


Hello Codeforces!
Me and my friend JaberSH1 are glad to introduce this technique to the CP community since maybe only a few people know about it, personally me and Jaber worked on it and we haven't heard/read about such a thing before.
What can it do?
$$$K$$$-th ancestor & $$$LCA$$$ queries in $$$O(N*log(log(N)))$$$ preprocessing, and $$$O(log(log(N))$$$ per query.
Prerequisites:
- Tree basics
- Heavy-Light Decomposition
- Binary Lifting
Ok let's get into it,
$$$K$$$-th ancestor queries:
Given a tree of $$$N$$$ vertices, let's build the HLD chains. For each chain, we are going to store its vertices in an array such that we can reach them by index. Let's take a vertex $$$u$$$, now we want the $$$K$$$-th ancestor of $$$u$$$. It's easy to look it up walking up the chains until we reach the chain with the maximum-depth top vertex for which its depth is less than or equal to $$$depth_u - k$$$. This operation costs $$$O(log(N))$$$ since we only change the chain we are in when the subtree size doubles up. Now imagine another tree containing only the light edges of our original tree, its depth is going to be less than or equal to $$$log(N)$$$. This is equal to adding $$$smart$$$ edges between the top vertices of the chains, each top vertex connected to the top vertex of the chain of its parent. See the picture below:
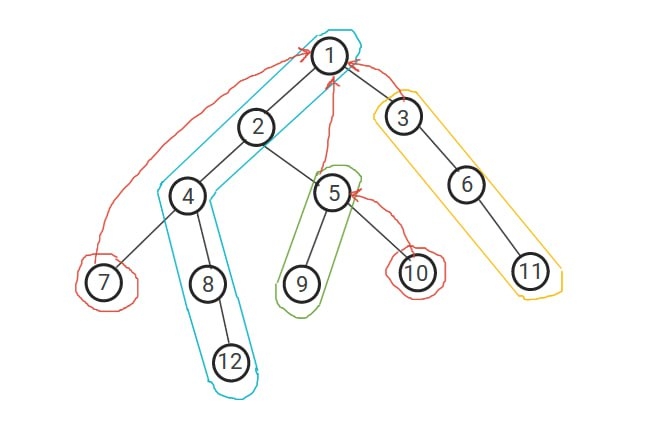
Let's build a binary lifting array over this compressed tree. Since its depth is not more than $$$log(N)$$$ then we will store only $$$log(log(N))$$$ info for each top vertex. Ok, now back to the $$$K$$$-th ancestor query, we can binary lift to the chain with the minimum-depth for which its depth is bigger than $$$depth_u - k$$$, this operation costs $$$O(log(log(N)))$$$. Our required vertex is going to be in the parent chain of this chain and we can reach it by index in $$$O(1)$$$.
$$$LCA$$$ queries:
Using the same technique, we can get the $$$LCA$$$ of two nodes $$$u$$$, $$$v$$$ in $$$O(log(log(n)))$$$ time complexity, we will store for each chain in the HLD tree the depth of the chain (how many chains above it), now if we consider node $$$u$$$ has a chain with higher depth than the chain of node $$$v$$$, we will try to lift node $$$u$$$ to be in a chain with the same depth of the chain of node $$$v$$$. to do this, we will have to find the chain with depth equal to the depth of the chain of $$$v$$$ plus $$$1$$$, and then we will go to the parent of the top node of that chain so now, node $$$u$$$ and $$$v$$$ have the same chain depths, and if they are in the same chain then it's easy to see that the higher node is the $$$LCA$$$. Otherwise, we will lift both chains of $$$u$$$ and $$$v$$$ as long as the head of the chains differ, after we lift the chains, the parent of the chain with the highest top node should be the $$$LCA$$$.







Thank you,very interesting Technique.
:D
Brilliant!! Thx for sharing.
It's really great work. Thank you for your efforts.
Great achievement!!
Thx for your effort. Great technique<3
very interesting thanks!
Interesting technique!
Also I checked your codes on judge.yosupo.jp: first, second and my template, so on tree n <= 5*10^5 simple binary liftings with tin\tout 1.5 times faster than yours( Maybe this can be optimized somehow?
UPD: you can try to send on this problem, there are 10^7 queries and intended solution is O(1) on query, maybe your also AC
Thank you!
Probably the implementation could be optimized further ig, thx for your feedback and testing!
Yes, it passed the second problem. Here's the submission: https://codeforces.net/gym/100091/submission/228193926
Thanks, I didn't know this before, I've solved many problems using this technique
Are you LGM guys ? Very brilliant idea
Interesting idea, but don't stop there. Now you can use "Optimized Binary Lifting Technique" on your compressed tree.
Very interesting!!
But, the preprocessing cost wouldn't be $$$O(n)$$$? Because you spend $$$O(n)$$$ to build the compressed tree, and then $$$+O(log(n)\cdot log(log(n)))$$$ to binary lift on it, which results in a total of $$$O(n)$$$ preprocessing and $$$O(log(log(n)))$$$ per query?
In a worst case scenario the number of chains could be $$$N-1$$$ so it would cost $$$Nlog(log(N))$$$ to build the binary lifting array.
Hmmmmm, you are right, I'm confusing the number of chains with the height of the compressed tree
This technique is well known in Russia (I'm not kidding).
Nice lol
I expected that somebody out there must've come up with this technique before us because it's really straight forward.
Could you maybe provide a link?
Well, during our university algorithmic course we once had a task (as a theoretical HW) to come up with solution to LA with $$$O(n\log \log n)$$$ preprocessing and $$$O(\log \log n)$$$ query time without using 4 russian method. Everyone came up to your's idea :D
these techniques are not easy to find or comes up instantly thanks for sharing