


Я обнаружил небольшую нехватку материалов на эту тему и хочу начать со статьи rationalex:
Задача
Хотим научиться сравнивать корневые деревья на изоморфизм (равенство с точностью до перенумерования вершин + корень одного дерева обязательно переходит в корень другого дерева).
Хеш вершины
Заметим, что поскольку мы не можем апеллировать к номерам вершин, единственная информация, которую мы можем оперировать — это структура нашего дерева.
Положим тогда хешем вершины без детей какую-нибудь константу (например, 179), а для вершины с детьми положим в качестве хеша некоторую функцию от отсортированного (поскольку мы не знаем истинного порядка, в котором дети должны идти, нужно привести их к одинаковому виду) списка хешей детей. Хешом корневого дерева будем считать хеш корня.
По построению, у изоморфных корневых деревьев хеши совпадают (доказательство индукцией по числу уровней в дереве автор оставляет читателю в качестве упражнения).
Полиномиальный хеш не подходит
Рассмотрим 2 дерева:
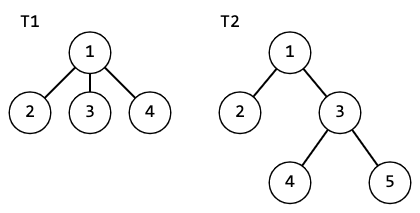
Если мы посчитаем для них в качестве функции от детей взять полиномиальный хеш, то получим: $$$h(T1)=179+179p+179p^2=179+p(179+179p)=h(T2)$$$
Какую же хеш-функцию взять?
В качестве хорошей хеш-функции подойдёт, например
Для этой хеш-функции может показаться, что можно не сортировать хеши детей, однако это не так, потому что при вычислении чисел с плавающей точкой у нас возникает погрешность, и чтобы это результат суммирования был одинаковый для изоморфных деревьев, суммировать детей надо тоже в одинаковом порядке.
Пример более complicated хеш-функции:
Асимптотика
Всё что нам нужно делать на каждом уровне — это сортировка вершин по значению хеша и суммирование, так что итоговая сложность: $$$O(|V| \log(|V|))$$$
Хочу продолжить от себя:
В реалиях Codeforces у данных подходов есть проблемы в виде взломов (что можно увидеть, например, по взломам этой задачи). Поэтому хочу рассказать о подходе, при котором не возникает коллизий.
Что же за хеш-функция?
Давайте для вершины отсортируем хеш-функции детей и сопоставим этому массиву номер, который и будем считать хешем вершины (если массив новый, то присвоим ему минимальный незанятый номер, иначе возьмём тот который уже дали).
Почему это работает быстро?
Легко заметить, что суммарный размер массивов, которые мы посчитали, равен $$$n - 1$$$ (каждое добавление это переход по ребру). Благодаря этому, даже используя для сопоставления treemap, на все обращения к нему потребуется суммарно $$$O(n \cdot \log(n))$$$. Сравнение ключа размера $$$sz$$$ с другим ключом работает за $$$O(sz)$$$ и таких сравнений для каждого ключа произойдёт $$$O(\log(n))$$$, а сумма всех $$$sz$$$ как мы помним равна $$$n-1$$$, так что получается суммарно $$$O(n \cdot \log(n))$$$. (Вы могли подумать что стоит использовать hashmap, но это не улучшает асимптотику и вызывает вероятность коллизии).







Это же просто копия статьи с алгоритмики? Хотя бы ссылку вставь в статью: https://ru.algorithmica.org/cs/hashing/isomorphism/#%d0%ba%d0%be%d1%80%d0%bd%d0%b5%d0%b2%d1%8b%d0%b5-%d0%b4%d0%b5%d1%80%d0%b5%d0%b2%d1%8c%d1%8f
Статья в основном скопирована, с разрешения Александра Гришутина (который упомянут в блоге и писал её для алгоритмики). От себя докинул только последний способ и перевод на английский, на котором не обнаружил подобных тем.
First of all, what do you call a "polynomial hash"? Is it something like sum of "take $$$i$$$-th child, multiply its hash by $$$p^i$$$"? If it is true, then this "hash" changes when we swap two children with different hashes, which shouldn't happen.
UPD: okay, I wasn't very observant and didn't read the whole paragraph with "hash of subtree is hash of sorted list of smth"
Second, I think that the last way you mentioned is the most popular and simple, but just out of theoretical interest one can read this ancient article by rng_58. It contains two pictures which seem to have expired, but I have the second of them:
I tried the approach mentioned in the rng_r8's blog (Multivariable polynomial hashing) but got wa on test case 7. Did I implement it in the wrong way or did the main case had the hack input for which it would give wa.
submission link
You did something wrong. My solution got AC
Thanks people_plus_plus
I compared my code with yours and changed two things and it got accepted.
Firstly, for all vertex my code did....
hash[vertex] *= (depth[vertex] + hash[child]), but I didn't mutliply the hash of that vertex with its own depth. (I didn't multiply the hash of parent which of course was 0 during that time).
It still gave wa.
Then I used mod in the hash multiplication instead of just purely using unsigned long long which automatically mods any value greater than unsigned long long max with unsigned long long max.
However, In rng's blog, he didn't tell to multiply the hash with depth of that vertex itself.
Also, it would be really helpful if you can tell me what is the reason that using a smaller MOD (1e9 + 9) instead of a larged MOD (unsigned long long) avoided collision. Should I do that every time I use hashing?
Where is a reason why you should not use auto mod like you did in your first submission. Standart types use mod $$$2^x$$$ and it can be easily get collision even on small data! You can read about this here https://codeforces.net/blog/entry/4898?locale=ru
In simple words: dount use automatically mods, use your own mods like $$$10^9 + 7$$$. To be sure, use int64 mods. Be carefull when you use hash on codeforces, because there are hacks. You can avoid being hacked by choose a random prime-mod number.
Did you take any permission to publish my algorithm?
There's a way to hash rooted trees which has a better time complexity and is also easy to implement, whose expected number of collisions doesn't exceed $$$O(\frac{n^2}{2^w})$$$. It is mentioned here.
To avoid being hacked, you can use random parameter instead of 1237123 in the article when solving Codeforces problems.
Can you explain the proof of the expected number of collisions and the meaning of $$$w$$$ in $$$2^w$$$? Thank you.
Рекомендую также лекцию по изоморфизму деревьев от Сергея Копелиовича в сборнике с лекциями и разборами «Зимняя школа по программированию 2013», страница 264. Там есть крутые задачи, крутые хеш-функции и крутые идеи.
Деды узнавали об изоморфизме деревьев по этой лекции. Также там есть изоморфизм некорневых (неподвешенных) деревьев.
UPD. Пользуясь случаем рекомендую также раритетную лекцию по жадным алгоритмам в том же сборнике от того же автора чуть ниже, а ещё фулл контест по Warcraft 3 в сборнике за другой год (не помню год).
Там ещё описан способ докрутить метод с классами эквивалентности, описанный в конце блога, до $$$\mathcal{O}(n)$$$ (без логарифма). Если у кого-то с английским получше, чем у меня, можно его перевести.
Polynomial hash works fine, you just need to represent tree's euler tour as a correct bracket sequence —
(when you walk along an edge from parent to child and)when you go backward from child to parent. So T1 will be()()()and T2 will be()(()()). Then hash it as usual string (of course, with sorting childs' hashes).Doesn't it look like it's easier to create a collision with such hashing? (In context of hacks)
Every tree is just a string in such representation. If we use polynomial hashing for strings, why shouldn't we use it in this case?
I solved https://codeforces.net/contest/1800/problem/G using your idea. It's nice
Прикольно
Я сдал то же самое на контесте, что вы описали в своём комментарии. Ходят слухи, что этот детерминированный способ рассказывают на воркшопах МФТИ.
Доказательство упирается в асимптотику вставки и поиска $$$N$$$ векторов в мапе суммарной длины $$$N-1$$$? Может асимптотика будет такая же как просто сортировка набора из $$$N$$$ векторов суммарной длины $$$N-1$$$?
UPD. Увидел, что вы удалили свой коммент из-за того, что данный способ описан в самом конце блога, и доказательство к нему тоже.
ЧЕРТ ТОЖЕ САМОЕ НАПИСАНО В СТАТЬЕ А МНЕ БЫЛО ЛЕНЬ ЧИТАТЬ
Can anybody suggest some problems on the topic?
UPD:
1800G - Симмеtreeя
763D - Тимофей и плоское дерево
Kattis — Two Charts Become One
I recently solved a problem from an ICPC regionals using this technique: Two Charts Become One
It seems often a good idea to compute not hashes for subtrees, but simply numeric representations $$$val(u)$$$ — consecutive integers from $$$0$$$ and beyond, where $$$u$$$ is the root, which defines a subtree rooted at $$$u$$$. The values $$$val(u)$$$ and $$$val(v)$$$ will be equal if and only if the subtrees with roots $$$u$$$ and $$$v$$$ are equal (or isomorphic).
You can just use
map<vector<int>, int> valsfor memoization. Then if for $$$u$$$ you need to calculate the value of $$$val(u)$$$, then take all children $$$w_1, w_2, \dots, w_k$$$ of $$$u$$$ and make a vector $$$[val(w_1), val(w_2), \dots, val(w_k)]$$$. If it has a value in $$$vals$$$, then take the value from there, if not, enter the next integer (well, just use current $$$vals.size()$$$).And just recursively calculate this for all subtrees. In total, it will work for $$$O(nlogn)$$$, apparently. And no issues with possible hash collisions. You can think of the resulting values as perfect hashes.
Thank you! i literally do not know about hashing at all. i just saw your comment and solved the problem 1800G - Симмеtreeя .
My submission if anyone want :- 195934874
Hey, may you please explain a little more on how this algorithm works? I am not able to understand... Please!
Here's how I understand it, and hopefully it helps you.
We want to assign a number for every node $$$u$$$ (we write this as $$$val(u)$$$) based on the structure of its children (by looking at $$$childrenInfo(u) = [val(w_1), val(w_2), ..., val(w_k)]$$$ where $$$w_1, w_2, \dots, w_k$$$ are children of $$$u$$$). So, two nodes with the same $$$childrenInfo$$$ will have the same value in $$$val$$$ and have the same subtree structure (or isomorphic). For example, in this tree:
The algorithm works like DFS. So to calculate for $$$val(u)$$$, we want to first get $$$childrenInfo(u)$$$. Notice that to get $$$childrenInfo(u)$$$, we have to know $$$val(w_i)$$$ for all of its children $$$w_i$$$ first. So do the DFS like the following code snippet. Note that we use
valsto store/remember what number to assign to $$$val(node)$$$ with certain $$$childrenInfo$$$.Wow, great explanation, understood completely :) Thanks for such a detailed comment.
You are welcome! :)
I believe storing hash values for all the subtrees will lead to $$$O(n^2)$$$ memory complexity. Please correct me if I am wrong.
Upd — nvm i understood how it's $$$O(n)$$$
Does anyone know proof of the complexity of this algorithm?
Proofed in the end of post?
I'm asking about an algorithm Mike presented.
This is the algo I described in the end)
Oh shit you're right, thanks.
Someone please share what is the best suitable hash function for a root tree?
I found some other functions like, Hash[node]=(product of (Hash[child]+degree(node)))*(prime^(number_child-1))%mod;
where mod=1e9+7,
What is the simplest function that will not give collisions and can be use?
I just want to know what should be the most suitable hash function for root tree?
Hash[node]=(product of (Hash[child]+degree(node))*(prime^x)%modwhere x=number of child and mod=1e9+7;Is this working hash??
Relevant problem: https://cses.fi/problemset/task/1700/