


Привет, Codeforces!
В Jul/21/2022 17:35 (Moscow time) состоится Educational Codeforces Round 132 (Rated for Div. 2).
Продолжается серия образовательных раундов в рамках инициативы Harbour.Space University! Подробности о сотрудничестве Harbour.Space University и Codeforces можно прочитать в посте.
Этот раунд будет рейтинговым для участников с рейтингом менее 2100. Соревнование будет проводиться по немного расширенным правилам ICPC. Штраф за каждую неверную посылку до посылки, являющейся полным решением, равен 10 минутам. После окончания раунда будет период времени длительностью в 12 часов, в течение которого вы можете попробовать взломать абсолютно любое решение (в том числе свое). Причем исходный код будет предоставлен не только для чтения, но и для копирования.
Вам будет предложено 6 или 7 задач на 2 часа. Мы надеемся, что вам они покажутся интересными.
Задачи вместе со мной придумывали и готовили Адилбек adedalic Далабаев, Владимир vovuh Петров, Иван BledDest Андросов и Максим Neon Мещеряков. Также большое спасибо Михаилу MikeMirzayanov Мирзаянову за системы Polygon и Codeforces.
Удачи в раунде! Успешных решений!
Также от наших друзей и партнёров из Harbour.Space есть сообщение для вас: 
ВОЗМОЖНОСТь ДЛЯ РАБОТЫ И УЧЕБЫ В БАНГКОКЕ — B.GRIMM POWER x HARBOUR.SPACE UNIVERSITY
Компания B.GRIMM POWER в сотрудничестве с Harbour.Space University предлагает стипендии для получения степени бакалавра и магистра в области Data Science и опыт работы в одной из ведущих компаний-разработчиков инфраструктуры в Таиланде.
B.Grimm Power PCL (B.Grimm Power) — компания из Таиланда по производству и распределению электроэнергии. B.Grimm Power занимается разработкой, финансированием, строительством и эксплуатацией электростанций. Ассортимент продукции включает в себя солнечную, гидроэнергию, энергию ветра и дизельное топливо.
Мы ищем кандидатов от младшего до среднего звена для работы над решением задач в различных областях, таких как:
- Анализ данных
- Системная интеграция
- ИИ
- Моделирование прогнозирования
Все успешные кандидаты будут иметь право на получение стипендии со стопроцентной оплатой обучения (22.900 евро в год), предоставленную B.GRIMM POWER.
Обязательства:
Обучение: 3 часа в день
За год обучения вы завершите 15 модулей (длительность каждого 3 недели). Ежедневная учебная нагрузка составляет 3 часа, плюс домашнее задание, которое нужно выполнить в свободное время.
Работа: 4+ часа в день
Погрузитесь в профессиональный мир во время обучения. Вы будете учиться у лучших и с первого дня сможете применять свои новые знания на практике.
Требования:
- Опыт работы в отрасли
- Тяга к обучению
- Предпринимательский менталитет
- (Знание тайского языка приветствуется, но не обязательно)
UPD: Разбор опубликован






I like the education field
Just realised D had more solves than C, I guess I could have tried to solve it. C got me working way too many cases, but, all in vain.
That's so true.
As the loser of the game
Skill issue
I hope that the round will be interesting not only in words, but also in deeds)
codeforces is life Changer
Would you care to explain how?
Super excited! I love edu rounds
Hopefully this one can break through and get a satisfactory placing
Where should I put my heart on a night alone
Hope to solve the C in the round,my goal is to reach 1400
It was very hard problem(
.
When you use n<<1 instead of n*2
warning. and wrong answer
put paranthesis
but if you do like this
int n = 1; n = n + n * 2; cout << n; // 3 cout << endl; int n = 1; n = n + (n << 1); cout << n; // 3then there is no problem-----
But this will cause more troubles than n*2.
This will also bring wrong answer, for example:
So bitwise operations are dangerous.
hoping for a nice round
gimme CM pls xD
good luck!
You didnt give me CM :(
Today problems difficulty gap visualization:
And E&F are much more difficult than D...
E&F unsolveable for target audience.
I hate this round. C is harder than D, that's really not good :)
I just can't find my mistake in C. Also having invested too much time in C, I don't want to try D.
Nice round. But C was definitely harder than D.
Yeah. I'm curious to see the editorial for problem C.
What I did is, if we have to place a number of '(' and b number of ')' in place of the question marks, then it will certainly work to first place a '(' and then place all b closing brackets. (We need to always maintain that count( '(' ) > count( ')' ). The method that is second best to follow the criteria, is we instead place '(' on question marks 1 to a-1, and a+1. If this produces a valid sequence different from the previous one, then the first answer is not unique. Else, there is only a single solution to the problem.
No more hard C please! (As a specialist)
How to solve F?
I imagine the problem as a trie of height $$$n$$$. A multiset of strings is then an assignment, assigning a weight to each leaf of the trie (the number of strings in the multiset corresponding to that path in the trie). You get to set a limit $$$c[s]$$$ to each non-root vertex denoting the maximum sum of weights in that subtree. However, the actual limit of maximum sum of weights in that subtree is smaller, namely $$$d[s] = \min(c[s], d[u] + d[v])$$$, where $$$u$$$ and $$$v$$$ are the children of that vertex.
Let $$$\mathrm{dp}[i][x]$$$ be the number of ways to assign $$$c$$$-s in a subtree of height $$$i$$$ such that the true limit is exactly $$$x$$$. Clearly $$$\mathrm{dp}[0][x] = 1$$$ for $$$1 \le x \le k$$$ and $$$0$$$ otherwise. In the general case, for $$$1 \le i < n$$$ and $$$1 \le x \le k$$$:
The first term corresponds to the case where the sum of limits in the children is $$$x$$$ and we pick a higher limit at the vertex; the second term corresponds to the case where the sum of limits in the children is at least $$$x$$$ and we pick $$$x$$$ as the limit at the vertex. For $$$i = n$$$ it is a bit different because you don't get to pick a $$$c$$$ there.
The convolutions in the formula above can be calculated using FFT: you calculate a layer of the DP, then use FFT to "square" it and calculate the new one, and so on. The answer is $$$\mathrm{dp}[n][f]$$$.
Why are the no collisions in the dp formula in each term?
What do you mean by collisions?
"the second term corresponds to the case where the sum of limits in the children is at least x and we pick x as the limit at the vertex."
I do not understand this idea, how can we choose a smaller limit than the sum of the children? Do the children sum equal the number of strings that have the prefix at node v?
Could you help me with that?
It is too hard to find out what's wrong with my solution in F with only 1 small example. Shouldn't it be more?
I always seem to screw edu rounds :(
what is wrong with my code for D? link : https://codeforces.net/contest/1709/submission/165206888
y1 can be bigger than y2
Got the same bug during contest:(
You need to notice that y1 is no need smaller than y2, and you should query the segment tree from min(y1,y2) to max(y1,y2) instead of y1 to y2.
This bug just delay me 30 mintues from getting accepted.
y1 can be greater than y2. One small change and you would've got AC :_) 165216733
:( i wanna cry
Me too...:(
yes_no_forces :)
I know C's solution will be super cool. Not able to code the solution on time but it's a great problem.
maybe it is dp and stack
It was adhoc.
Video Solution for Problem C & Problem D.
Got AC in C thanks to that. Even though my code is not solving the problem correctly xD
Input:
My Output:
But whatever. I take the AC
The sequence in problem was generated from a valid RBS. So your input is wrong.
ohhh, thanks!
Anyone getting RTE out of nowhere? Or its just me ?
Anyone tell me what tf is wrong with this simple code that its throwing RTE
cin >> n; vll a(3); for (int i = 0; i < n; i++) { cin >> a[i]; }
in this part n is not the size of array.
the size is always 3.
n is the number on the key in your hands.
it's called x in the problem statement.
i hated c
I couldn't even get that far lol.
Just totally baffled me.
got tle on D becouse i used standard cin instead of
ios_base::sync_with_stdio(false); cin.tie(NULL);
:(
Arrrrggggghhhh — same for me....
In this problem we have $$$m + 5q = 2 \cdot 10^5 + 10^6$$$ input numbers, pretty big input.
The sample test case of D was frankly useless.
I spent 40 minutes thinking there was a bug in my Sparse Table, only to notice later that the x coordinates were being given from the bottom instead of from the top as usual.
Even in the problem statement this was not mentioned in bold.
Imho, if there's only one sample test case, it should be at least robust enough to not work for inverted coordinates.
Exactly this is ridiculous my wrong submission was because of this thing. Even the second test does not include hacks for that bug.
today's B and D did feel weirdly lazy/obfuscated...
How to solve E?
Root tree from any node. Let val[v] = XOR of values from root to v. XOR of path (x, y) will be val[x] XOR val[y] XOR a[lca(x, y)]. Now if XOR of path is zero you need to change value at lca(x, y). Doing dfs if there is a path in subtree with XOR 0 you can just delete it. Answer is number of deleted subtrees.
I'm a little confused — how to find if there is path in subtree with xor 0 efficiently?
Small to large trick, you can read editorial of problem E here.
There are few observations. The first one was that if we change a value for a vertex, we can ensure that any paths going through that vertex is never zero as there are only $$$n^2$$$ possible different xorpath values versus infinite choices for the value. The second observation was that let's say we know the optimal connected subset of vertices in subtree of root $$$t$$$ that are good, let $$$S_t$$$ denote this set. If we iterate over the children of vertex u and merge all $$$S_{c_i}$$$, where $$$c_i$$$ is the ith children of $$$u$$$ and if there is a bad path in the resulting set, we remove u. We can simulate this via small-to-large with sets which gives us $$$O(nlog^2(n))$$$.
EDIT: Oops, I messed up the details for the first observation.
Isn't $$$n^2=1e10>2^{31}$$$ ?
You can ignore that because in this problem you can replace the value by any positive integer.
misunderstood D -> Wrong Answer*6 -> rank 1000+ -> absolutely rating fall :(
In C, first I greedily create a valid sequence changing the '?' to '(' while possible, then changing the others to ')'. From these that previously were '?', I swap the last '(' and the first ')'. If this is a correct sequence, then the sequence is not unique. Otherwise, it is. Why does this work, i.e., why could there not be any other choice except the swap I tried?
Swapping same type of bracket makes no difference.
If you try to swap any two brackets of different types, the prefix sum over all these must be >= 2 at all points.
Swapping the last '(' and the first ')' is equivalent to checking if min_range(last '(', first ')') is greater than 2. For all other swaps, they all include this subsequence in this swap, so you only need to check this subsequence.
Like if any other swap work then this will work for example for checking whether a string of parenthesis is correct or not we create a array and do +1 for ( and -1 for ) if we find negative anywhere then it is not allowed string so you already know one solution exist and now what can you try to avoid negative number in array you keep on delaying ) so that the chances for negative number is least
that swap is the most likely swap to be successfull except the ((()))) last ( comes before first ) sequence for a sequence to be valid a) the numbers of '(' and')' have to be equal b) counting from the first, the number of '(' has to be equal or greater than the number of ')' by b) that swap creates the sequence most likely to be valid
What is intended solution for C?
I came up with: First substitute '?' by '(' from left side, from right side by ')'. Then swap the rightmost substituted '(' with the leftmost substituted ')'. If this results in a RBS then ans=NO, else YES.
But somehow not able to make it work until end, maybe some edgecase ?
number of '?' can be less than 2
I had the same idea. Here is my reasoning why it should work: let
abe your first BS. Say we have constructedagreedily.ais an RBS. Say there is another RBSband letibe the first index where it differs froma. Consider the BScwhich is equal tobup toiand constructed greedily after. You can see that ifbsatisfies RBS conditions, then so doesc, then so does your BS with the swap.We don't even need that. Say
ais the first BS,bis the BS with the swap, andiis the first index whereaandbdiffer. Ifbis not a RBS, thenb[...i]has more closing than opening brackets. But for any other candidate BSc,c[...i]would have at least as many closing brackets asb[...i], so it wouldn't be a RBS either.Turned out simple bug:
f[s[i]=='(']++;assuming f[0] is the number of open brackets :/How to solve C
a) How to check if there is a substitution which gives correct paranthesis? First substitute only open parenthesis, then only closed. Example: ??(?))?)(? -> (((())))() there was 2 open parenthesis, hence first $$$n/2-2 = 3$$$ substituted will be open. Check, that this is a correct substitution.
b) How to check if there is another substitution? If there is another substitution, there has to also be a substitution as in a), but with swapped last open and first closed parenthesis. Example: ??(?))?)(? -> ((()))()() here first were substituted $$$3-1$$$ open, then $$$1$$$ closed, then $$$1$$$ open, then $$$2-1$$$ closed. Check, that this is a correct substitution. If yes, answer is NO, otherwise YES.
When i can see other test?
Somebody, please help me find mistake in my submission for D. 165211545 Edit: found it
You can see the test cases(as yours is wrong at small test case) and run on your local to debug
D << C, D is much easy as compared To c
Anyone else who just assume y1 <= y2 in problem D and keep failing test case 4 ?
:(
Me:(
Can someone tell me what the fuck is this? Compiled file is too large [44391155 bytes]
I mean I just used NTT and voila.
your global arrays are too large. it's basically an MLE for when you have statically allocated arrays
probably templates generate too much code?
I think C can be done like this, Imagine replacing ? with $$$+1$$$ or $$$-1$$$. If I have $$$x$$$ question marks with $$$+1$$$ and $$$y$$$ question marks with $$$-1$$$, ($$$x,y$$$ can be easily found by forming simple equations). Then, note that it is always better to put question mark with $$$+1$$$ value behind the question mark with $$$-1$$$ value, So I only need to check for string in which replaced values of question marks looks like this: $$$(1, 1...1,-1, 1, -1, -1...-1)$$$ If this string turns out to be RBS, then answer is "NO", otherwise ans is "YES".
Note that the problem gurantees that at least one valid RBS is possible, so replaced question marks which looks like this should always form valid RBS: $$$(1, 1...1,-1...-1)$$$
PS: Why solutions come to my mind automatically after the contest which i mess up :(
Can anyone help me find mistake in 165181854 ? got TLE in 7th case maybe string error?
http://acm.hdu.edu.cn/showproblem.php?pid=4915 It is a big OJ in China. And this is a classical () problem.
Any idea about test case 7 of Problem E?
Take a look at Ticket 15896 from CF Stress for a counter example.
[submission:165213863]idk why is this submission wa
Found it.Forgot that when all ? are left brackets the array goes to a point that is a undefined zero
No difficulty of thinking, but coding. Boring competition.
No difficulty of thinking, but coding. A boring competition.
as you are a red name, I think it's quite natural for you to have no difficulty of thinking in edu contest.
I mean compare with other div2 contest, this one is quite boring.
E and F, it is natural to think of dp. And one using data structure another using FFT to optimize the transition.
Yeah, it is natural to think of a dp. But if a problem is solved by a thought "hey, this is dp", this does not mean it is a bad task. However, today's E was quite easy to code, so the only really challenging in implementation task is F.
Was it like easy dp? idk really
But need quite code capability.
Also, edu contest is usually implementation based, not so much observation.
Nice problems. C requires a smart observation. D is basic segment tree usage. E is basic small-to-large problem.
what's the smart observation for C?
greedily fill the first several ? with ( and others with ). Then swap the last filled ( and first filled ).
Could you please explain why swapping those two specific brackets works?
Like what's wrong with swapping the first filled '(' and the first filled ')' ?
Take the case
??()??for example. The best case would be to fill all(first and then all), i.e.((())). If you try swapping the "inner 2" brackets as how Aging1986 had mentioned, you'd get()()(), which is a rbs so the answer isNO. If you swap any other two brackets you won't get an rbs.This is because when you swap the "inner 2" brackets, you've already placed all
(as much to the left as possible and all)as much as to the right as possible, so this would always be the next best case in some ways if it is possible.I am a little confused. The only difference between these two submissions is:
Why it can speed up about 1s???
165215022
165212687
The input if fairly big, up to 1e6 numbers, so reading input unoptimized takes relevant time.
All right, thx! I will optimize the input in the following contests.
Who also had WA8 in E because you inserted not after checking for every vertex, but immediately after you checked for this vertex?
I had WA8 for a different reason: I thought the problem only cares about leaf node.
I just was shocked when 6 of my 7 friends who had a submission in E had the same problem.
I found I actually WAed because of the sane reason once.
why did you number the rows from bottom to top ??!
It is edu contest, that is usually implementation based. In this sense, reversing the usual orientation actually spices up the problem.
Also they made statement of B stupid irritating to make it more thrilling.
Wait, are we talking about Educational Rounds or Extended ICPC Rounds in general
Educational Rounds
Can anyone explain to me why my solutions with sparse table and segment tree could not pass until I changed
cintoscanf? Other contestants did not seem to have the same problem.165180154
165184210
Add this line: ios_base::sync_with_stdio(false); cin.tie(NULL);
Yeah, I forgot this template part, makes sense now.
My guess was that I messed up somewhere in the main part and had to compensate for it with fast input. No way 2000 div2 people would just casually submit
scanfsolutions first try LMAOSo hey, how do you decide whether to keep working on a problem or bailing/skipping?
Feel like I hit the worst of both worlds (again) today's C where I had a brute forcer to get lots of (negative, WA) feedback, and therefore spent juuuust enough time failing there to make sure my AC on D came after contest end (and after the same switched-column bug seemingly everyone else had, but then also some MLEs because I left in the simulated grid, woops).
well, I have failed C and solved D on previous 2 contests, so I just move to D if I don't get the idea for C within 10 minutes. I think that D problems can be solved methodically, while C problems are a "you either know it or you don't" style.
In problem C, I thought of first balancing the brackets in the following way : if the number of '(' is more or less than its counterpart, make the number of '?' equal to the difference of number of '(' and ')' become whichever has the minimum count among '(' and ')' and the excess '?'s will be converted according to the one having the greatest count among '(' and ')', extreme ends will be dealt with accordingly with the greatest count among '(' and ')', as the extreme ends can only have one choice.
Now, we reach a case where all the '?'s are in the middle of some brackets and the brackets are balanced. Obviously, the number of '?'s will be even and each '?' can be paired as '()'. If the number of '?'s is zero, this is a unique RBS. Assume we have some positive number of '?'s. Now, if there is at least one '(' to the left of the leftmost '?' and at least one ')' to the right of the rightmost '?', then we can also do it in one other way, i.e. ')('.
I don't know where I'm going wrong, could someone point out what I'm doing wrong or missing ?
Consider that logic, then prepend "()" to the input. Obviously that prefix does not change the answer, but you might get another answer with your algo.
This is the first time that I used the segment tree in a problem. I would say that problem D is one of the best beginner problems for the segment tree.
Fuck n,m in D.
agreed
Disagreed.
I got wa three times for this
My stupid mistake in D was, I just assumed yf > ys for all cases(ik I am dumb) hence segtree quires were giving wrong answer
Samee man, bro, same. Too sad, I realised this just after the contest
A < B < C (Because of observation that we need to make only two distinct valid string for answer "NO") > D
This contest had a decent amount of prefix sums lol.
I had learnt about this pre-built(partial_sum) method to create prefix sums yesterday, unfortunately I was not prepared for custom operations.
Its simple in case of addition. You can read about it here: https://en.cppreference.com/w/cpp/algorithm/partial_sum
unbalanced round makes contest boring
Excuse me if my question is stupid, but is this round not getting rated, or will there just be some delay?
After 12 hours seccion of hacking ratings would update
How to solve E?
Notice that changing the weight is equivalent to removing that vertex.
One approach is to remove the centroid and solve the remaining trees recursively and then remove the centroid if there still exists a zero path going through the centroid.
It can also be solved using dfs and small to large merging.
what value should be on vertices which were removed before some other centroid?
A unique power of two
So when we changed some vertex we dont add its value to some xor value, right? UPD: got it thx
How do you check if there still exists a zero path going through the centroid? Also, what will the recursive subproblem calls return? I kinda know only the basic idea of centroids, should definitely read up on that
edit: apparently this is not the centroid solution. I didn't know that was thing, below I am describing the standard dfs solution.
First of all notice that we just need to save the xor of all the values from root to a vertex $$$u$$$ (call that $$$f(u)$$$). Then the xor of the path between two vertices $$$u,v$$$ is $$$f(u)\oplus f(v) \oplus a[lca(u,v)]$$$.
So now the problem is keeping the sets $$$S(x)$$$ with all values $$$f(u)$$$ for $$$u\in\text{Subtree}(x)$$$. That way you can check if there is a 0 xor path efficiently by going through all children $$$v$$$ of $$$x$$$ and checking if $$$f(x)\oplus a[x]\in S(v)$$$ because $$$f(x)\oplus f(v) \oplus a[x] \iff f(v) = f(x) \oplus a[x]$$$. In that case you "delete" the vertex, clearing it's corresponding set.
To merge the sets fast enough you merge the smallest one with the bigger one. Doing this is fast enough since the number of times a vertex's value $$$f(x)$$$ will move to another set is $$$O(\log n)$$$ because each time you decide to move it to another set of length $$$L' \geq L$$$ ($$$L$$$ is the current length) the new set will be of length $$$L+L' \geq 2L$$$, this can happen at most $$$\log n$$$ times.
Judging from the comments here, the last paragraph describes a well known technique usually referred to as "small to large" and it is specifically useful for problems with sets in trees.
Small to large is not needed for the centroid solution.
Thank you for the brilliant explanation! Finally got accepted:)
how do you prove that centroid works out?
Any vertex works out, centroid guarantees time complexity.
Think about all paths with zero xor. All of them will get at least one vertex removed.
If we remove a vertex, solve the subtrees recursively and don't need to remove the current vertex it's easy to see that it is optimal (because zero paths not containing this vertex would need to be removed).
If we end up needing to remove this vertex, the recursive calls would have removed the same sets, because the zero paths containing the centroid would have been removed as we remove the vertex.
I think that using just any optimal solution in each subtree of a vertex is not enough.
(X)--(_)--(root)--(_)--(X)
In the example above, we have a chain of 5 nodes, the root is the center, and nodes marked with X are removed. Each subtree of the root has a optimal solution, but they don't combine into an optimal solution for the entire tree (the root must be removed as well). You need some extra property for the optimal solution in each subtree: (maybe, for example, among all optimal solutions in a subtree, we select the one where the removed vertices are as close to the root (this is not precise, it's just an idea))
Can you provide a counterexample with weights instead?
Sample input 3.
In this case second and fourth nodes woudl be removed...
This is sample case 3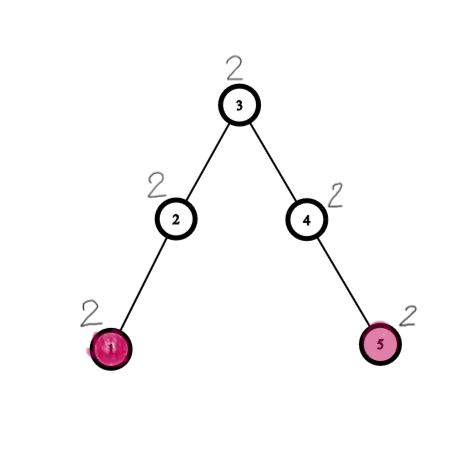
Root the tree at node 3. Both subtrees have optimal solution (one node removed). But they do not combine into an optimal solution for the entire tree (node 3 must be removed)
Each subtree has two optimal solutions. In the left subtree you can either remove node 1 or node 2. If your recursive call returns the wrong optimal solution for the subtree, you can't use it to construct an optimal solution for the entire tree.
Hmm, maybe the centroid solution does not work after all
hey, I had a question:
I wasn't able to participate as I had a school assignment I needed to complete. I just noticed I can still take part in the open hacking... if I do, will it affect my rating?
no
How to solve E?
I couldn't solve C :sob:
https://codeforces.net/contest/1709/submission/165219365
I write this code but it gave WA in test case 2 in "?)?(??" sample.Can someone please explain what is wrong with my code?
The code only seems to cover the simple YES-instances, where the number of ? is exactly equal to the number of ( needed, or the number of ) needed after ensuring the first and last characters are correct. However, there are other YES-instances that your code doesn't cover, like this example of ?)?(??. The only valid RBS here is ()(()). No other RBS fits, so the answer is YES.
For the correct approach, I advise checking the editorial. Basically, you figure out how many hidden ( and hidden ) there are. Here, there are an equal number of visible ( and ), while there are four ?, so this means there are two hidden ( and two hidden ). Then we fill up the ?s, first with all ( until one, then one ), then one (, then the rest of the ). For the example of ?)?(??, the result is ())((). We then check if this is valid or not; in this case, it is not valid, because the prefix ()) has more ) than (. Therefore, the RBS must be unique, i.e., only valid choice is all (s, then all )s.
Note that a valid RBS requires that the total number of ( and ) are equal, and that there is no prefix with more ) than (.
Me : don’t need to know segment tree to hit expert Edu Round 132: Hold my beer !
What a poisonous codeforces round. I used to believe in your codeforces educational round,thinking you have high-standard problems and rounds,but this time you make a big fault in problem C and let many participants down, hope you could learn form this failure and adjust the difficulty in future rounds!
Prob D was such a good intro to segment tree though. But yes C was too much of an ad-hoc problem to be considered educational. (although bracket sequence problems are very standard)
I have a serious problem for a long time! If I use the segtree in Python, it must be TLE, so does it mean that segtree in python doesn't allow in the contest? if not, I think the tester of the contest should test some of the version to let it accepted, quiet confused~
A lot of times I just translate the tutorial solution of C++ into Python, and then it TLE, so unfriendly to Python user
can somebody check my TLE submission for E my complexity is O(NlogN) and I also used bitset :)
How to solve problem F?
i was solving d using segment tree but getting tle again and again on test case 11 can anyone help please. 165261850
This is probably very frustrating to hear, but please add " ios_base::sync_with_stdio(0); cin.tie(0); " to all of your submissions. Then, things like this will not happen again.
How to prove that C's approach is correct
let '(' be 1, ')' be -1, then a parentheses sequence is regular iff the prefix sum off this sequence is nonnegtive at every position and the sum is zero.
You can use this conclusion to proof the correctness.
Use the typical exchange argument. Suppose you have adjacent $$$-1$$$ and $$$+1$$$. Is it good to swap them?
why tle on my soln Queestion D; https://codeforces.net/contest/1709/submission/165267723 ?
tle on test case 11 can somebody help
use fast read lol
The test "?(" can hack many accepted submissions for Problem C. But I miss the hack time.
No, Because it's written in the problem statement that the main string was an RBC before putting '?'s in it, So your test is invalid!
Sorry,I didn't notice.Thanks for your reply.
You're welcome, Could you please explain the proof of your solution for problem C? Thanks in advance.
I'm sorry.I think about it carefully, and I find that I can't strictly prove it.
any hints for D??...like where should I start from :)...
Try to find a way, how robot can always go
okk
Why is it unrated for me?
Dude, the ratings will be published in a while... hacking phase was finished just few moments ago, they will update the ratings soon ::).. It happens in educational rounds , its normal...
I couldn't solve C, but looking at some submitted solutions, I could reverse engineer the logic (after getting rid of some vacuous code in those submissions). Let's make a simple observation. If we go over the input string character by character, the string becomes invalid if number of )'s becomes greater than number of ('s plus number of ?'s at any point. You cannot close more parenthesis than have been opened at any point. Now, maintain two values, surplus of )'s, i.e., number of )'s minus number of ('s, call it
sp, and number of ?'s, call itq. Since there is always a way to substitute ?'s in the input (guaranteed by the problem statement) to get a valid RBS, we know thatspcan never become greater thanq. Also, we know for sure that ifspbecomes equal toq, then all those question marks must be opening parenthesis. Notice that exactly one ofspandqchanges in each iteration and by at most 1. Now, here comes the crucial observation that I believe made this problem hard for many people (including me). Actually, as soon asspbecomes equal toq-1, we know that none of those question marks can be a closing parenthesis, because otherwise the string becomes invalid (think why). So what we do is whensp == q-1, we setsp = -1andq = 0. Then, in the end, range ofspis $$$[-q,q-2]$$$. Ifsp == -q, i.e., all question marks must be ), there is a unique way. We claim that in the end,spcannot be equal to-q+1, because then the input is invalid (think why). Note that ifq= 0, this must hold, otherwise the input is invalid. Otherwisesp != -qand we have maintained the invariant thatsphas been at mostq-2afterqlast became 1. Also, sincespcannot be equal to-q+1in the end,spis at least-q+2. Which essentially means that we can change any of these question mark to either ( or ), while maintaining the invariant all along thatsp <= q, keeping the string valid, so there are at least two ways. (I believe that there is a more elegant argument involving an invariant using parity ofsp - q. If anyone knows, please let me know!)Every "(" gives you a credit and every ")" costs you a credit. Because a bracket sequence is valid iff you don't go out of credits when iterating through, you want to get the credits as early as possible and lose them as late a possible. Therefore the solution that always works is if you replace the first x "?" with "(" and the rest with ")", x denoting the number of missing "(". In the same greedy logic, if there is another possible solution, it will be the one with the last "(" you inserted swapped with the first ")" you inserted (second optimal solution for getting the credits as early as possible and losing as late as possible). I just constructed it and checked if it's valid.
Can anyone tell me what is wrong with my D solution 165201502 ?
you should return -1 ( or anything below zero ) in max fuction instead of 0 ( when l > r )
thank you very much) You realy helped me)
when will be the rating get updated
After the system testing is done.
How much longer will it take
Edu rounds usually take 24 hours for rating updates
Oh!Thank you for your answer
My assessment is that D<E<C
Thanks for interseting C&E, I learn a lot. But D is too obvious(maybe).
Editorial when?
I'm just stuck on 1300s since a year. Sometimes it feels to give up but I'm not like that, I don't want to give this up. I was a lot better when I first started, keep getting worse after each contest.
look at my profile after I reached my max, I dropped down till newbie then got back. just don't give up and don't take long rest periods. finally.. keep practicing, up solving, and learning new data structures.
Thanks for the motivation. I will try my best.
What's the idea to solve F?
Why is my code for D giving me WA?
https://pastebin.com/7axT9xyM
Thanks in advance
I liked the contest
What is test 2 in C? I WA in 452nd
You may want to use https://cfstress.com/
This comment is regarding the solution 165164219 for the problem 1709B which significantly coincides with the solution ForPracticeDude/165161762 (which is actually a temporary ID of mine for practice purpose) during the contest Educational Codeforces Round 132 (Rated for Div. 2). I unintentionally submitted the solution from that ID because it was logged-in in another browser of my PC. It was totally unintentional and I solved both of the problems A & B on my own and I am still trying to reach PUPIL very honestly and I have no intention of CHEATING. But due to this incident both of my solutions are marked SKIPPED.
I can provide the Authorities with the ID and PASSWORD of both the IDs if they are willing to look into this. And I kindly request the Authorities to please Rate me in the contest Educational Codeforces Round 132 (Rated for Div. 2). As what happened was really unintentional and both of the solutions were mine.
ID Link : https://codeforces.net/profile/ForPracticeDude Solution 1 : https://codeforces.net/contest/1709/submission/165161762 Solution 2 : https://codeforces.net/contest/1709/submission/165164219
You solved A first on that account then proceed to solve B on the other one, not solve A and B both on the practice account. Its unlikely to be accidental, that means you logged out after solving A, logged in to the other one to solve B, once its solved, transfer the answer back. You tested the solution with a fake account which is obviously cheating since its unfair for everyone else
It doesn't work like this you need to share the password of both the accounts too.
How to understand question C?
Let's look on sequence $$$s = (??)$$$ First of all, we know that there exist right sequence. Let's find it, $$$s = (())$$$.
Two sequence $$$s$$$ and $$$t$$$ are different if there is a different $$$i$$$-th symbol, or $$$s[i] \neq t[i]$$$. Now let's try change some symbol from $$$s$$$. Try think this way.
can anyone help me find what's wrong in this? submission D
I'm not very good at using this feature and mistakenly sent this message the message I really want to send is below sorry please ignore this message
Appeal of Educational Codeforces Round 132
Dear Sir or Madam, We got a message from the system after “Educational Codeforces Round 132”:
“If you have conclusive evidence that a coincidence has occurred due to the use of a common source published before the competition, write a comment to post about the round with all the details. More information can be found at http://codeforces.net/blog/entry/8790. ”
So we followed the message to appeal. In fact, we did problem C last year and I did problem D this week coincidentally (The only difference of them is the way of input and output). That is why both of our code is similar to so many others. Some of them I don’t know before, they might have done the same problem before. Some of them are my friends, we have done these two problems together, and some of the code we use is the template we decided on together.
The rules in http://codeforces.net/blog/entry/8790 said this is allowed:
“Solutions and test generators can only use source code completely written by you, with the following two exceptions: 1.the code was written and published/distributed before the start of the round, 2.the code is generated using tools that were written and published/distributed before the start of the round.”
Here are the evidences. They all wrote before the contest 132! (If you need more evidence to judge, please contact me):
C: Your text to link here... (where we find C first)
Your text to link here... (where we learn C first)
D: Your text to link here... (the templates that we wrote and published)
We apologize for the extra work this has caused. But we did not break any rules. The same problems are what none of us want to see. Please correctly judge this special case and cancel the wrong punishment for us. We also want to know what to do next time we encounter the same situation. This is not the first time we meet the same problems in codeforces contest that we have done before. Since we are teammate, we need to make our code style same, use the same template, and work on the problem together (not in contest, when we learn). It always leads to the probability of being punished by mistake when we meet the same problem we have done before. We have already done the problem coincidentally before the contest, spending lots of time to learn how it work, But we still have to spend a lot of time modify code in contest to avoid being punished for mistakes. That sounds very unreasonable! Please judge correctly. Withdraw our wrongful punishment. And tell as what to do next time we meet such a situation. (We also don’t like this situation!). If there is anything else we can do for you, please let us know. Yours, AINgray and DeepLearning-
Auto comment: topic has been updated by awoo (previous revision, new revision, compare).
My use of the code on the blog was found to be a violation. The problem C of this competition is similar to the topic on the OJ of Hangzhou Dianzi University I used the blog https://blog.csdn.net/keshuai19940722/article/details/38391841 code on
Is this a violation or is it acceptable?
written in http://codeforces.net/blog/entry/8790 “Currently, the only reliable proof is the presence of code on the Internet and the presence of the used edition in the cache of well-known search engines. For example, this rule accepts the use of the code from the website http://e-maxx.ru/ if the code was written and published/distributed before the start of the round. With the help of search engine caches, it can be easily shown that such code doesn't violate the rules.”
I am getting Tle on problem d on test 11 even after using segment tree. Anyone who can help me
https://codeforces.net/contest/1709/submission/165384286
always remember to add these lines.