


Note that this Saturday, this year's last (before the Olympiad's Open) round of COCI takes place.
Registration and entry into the contest: here. Watch out — don't register for HONI (local version), but COCI.
Feel free to discuss problems here after the contest ends. I'll probably post my solutions here, too.
The contest is over. The results are accessible in your account on evaluator.hsin.hr under the Results tab. The top 5 are:
- bmerry
- andreihh
- eduardische
- svanidz1
- Topi Talvitie
Solutions
(all full, except the last problem; you can find the solution of that problem in the comments)
VJEKO
(code)
Do I even have to write anything? For every word on the input, check if the part of the pattern before the asterisk is its prefix and the part after it is its suffix. If they both are, the answer's yes. Can be implemented more comfortably using the STL substr() function. Any bruteforce works.
FONT
(code)
Assign a bitmask of 26 bits to each word — the i-th bit is 1 iff the i-th letter of the alphabet is present in the string. It's obvious that we're asked to compute sets of words whose bitwise OR is equal to 226 - 1.
We face 2 difficulties here. First, the time limit is too low for an O(N2N) solution. We need an O(2N) one, using something like Gray code. But we can't do a classic Gray code memoization, because we don't have enough memory. We need to find some kind of trick to get a full score. I iterated over all numbers with N - 1 bits (corresponding to subsets of the last N - 1 words) and used the lastone() function from Fenwick trees to always get the last non-zero bit of the number; I remembered the bitmasks of the words corresponding to all bits (in 2 arrays, to save memory; it just adds an if-else condition) and used bitwise magic to make my program faster. When I know the OR value of bitmasks of all words in that subset, I just check separately whether that value's good and whether its OR with the last word's bitmask is good. Time complexity: O(2N); memory: O(2N / 2).
The TEST option helps a lot in estimating what's fast enough.
KOCKICE
(code)
We can only choose the middle column's height. Let's say that this height is H; then, the cost for changing the i-th column of array R is  , and similarly for array S. So then, let's define a new array A with 2N elements:
, and similarly for array S. So then, let's define a new array A with 2N elements: 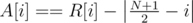 ,
, 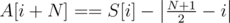 and sort it. If we subtracted H from all elements of A (the sorted order of elements remains the same), the result would be the sum of absolute values of all elements of A.
and sort it. If we subtracted H from all elements of A (the sorted order of elements remains the same), the result would be the sum of absolute values of all elements of A.
If, after subtracting H > 0 from all elements of A, we got A[N + 1] < 0, then subtracting H - 1 would give us a smaller answer. That's because all absolute values of A[1..N + 1] would decrease and at most N - 1 remaining ones could increase — the answer would decrease by at least 1. The same applies for A[N] > 0 (so A[N + 1] ≥ A[N] > 0) and subtracting H + 1 instead of H ≥ 0.
That means: if A[N + 1] ≤ 0, then H = 0 (H < 0 is digging a hole in the ground...); if A[N + 1] > 0, we want H = A[N + 1]. Pick the right H, subtract and calculate the answer. Time complexity:  due to sorting.
due to sorting.
KRUZNICE
(code)
This problem would be called the same in Slovak :D
Observe that we don't need whole circles, the intervals that are formed by their intersection (as full circles) with the x-axis are sufficient. That's because the circles can touch only at the x-axis (proof to the reader). Each circle cuts out one new region from the whole plane or a circle that it's inside of; for each circle c, one more region's added if there are two or more smaller circles that form a chain from one to another end of c. In this case, a chain of circles (or intervals) is a sequence of circles that touch (or intervals with a common endpoint). It's obvious that if such a chain exists, the inside of circle c is cut into 2 symmetric halves; otherwise, those 2 halves are connected, because no 2 circles can intersect, and no other regions can be cut out (once again, proof to the reader; during a contest in this case, an insight into this is sufficient and there's no need for solid proofs).
This sounds like a graph with endpoints of intervals being vertices and intervals connecting the endpoints as edges — participants of Codechef Feb Long Challenge would agree :D. A chain in this case is a cycle formed when adding circles (intervals, edges) by increasing radius.
This kind of adding edges sounds a lot like DSU. In fact, you can apply the DSU algorithm (the answer is then N + 1, for each circle plus the region that remains from the initial plane, plus the number of cyclic edges found during DSU), or just realize that the number of cyclic edges is given just by the number of connected components and vertices of the graph.
Time complexity: , if we want to compress the x-coordinates or store them in a map<>.
HASH
(code)
This problem was another pain in the ass when optimizing time and memory. Seriously, was it so hard to use N ≤ 8 or a time limit of 3 seconds?
My solution is a bruteforce using the meet-in-the-middle trick. The point is that we can calculate hashes of the first 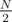 letters for all ways of picking those letters, and also what those hashes would have to be in order to give K when hashing them with the last
letters for all ways of picking those letters, and also what those hashes would have to be in order to give K when hashing them with the last 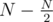 letters.
letters.
The first bruteforce can be done by remembering hashes in a 2D array: H[i] stores all hashes that we can get with i letters (26i elements), and we can get the elements of H[i + 1] by iterating over all elements of H[i] and trying to add each of the 26 i + 1-st letters. It's clear that the hash for every word with ≤ i letters will be computed exactly once and in O(1) time, and the number of those words, and so the time complexity of this part, is 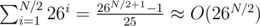 .
.
What about the second bruteforce? Xor is its own inverse and 33 is coprime to the modulus, so it has a modular inverse; its value %2M is I = 33φ(2M) - 1 = 332M - 1 - 1. So if the last letter had an ordinal value of x, then the hash of our word without that letter is ((K^x)·I)%2M (modulo trashes all but the last M bits, so xor doesn't affect it, and multiplying by modular inverse is an inverse operation to multiplying by 33 %2M, so it gives us the hash we're looking for by definition). This is almost identical to the first bruteforce, we just start with K instead of 0 and do the operations (xor, multiplication) in reverse order. The time complexity is the same.
How to merge the 2 results? One more array with some 225 = 3.3·107 elements can still fit into the memory. This array, P, will be the number of occurences of hash P among the first bruteforce's results (the hashes of elements). Traverse all those hashes H, for each of them increment P[H], then traverse the results of the second bruteforce (the required hashes) and for hash H add P[H] to the answer. Once again, every word with hash K will be counted in the answer exactly once.
Time and space complexity: O(26N / 2 + 2M). It actually fits into the limit, if you don't do something stupid like sorting the bruteforces' resulting hashes and using 2 pointers to compute the answer (quicksort is fast, but not fast enough, even if it cuts off the 2M factor from complexities).
GRASKRIZA
(code)
You can look for an optimal solution in the comments. But let me tell you that a stupid bruteforce (add traffic lights to all grid points of the smallest rectangle bounding the input traffic lights, that are above any already existing traffic light) gives 96 points :D
I tell you, I don't miss the times (first COCI contest of 2013/14) when a solution that was significantly faster than a bruteforce got 30% of the points just like a bruteforce.







It would be cool to see your score during the contest, like in IOI,APIO,etc.
I agree. However, I don't know if there will be full feedback in IOI 2014.
I think it should be (at least approximately) known by now. The Slovak national OI always uses rules fit to be similar to the next IOI, and it takes place around the end of March.
Besides, I don't think the system of IOI 2013 would change drastically. Full feedback is good, because the competition is about how well you can code regardless of on which attempt you get AC. And who'd like to be massively penalized for making a small mistake that's very hard to catch. And challenge problems must have feedback (or hundred samples...).
I don't like lack of feedback, anyway. In any situation. Even less so when there are time penalties.
Well, we are assuming full feedback in Finnish IOI training, but I haven't seen any official confirmation about this. IOI 2014 rules haven't been published as far as I know.
Well, if you want to know, you should ask someone who knows for sure. That's the best way.
How to solve the last two problems?
For the last one:
Order the points looking at the x-coordinate, and take the median point P. Then place a light at every point K such that y_K = y_P
Work similarly on the left and on the right recursively...
6th:
Sort all the points by x. Then we'll have a recursive function.
The idea is that we split all the points in half and then have a traffic light line, meaning that all paths from one side to another are now safe. All that's left is to recursively process the internal paths in both sides.
P.S.
if (x != X)is only needed to fit in 700K limit — without it we're going a little over and are scoring only 90%.My ternary-search solution on the third problem failed, I actually had no proof the function was convex yet I submitted it, my bad :D :D
mine failed too. It only passed the first 3 tests. I assume that if there is only one pile, then ternary search is correct, but there are two piles in this problem.
this was my algorithm :
mid = (n / 2) + 1
if i < mid then : a[i] += mid — i
if i > mid then : a[i] += i — mid
now problem is to make all of numbers equal so they must be average rounded up ro down.
but my point for this problem is 20.
my algorithm is wrong or my implementation ?
my algorithm is this and failed! why?:|
I had ternary search too, and it passed all tests.
Could you link your submission please?
Sure: http://pastie.org/8898976
I thought ternary search would work because: First join the two piles into one. Then we need to transform this into a saw-like figure, which has the two lowest points at x. Imagine x is very small, then every column will be above it, and by moving x upward, we decrease the number of steps needed. The same is when x is very large. Now, when we move through the center, we will pass more and more original columns. While the number of columns above is more than below, the number of steps will decrease, but slower as we get to the turning point. Then, at exactly one x, more columns will be below than above, and the number of steps will start growing again. This is not a very formal proof, and it could be wrong, of course…
You aren't sorting, are you?? Was it not allowed to change the order of the columns?! That's what I supposed and I was sorting the input, the problem statement is not clear at all :( :(.
Anyways thank you for taking the time to explain your solution, greatly appreciated :)
I failed on the 4th problem just because I forgot to initialize my union-find disjoint set structure T_T
Can you share your disjoint set idea with me ?!
I solved it by using segment tree.
Begin with the empty plane.
Every time you draw a circle you surely add one region, and in some cases you add two regions.
More precisely, you add two regions if and only if your new circle is touching two circles that are already in contact, directly or through a chain of circles that touch.
So using a disjoint set structure is quite natural...
Third problem was quite hard for the third problem, but I managed to come up with an O(n log n) solution :) Btw. how should the ternary search solution work?
The problems were quite interesting but much harder than the previous contests of this season! (which I like actually :P)
Your solution for the second problem is rather complicated, I simply ran a recursive bruteforce that tries all the possible subsets of words ( Since N <= 25) keeping for each word a mask indicating what letters does this word have, and when adding a word I would OR its bits with the current mask.
http://ideone.com/KD3z6L
I do the same but i got half of the score and as xellos said it's complexity is N*2^N. Have you get the complete score?
You calculate or-result as you recursively iterate over set elements. So by the time you arrive to a actual set, your or-result is already computed.
Yes I got full points. My time complexity is O(2^N) and memory complexity is O(1) (neglecting the O(Alphabit Size) of the masks array and word length.
It should get the complete score. My solution ran on all the tests with 0.00 time.
OK, NO i have done like the thing xellos said(of course without implementation),and now I understand the answer. thanks a lot...
Yeah, the recursive solution seems to be the best here. I'm used to avoiding recursion because some competitions can still limit stack size and because it's usually slower. Then again, time limits are usually sane.
For problem HASH, we can get away with using a single array. We first do a DFS up to depth N/2 and store the results. The hash function is good enough that we need only two bytes to store the count for every possible result. When doing the second, reverse DFS, we don't need to store anything, we just add to the final result. This implementation runs in 0.25 seconds and 67MB space:
Sure it does use 67 MB space, if you're using
short... withints, it's twice that.Yes, what I do is BFS, and what you do is DFS. Both can traverse trees of possible starting and ending halves just as well. But as I mentioned above, I'm usually trying to avoid recursive solutions. And if you stick to
ints and BFS, it's my around 220 MB. Still in the memlimit.Don't get me wrong, I'm not criticizing your solution, it is obviously sound and this one is conceptionally exactly the same as yours. Just wanted to throw in my 2 cents about space optimization here.
I'm not criticizing yours either, just mentioning what I see the differences in (and that the low memory is a trap :D). Everyone has their own preference and I'm fine with that.
For problem KRUZNICE, an alternative approach (which results in a very similar algorithm) is making use of the Euler characteristic formula: F = C + M - N, where F is the number of faces of a planar graph, C is the number of connected components, M is the number of edges and N is the number of vertices.
In this problem, N is just the number of distinct X coordinates of circles intersecting the line
y = 0. M is the twice the number of circles (every edge is a half circle in this scenario). C is the number of connected components in the circle intersection graph, which can be found using DFS. Runtime: Expected O(n). The implementation is really short and simple :)The coordinates are big, so the runtime is . No matter what you do.
. No matter what you do.
Euler's theorem is basically a generalization of what I conclude by
"or just realize that the number of cyclic edges is given just by the number of connected components and vertices of the graph"
which can be derived from scratch without actually knowing Euler's theorem.
I didn't realize it during the contest, just when writing my solution. That's another thing that writing solutions can be good for: the author discovers ways to simplify the solution.
I am well aware that the resulting algorithm is very similar to the algorithm in your post, which is why I mentioned that very fact in my comment. I am also well aware that the same result can be derived without knowing Euler's formula. Again, I am not criticizing your solution, that is not at all the reason I wrote this comment.
The reason is to make people aware of the formula, because it is generally useful for planar graphs and not too well-known. One cannot be expected to derive everything from scratch. Most non-trivial mathematical theorems one is in fact very unlikely to come up with on one's own. There's a certain simplistic beauty in this equation that I'm sure some people can appreciate.
BTW, while your lower bound for the element distinctness problem might be valid in a algebraic decision model of computation, in the real world (or simply a randomized decision model) it can be solved in O(N) at least with high probabilty. I obviously failed to mention that it's not a deterministic runtime, my bad.
lower bound for the element distinctness problem might be valid in a algebraic decision model of computation, in the real world (or simply a randomized decision model) it can be solved in O(N) at least with high probabilty. I obviously failed to mention that it's not a deterministic runtime, my bad.
And again, I'm just comparing it to my solution, not criticizing it :D
To be honest, I don't know about real world programming, I'm only doing the competitive one. What exactly do you mean?
I just meant that operations on hash tables are usually at least expected O(1), and even O(1) with high probability for example if you use linear probing with a hash function drawn from a universal hash family (which is hard to do in reality. You can however use different hashing-based data structures to practically achieve this). So if you're not bound to a deterministic model of computation, you can in fact solve element distinctness in linear time with high probability and thus also solve this problem in O(n) w.h.p.
Riight... hash tables. I almost forgot about that, since I haven't used it for about a year :D. Yeah, it works.
By the way, the first problem has a 1 liner solution using regular expression :)
This is also possible in C++11 by using
<regex>: http://pastie.org/8900862Yes but since I hadn't much experience with c++ regex I used java for this problem :D :D
Full results are available in the system.
No, they aren't. Are you kidding us ?
P.S : I found them. thank you
Yes, they are. Under the Results tab, after you log in.