)$$$, the second algorithm multiplies, in the end, $$$a[i][j]$$$ by $$$gcd(a[i],b[j])$$$. In conclusion, the most efficient algorihthm would be as follows:
- For all pairs of indices $$$(i,j)$$$, calculate $$$k=gcd(a[i],b[j])$$$;
- Divide both $$$a[i]$$$ and $$$b[j]$$$ by $$$k$$$ and multiply $$$ans[i][j]$$$ by $$$k$$$.
Total time complexity: $$$O((\sum N \cdot M)\cdot log(VMAX))$$$
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const ll NMAX=2e3+5;
int l[NMAX],c[NMAX];
int ans[NMAX][NMAX];
int Gcd(int a, int b){
while(b){
int r=a%b;
a=b;
b=r;
}
return a;
}
void tc(){
int n,m;
cin>>n>>m;
for(int i=0;i<n;i++)
cin>>l[i];
for(int i=0;i<m;i++)
cin>>c[i];
for(int i=0;i<n;i++){
for(int j=0;j<m;j++){
ans[i][j]=Gcd(l[i],c[j]);
l[i]/=ans[i][j],c[j]/=ans[i][j];
}
}
bool good=1;
for(int i=0;i<n;i++)
if(l[i]>1)
good=0;
for(int i=0;i<m;i++)
if(c[i]>1)
good=0;
if(!good) cout<<"-1\n";
else{
for(int i=0;i<n;i++)
for(int j=0;j<m;j++)
cout<<ans[i][j]<<" \n"[j==m-1];
}
}
int main()
{
ios_base::sync_with_stdio(false); cin.tie(0); cout.tie(0);
int t; cin>>t; while(t--)
tc();
return 0;
}
This problem is very classic and much easier than most 9th grade ONI problems. We have decided to include it in the problemset because it's quite fun and instructive (especially for less experienced coders).
I would like to apologise for the weak tests that didn't focus enough on testcases with no solutions.
103634A — Bamboo Coloring
The intended solution is just an optimization of an $$$N^2$$$ greedy solution. A good greedy algorithm should be implemented recursively, as such: Given a connected component of the tree, find a minimal chain (i.e. if the nodes used are sorted then that array would be lexicographically minimal).
When iterating in a component, get the node with the smallest label. Then, "root" the component by this minimum. To extend a chain, we get the minimum on each subtree, and we will try to extend in those that would eventually yield the smallest label. After selecting the nodes that would be a candidate chain, we erase them from the tree, thus remaining with some other subtrees, in which we will solve in a similar fashion. After extracting all the candidate chains, we then proceed to color then according to the smallest node included in it (i.e. the chain with the node "1" will be colored in the color "1", and thus all nodes on this chain will get color "1", then the chain with the next minimum (let's say 4) will be colored in "2", and so on and so forth).
Time complexity: $$$O(N ^ 2)$$$
Observe that a really big issue in our solution is that we constantly have to run through entire sub-components to get the minimal value in them, then we have to find the minimal value in subtrees etc. Optimizing this could be done using segment trees on any liniarization of the tree (i.e. Preorder, Euler Tour, etc.). The only thing we have omitted so far is the fact that in the $$$O(N ^ 2)$$$ solution, we rely on rerooting the component we are solving. After we create a chain, the node with the lowest depth (with respect to the first selected root) might not be the "root" of the component, thus the subtree remains with some "holes". How can we simulate the rerooting of the liniarization?
Answer: we don't have to.
For further simplicity, let's call the nodes that haven't been yet colored "active", and consequently the nodes that have been given a chain called "inactive". Active nodes will be represented in the segment tree with their corresponding value, such that if we try to get the minimal value on a segment, they could be candidates, and inactive nodes will be represented in the segment tree by some absurd value (such as 10^9), so they could never be candidates again
As long as we are solving a subtree (or more rather, a $$$[L, R]$$$ segment) for which all active nodes that appear in the corresponding segment of the subtree in the liniarization form a connected component, then there is nothing to worry about. To maintain this property, we suggest to write the program as follows:
Select the minimal node in $$$[L, R]$$$. Then, define a procedure in which you extend a chain that contains some node $$$u$$$. We go through each of it's active neighbours. To get the minimal node in a subtree corresponding to the father of $$$u$$$, we query everything outside the corresponding segment of $$$u$$$ (with respect to $$$[L, R]$$$). We now recur in the node that yields the minimal continuation.
After thus creating the minimal possible chain, we try to liquidate each subtree whose root is a neighbour of any node on this newly formed chain and its depth is greater than its neighbour's on the chain. We do this in a similar fashion as before.
And now, the most important step of all: if we denote with $$$lca$$$ the node on the chain with minimal depth, then we can safely say that after the previous step, all nodes that are descendents of $$$lca$$$ are now inactive. Thus, we can now try to create another candidate chain in the segment $$$[L, R]$$$, because so far, all we did is to erase the entire subtree of $$$lca$$$, so the graph formed by all active nodes in $$$[L, R]$$$ still form a connected component.
As for time analysis, each node could be only once a minimum value in a subtree, thus finding these values is $$$O(N * log(N))$$$, some nodes could be potential candidates to extention only $$$d(u)$$$ times, thus this step yields a time complexity of $$$O(N * log(N))$$$. Traversing some final candidate chains happens only once, and since every node should be in a chain, the time complexity from this step is $$$O(N)$$$. The rest that happens is mere recursion, so it is already included in the calculations. Finally, atributing final colors to each chain is $$$O(N * log(N))$$$, since we have to sort each chain by its minimal value.
Finally, time complexity is $$$O(N * log(N))$$$ (with a pretty bad constant)
Do note that the solution presented might be one among many. If your solution differs, you are welcome to share it here.
Gheal: This is by far the hardest Div.1 problem, I'm really sorry for everyone who read the innocent-looking statement thinking that this problem is fairly trivial.
Apparently, the tests aren't that great, but we had a lot of trouble getting our solutions to pass them.
valeriu: As much as this problem wasted a lot of my time, I find myself very lucky to have implemented such a problem outside of competition for the first time. Nevertheless, I spent 5 straight hours trying to repair and restructure code, while my colleague admittedly spent 4 days :)). Hope this problem didn't make you want to quit CP.
Note: this code can be further optimized by removing the $$$lca$$$ function
103634B — Xor Or Floor
Author: tibinyte
We will use the following inequality : If we have three integers $$$A,B,C$$$ satisfying $$$A \le B \le C$$$, then $$$min(A \oplus B, B \oplus C) \le A \oplus C$$$. This can be extended for $$$N$$$ integers and it shows us that the minimum xor pair is the minimum xor beetween adjacent values after sorting the array.
Subtask 1 : $$$N,M \le 100$$$
In this subtask we can use the above fact and build $$$dp[i][j]$$$ = how many subsets have minimum xor of adjacent values equal to $$$j$$$ if we only had the first $$$i$$$ elements of the initial array. It is easy to transition in $$$O(N)$$$ and get $$$O(N^2 \cdot M)$$$.
Subtask 2 : $$$N \cdot M \le 10^6$$$
We will use the following trick : The number of subsets having minimum xor equal to k is the number of subsets having xor greater than k-1 — the number of subsets having xor greater than k. Using this observation we can solve $$$f(x)$$$ = the number of subsets having minimum xor greater than x for every x in $$$O(NlogM)$$$ using dynamic programming. Thus , we've reduced the complexity to $$$O(NMlogM)$$$ which is fast enough to get 100 points.
#include <bits/stdc++.h>
using namespace std;
int main() {
cin.tie(nullptr)->sync_with_stdio(false);
int n, m, mod;
cin >> n >> m >> mod;
int lg = 0;
for (int i = 0; (1 << i) <= m; ++i) {
lg = i;
}
vector<int> a(n + 1);
for (int i = 1; i <= n; ++i) {
cin >> a[i];
}
sort(a.begin() + 1, a.end());
vector<vector<int>> cnt(2 * m, vector<int>(lg + 1));
function<int(int)> solve = [&](int lim) {
if (lim == -1) {
int ans = 1;
for (int i = 1; i <= n; ++i) {
ans += ans;
if (ans >= mod) {
ans -= mod;
}
}
return (ans - n - 1 + mod) % mod;
}
vector<int> dp(n + 1);
int ans = 0;
for (int i = 1; i <= n; ++i) {
int qui = 0;
for (int j = lg; j >= 0; --j) {
if (lim & (1 << j)) {
qui += (a[i] ^ (1 << j)) & (1 << j);
}
else {
dp[i] += cnt[qui + ((a[i] ^ (1 << j)) & (1 << j))][j];
if (dp[i] >= mod) {
dp[i] -= mod;
}
qui += (a[i] & (1 << j));
}
}
qui = 0;
for (int j = lg; j >= 0; --j) {
qui += (a[i] & (1 << j));
cnt[qui][j] += dp[i];
cnt[qui][j]++;
if (cnt[qui][j] >= mod) {
cnt[qui][j] -= mod;
}
}
}
for (int i = 1; i <= n; ++i) {
int qui = 0;
for (int j = lg; j >= 0; --j) {
qui += (a[i] & (1 << j));
cnt[qui][j] = 0;
}
}
for (int i = 1; i <= n; ++i) {
ans += dp[i];
if (ans >= mod) {
ans -= mod;
}
}
return ans;
};
function<int(int)> solve_brute = [&](int lim) {
vector<int> dp(n + 1);
for (int i = 1; i <= n; ++i) {
for (int j = i - 1; j >= 1; --j) {
if ((a[i] ^ a[j]) > lim) {
dp[i] += dp[j];
dp[i]++;
if (dp[i] >= mod) {
dp[i] -= mod;
}
}
}
}
int ans = 0;
for (int i = 1; i <= n; ++i) {
ans += dp[i];
if (ans >= mod) {
ans -= mod;
}
}
return ans;
};
vector<int> greater(1 << (lg + 1));
for (int i = 0; i < 1 << (lg + 1); ++i) {
greater[i] = solve(i - 1);
}
int ans = 0;
for (int i = 0; i < (1 << (lg + 1)); ++i) {
int cnt = (greater[i] - (i == (1 << (lg + 1)) - 1 ? 0 : greater[i + 1]) + mod) % mod;
ans += (1ll * cnt * i) % mod;
if (ans >= mod) {
ans -= mod;
}
}
cout << ans;
}
103634C — Jump
Author: Gheal
Part 1: Solving the problem without updates:
Firstly, there are quite a few edge cases:
- It is impossible to get from ($$$X_1,Y_1$$$) to ($$$X_2,Y_2$$$) if $$$X_2 \lt X_1$$$;
- It is impossible to get from ($$$X_1,Y_1$$$) to ($$$X_2,Y_2$$$) if $$$X_1 = X_2$$$ and $$$Y_1 \neq Y_2$$$;
- There exists exactly one path from ($$$X_1,Y_1$$$) to ($$$X_1,Y_1$$$).
Otherwise, $$$X_2$$$ must be greater than $$$X_1$$$. Let's consider the following example:
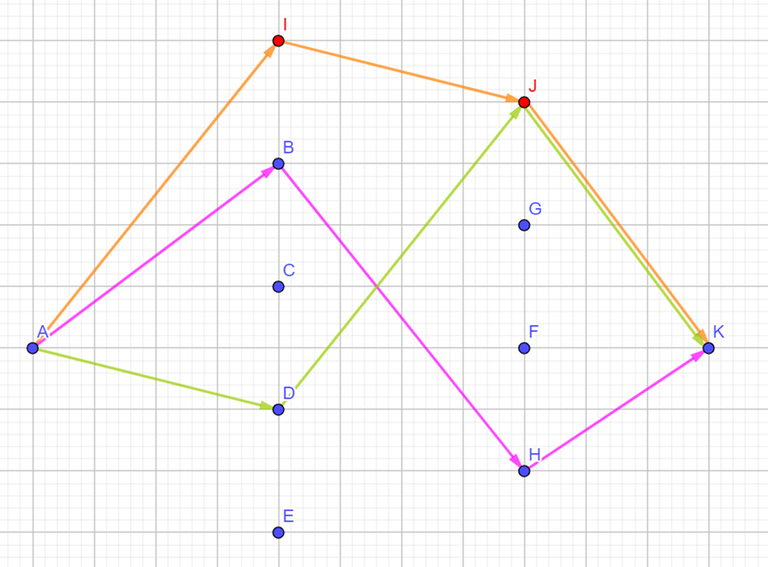
In this example there are $$$9$$$ active points ($$$A,B,C,D,E,F,G,H,K$$$) and two auxiliary points ($$$I$$$ and $$$J$$$). Additionally, $$$X_B=X_C=X_D=X_E=X_I$$$ and $$$X_F=X_G=X_H=X_J$$$. Note that a new auxiliary point has been added for every $$$x$$$-value between $$$X_A$$$ and $$$X_K$$$.
Each path between $$$A$$$ and $$$K$$$ passes through every $$$x$$$-coordinate between $$$X_A$$$ and $$$X_K$$$. For each $$$x$$$-coordinate, a path can either pass through exactly one point ($$$x,y$$$) or through none at all. The latter possibility can be solved by adding one auxiliary point at every $$$x$$$-coordinate between $$$X_A$$$ and $$$X_K$$$. More specifically, if some path skips an $$$x$$$-coordinate, then we can assume that it visits the auxiliary point of that $$$x$$$-coordinate.
With all this in mind, the $$$3$$$ paths highlighted in the image are actually $$$A \to K$$$ (orange), $$$A \to B \to H \to K$$$ (magenta) and $$$A \to D \to K$$$ (lime).
Therefore, the answer is $$$(cnt[X_A+1]+1)\cdot (cnt[X_A+2]+1) \cdot \ldots \cdot (cnt[X_K-1]+1)$$$, where $$$cnt[x]$$$ represents the number of points with that $$$x$$$-coordinate.
It is possible to answer each query in $$$O(log(MOD))$$$ by precomputing an array $$$prod$$$ for every $$$x$$$-coordinate which contains at least one active point:
.
Using this array, the number of ways to get from a point $$$(X_1,Y_1)$$$ to another point $$$(X_2,Y_2)$$$ will be equal to:
.
Part 2: Solving the problem with updates:
Instead of making $$$prod$$$ a prefix array, we can make it a Fenwick tree. Since the values of $$$X_i$$$ are in an inconvenient range, namely $$$[-1e9,1e9]$$$, we can map them to the smaller interval of $$$[1,N+Q]$$$ using coordinate compression.
If a new point $$$(x,y)$$$ is activated, then $$$cnt[x]$$$ will be increased by $$$1$$$. To update $$$prod$$$, a normal BIT update is enough, in which case all affected elements will be multiplied by $$$\frac{cnt[x]+2}{cnt[x]+1} (\text{mod } 10^9+7)$$$. Similarly, if some point $$$(x,y)$$$ is deactivated, all affected elements will be multiplied by $$$\frac{cnt[x]}{cnt[x]+1} (\text{mod } 10^9+7)$$$.
Total time complexity: $$$O((N+Q) log(N+Q))$$$
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef pair<ll,ll> pll;
const ll NMAX=6e5+5,MOD=1e9+7;
ll bit[NMAX],fr[NMAX];
map<ll,ll> compressed;
unordered_set<ll> active;
set<ll> distinctx;
ll inx[NMAX],iny[NMAX];
char t[NMAX];
ll qx1[NMAX],qx2[NMAX],qy1[NMAX],qy2[NMAX],inv[NMAX];
ll binPow(ll x, ll y){
ll ans=1;
for(;y;y>>=1,x=x*x%MOD)
if(y&1)
ans=ans*x%MOD;
return ans;
}
void mul(ll pos, ll val){
while(pos<NMAX)
bit[pos]=bit[pos]*val%MOD,pos+=pos&-pos;
}
ll query(ll pos){
ll ans=1;
while(pos)
ans=ans*bit[pos]%MOD,pos-=pos&-pos;
return ans;
}
int main()
{
ios_base::sync_with_stdio(false); cin.tie(0);
for(ll i=0;i<NMAX;i++) bit[i]=1,inv[i]=binPow(i,MOD-2);
ll n,q;
cin>>n>>q;
for(ll i=0;i<n;i++){
cin>>inx[i];
distinctx.insert(inx[i]);
}
for(ll i=0;i<n;i++) cin>>iny[i];
for(ll i=0;i<q;i++){
cin>>t[i]>>qx1[i]>>qy1[i];
distinctx.insert(qx1[i]);
if(t[i]=='?') cin>>qx2[i]>>qy2[i];
}
for(auto it : distinctx)
compressed[it]=compressed.size()+1;
for(ll i=0;i<n;i++){
inx[i]=compressed[inx[i]];
mul(inx[i],binPow(fr[inx[i]]+1,MOD-2));
++fr[inx[i]];
mul(inx[i],fr[inx[i]]+1);
active.insert(iny[i]*NMAX+inx[i]);
}
for(ll i=0;i<q;i++){
if(t[i]=='!'){
qx1[i]=compressed[qx1[i]];
mul(qx1[i],inv[fr[qx1[i]]+1]);
if(active.count(qy1[i]*NMAX+qx1[i]))
--fr[qx1[i]],active.erase(qy1[i]*NMAX+qx1[i]);
else
++fr[qx1[i]],active.insert(qy1[i]*NMAX+qx1[i]);
mul(qx1[i],fr[qx1[i]]+1);
}
else{
qx1[i]=compressed[qx1[i]];
qx2[i]=compressed[qx2[i]];
if(qx2[i]<qx1[i] || (qx2[i]==qx1[i] && qy1[i]!=qy2[i]))
cout<<"0\n";
else if(qx1[i]==qx2[i] && qy1[i]==qy2[i])
cout<<"1\n";
else
cout<<query(qx2[i]-1)*binPow(query(qx1[i]),MOD-2)%MOD<<'\n';
}
}
return 0;
}
Definitely the easiest Div.1 problem. The time limit is pretty tight because andrei_boaca's SQRT decomposition solutions kept getting 100 points.






Thanks for the amazing contest strangers, it was very fun!!:)
Thank you for the kind words stranger! Congrats on getting top 5 in Div 1!
Thanks, stranger I've never met before!
About Xor Or Floor.
Looking at Editorial's code, it seems to me that it would TLE in cases where M is large (e.g. N = 2, M = 5 * 10^5), am I mistaken?
Nvm
Is it "Floor Or Xor" instead of "Xor Or Floor"? Sorry if I'm wrong.
Exactly my point.
It would, but that can be easily fixed. We only had test data with big N to fail the $$$N^2 \cdot M$$$ solution for the last subtask so I didn't even notice that it would fail for big M. I reuploaded the code which should work for big M as well. Thanks for finding this issue!
Honestly, I don't see the hype surrounding the hatchet, I would honestly bury it.
Gheal please could you tell me why my code is not accepted in? code: https://codeforces.net/gym/103633/submission/151426182
You have TLE, the intended complexity being O(N)
Why should it be TLE, if the complexity of my codes is N log(N)?
The intended complexity is O(N), the limits and tests are tailored to allow only such solutions to get maximum credit.
Thank you for explaining