


Idea: BledDest
Tutorial
Tutorial is loading...
Solution (BledDest)
t = int(input())
for i in range(t):
n = int(input())
x = list(map(int, input().split()))
if n > 2 or x[0] + 1 == x[-1]:
print('NO')
else:
print('YES')
Idea: BledDest
Tutorial
Tutorial is loading...
Solution (Neon)
#include <bits/stdc++.h>
using namespace std;
int main() {
int t;
cin >> t;
while (t--) {
int l, r, L, R;
cin >> l >> r >> L >> R;
int inter = min(r, R) - max(l, L) + 1;
int ans = inter - 1;
if (inter <= 0) {
ans = 1;
} else {
ans += (l != L);
ans += (r != R);
}
cout << ans << '\n';
}
}
Idea: BledDest
Tutorial
Tutorial is loading...
Solution (adedalic)
fun main() {
repeat(readln().toInt()) {
val (n, k) = readln().split(" ").map { it.toInt() }
val a = readln().split(" ").map { it.toInt() }.sortedDescending().toIntArray()
var score = 0L
var rem = k
for (i in a.indices) {
if (i % 2 == 0) {
score += a[i]
}
else {
val needed = minOf(rem, a[i - 1] - a[i])
a[i] += needed
rem -= needed
score -= a[i]
}
}
println(score)
}
}
Idea: BledDest
Tutorial
Tutorial is loading...
Solution (Neon)
#include <bits/stdc++.h>
using namespace std;
const int INF = 1e9;
const string vars[] = {"BG", "BR", "BY", "GR", "GY", "RY"};
int main() {
ios::sync_with_stdio(false); cin.tie(0);
int t;
cin >> t;
while (t--) {
int n, q;
cin >> n >> q;
vector<int> a(n);
for (int i = 0; i < n; ++i) {
char s[5];
cin >> s;
a[i] = find(vars, vars + 6, s) - vars;
}
vector<vector<int>> lf(n), rg(n);
for (int o = 0; o < 2; ++o) {
vector<int> last(6, -INF);
for (int i = 0; i < n; ++i) {
last[a[i]] = (o ? n - i - 1 : i);
(o ? rg[n - i - 1] : lf[i]) = last;
}
reverse(a.begin(), a.end());
}
while (q--) {
int x, y;
cin >> x >> y;
--x; --y;
int ans = INF;
for (int j = 0; j < 6; ++j) {
if (a[x] + j != 5 && j + a[y] != 5) {
ans = min(ans, abs(x - lf[x][j]) + abs(lf[x][j] - y));
ans = min(ans, abs(x - rg[x][j]) + abs(rg[x][j] - y));
}
}
if (ans > INF / 2) ans = -1;
cout << ans << '\n';
}
}
}
Idea: BledDest
Tutorial
Tutorial is loading...
Solution (BledDest)
#include<bits/stdc++.h>
using namespace std;
const int MOD = 998244353;
const int N = int(1e7) + 43;
int lp[N + 1];
vector<int> pr;
int idx[N + 1];
void precalc()
{
for (int i = 2; i <= N; i++)
{
if (lp[i] == 0)
{
lp[i] = i;
pr.push_back(i);
}
for (int j = 0; j < pr.size() && pr[j] <= lp[i] && i * 1ll * pr[j] <= N; ++j)
lp[i * pr[j]] = pr[j];
}
for (int i = 0; i < pr.size(); i++)
idx[pr[i]] = i + 1;
}
int get(int x)
{
if(x == 1) return 1;
x = lp[x];
if(x == 2)
return 0;
else return idx[x];
}
void solve()
{
int n;
scanf("%d", &n);
int res = 0;
for(int i = 0; i < n; i++)
{
int x;
scanf("%d", &x);
res ^= get(x);
}
if(res) puts("Alice");
else puts("Bob");
}
int main()
{
precalc();
int t;
scanf("%d", &t);
for(int i = 0; i < t; i++) solve();
}
Idea: BledDest
Tutorial
Tutorial is loading...
Solution (Neon)
#include <bits/stdc++.h>
using namespace std;
int main() {
int t;
cin >> t;
while (t--) {
int n;
cin >> n;
vector<int> a(n);
for (auto& x : a) cin >> x;
vector<int> p(n + 1);
for (int i = 0; i < n; ++i) p[i + 1] = p[i] + a[i];
map<int, int> cnt;
long long ans = 0;
for (int len = 0; len <= n; ++len) {
for (int i = 0; i <= n - len; ++i) {
int s = p[i] + p[i + len];
ans += len;
ans -= 2 * cnt[s];
ans -= (s % 2 == 1 || !binary_search(p.begin(), p.end(), s / 2));
cnt[s] += 1;
}
}
cout << ans << '\n';
}
}
Idea: BledDest
Tutorial
Tutorial is loading...
Solution (awoo)
#include <bits/stdc++.h>
#define forn(i, n) for (int i = 0; i < int(n); i++)
using namespace std;
const int D = 10;
const int INF = 1e9;
typedef array<array<int, D>, D> mat;
mat mul(const mat &a, const mat &b, bool fl){
mat c;
forn(i, D) forn(j, D) c[i][j] = INF;
if (fl){
forn(i, D) forn(j, D){
c[j][i] = min(c[j][i], min(a[j][0] + b[0][i], a[j][i] + b[i][i]));
c[j][0] = min(c[j][0], a[j][i] + b[i][0]);
}
}
else{
forn(i, D) forn(j, D){
c[i][j] = min(c[i][j], min(a[i][0] + b[0][j], a[i][i] + b[i][j]));
c[0][j] = min(c[0][j], a[0][i] + b[i][j]);
}
}
return c;
}
struct minqueue{
vector<pair<mat, mat>> st1, st2;
void push(const mat &a){
if (!st1.empty())
st1.push_back({a, mul(st1.back().second, a, true)});
else
st1.push_back({a, a});
}
void pop(){
if (st2.empty()){
st2 = st1;
reverse(st2.begin(), st2.end());
st1.clear();
assert(!st2.empty());
st2[0].second = st2[0].first;
forn(i, int(st2.size()) - 1)
st2[i + 1].second = mul(st2[i + 1].first, st2[i].second, false);
}
st2.pop_back();
}
int get(){
if (st1.empty()) return st2.back().second[0][0];
if (st2.empty()) return st1.back().second[0][0];
int ans = INF;
forn(i, D) ans = min(ans, st2.back().second[0][i] + st1.back().second[i][0]);
return ans;
}
};
mat tran[D];
void init(int d){
forn(i, D) forn(j, D) tran[d][i][j] = INF;
for (int i = 1; i <= 9; ++i){
tran[d][i][i] = i;
tran[d][i][0] = i;
}
tran[d][0][d] = 0;
}
int main() {
cin.tie(0);
ios::sync_with_stdio(false);
for (int i = 1; i <= 9; ++i) init(i);
int n, k;
cin >> n >> k;
string s;
cin >> s;
minqueue q;
forn(i, n){
q.push(tran[s[i] - '0']);
if (i - k >= 0) q.pop();
if (i - k >= -1) cout << q.get() << ' ';
}
cout << '\n';
return 0;
}






finally it is released.!!!
In D, also you can use bellman-ford after construct a graph: 276620074
can you explain your construction of graph?
can you use dijkstra with you graph or not?
You have 2e5 queries so in total it will be TLE
The implementation / logic of F makes me feel I am the dumbest man on planet.
Same, it is very unintuitive for me how you can just add the cumsums; This implementation makes a lot more sense to me: 276838911
I like this kind of solution. This solution is completely different from author's solution.
Can someone please explain this marked solution? How is looking at the difference in the prefix sums giving the answer? The ranges (i,j) with same Prefix sums can be completely disjointed after all
What do you mean by disjoint? Lets denote the first range as $$$i_0$$$-$$$j_0$$$ and the second one as $$$i_1$$$-$$$j_1$$$. We can only account for $$$i_0 < i_1$$$, Also we can say $$$j_0 < j_1$$$ because other ways the second range will always have smaller sum than the first.
This means that the first range always describes a prefix and the second one a suffix, that have a unique start and end point. Now it is just counted how often they are the same.
Enjoy the process in thinking problems.
can someone explain to me what is wrong with my solution of problem C : 276692116
It is actually causing Overflow, check your output. You can see negative value. When we add positive numbers, we can never get negative values, unless you got memory overflow.
yeah, in accumulate i had to write 0ll instead of just 0. Thanks.
I faced something like this... maybe using Long Long can fix it.
Hello ..
Can anyone tell me that for problem D , why this solution is giving wrong answer https://codeforces.net/contest/2004/submission/276820238 or can anyone suggest some test cases where this failed
You can actually find the failing test yourself.
Checker's output says "wrong answer 248th numbers differ — expected: '3', found: '-1'". That means you only need to add something like "if (test_id == 248) then print(all input)" to your code (and don't print anything else so that the output is not too large). The verdict will still be WA but at least you'll get to see the problematic test.
damn, i was actually looking for something like this thanks
It says 248th number, and not 248th testcase. So we don't know which testcase number it really falls under :(.
Then you could replace test_id == 248 with query_id == 248
Can you explain more clearly how to do this ?
where to put test_id ?
it won't work for failure on large tests.. like my this submission failing on some 27610th test case... that much input is also not available on that test case..
ohk thanks
but it won't work for system
tests as it will wrong answer
on querry no. 248 of some previous test case and programm will itself terminate
can you explain a bit more? Like how & where to do it?
https://codeforces.net/blog/entry/132790?#comment-1186152
Hey could you please tell what am i missing in this D problem :- 276639203. This got WA .
But this got AC :- 276654708
Could you please tell what is the difference
you are considering wrong combination of string to search. i.e) if temp1 is RY and temp2 is BG then your first combination would be RB which is not possible
Take a look at Ticket 17471 from CF Stress for a counter example.
finally the text editorial is here, still waiting for rating recalculation :(
can anyone tell why this solution for problem D is giving tle ?
youre using maps and sets a bit too much probably
ig time complexity is O(q*4*log(n)) which should not give TLE
ohh yeah, you just have to add & before st "for(auto st:mp[a[x]])", i just added the & and it passes 276829023. by adding &, you iterate over the elements by reference which is much faster.
thanks, got it
change auto st to auto& st
why did problem E get so much hate and backlash ? the problem is actually really nice and high quality even tho there were 10+ videos that leaked the solution first hour which had nearly 5k views combined that doesnt take from the quality of the problem i honestly found it really interesting and gives a new way of approaching problems atleast for me
I said the same in original Contest post. and guess what, heavily downvoted. I would say it again. E was a nice problem.
i think they are missing the core idea tbh i always underrated trying to prove facts from realizing a pattern but this problem proves that sometimes looking at the pattern and trying to build intuition then proving it (proofs for this problem are really easy and i 100% believe most experts+ will be able to reason enough to prove the pattern) actually is a valid idea and sometimes solves even hard problems
ik this is off topic but wow dude how did you go from grey to purple in less than a year? as someone who's given about 5 contests it looks lowkey impossible for someone like me
it also looked impossible for me after 5 contests but after 60 u will realize its not
In the editorial for problem F, it is written that: "It can be shown that it doesn't matter which of these actions we take".
Please mention in the editorial how it can be shown. I have an intuition for this, but I don't have a rigorous proof.
i dont get this part aswell if u understand it please explain it below here
A rigorous proof would be something like that:
Consider the prefix sums of an array, and denote $$$s$$$ as the sum of all elements in it. An array of positive integers is palindromic if and only if its prefix sums are "symmetric" with $$$\frac{s}{2}$$$ as the center (i.e. if an integer $$$\frac{s}{2} + x$$$ exists in the array of prefix sums, then the integer $$$\frac{s}{2} - x$$$ should also exist, and vice versa). If there is a pair $$$(\frac{s}{2}-x, \frac{s}{2}+x)$$$ such that only one of these elements exists in prefix sums, this pair violates the condition, and we need to "fix" every such pair.
Now consider what our actions do to the array of prefix sums. When we merge two adjacent elements, we delete a prefix sum. When we split an element, we add a new prefix sum between the existing two. Every such action can "fix" one of the violating pairs $$$(\frac{s}{2}-x, \frac{s}{2}+x)$$$: merging two elements deletes one element from a pair, and splitting an element adds an element into the pair. So, if we have a pair that violates the condition, it doesn't matter whether we fix it by split operation or merge operation — we will still spend one operation to fix this pair.
Thanks !
This is amazing. I think it should be written inside the editorial.
I think a rigorous proof might also go like this:
Given the array $$$b[1\cdots n]$$$ after doing the minimum number of operations to make it a palindrome.
While possible, pick any element $$$b_i$$$ that was obtained by a split operation, and do the following:
$$$ \textbf{Case 1:} \text{ if } i > \left\lceil \frac{n}{2} \right\rceil \text{or } i < \left\lfloor \frac{n}{2} \right\rfloor \text{, undo the split operation in any possible direction, and fuse } b_{n - i + 1}$$$
$$$\text{in the opposite direction that } b_i \text{ got unsplit towards.This increases the number of operations by at most 0.} $$$
$$$ \textbf{Case 2:} \text{ if } i = \left\lceil \frac{n}{2} \right\rceil \text{or } i = \left\lfloor \frac{n}{2} \right\rfloor \text{, do the same as case 1 but if the direction of unsplit of } b_i \text{ is towards } b_{n - i + 1}$$$
$$$\text{don't do anything after the unsplitting step. This also increases the number of operations by at most 0.} $$$
$$$ \textbf{Case 3:} \text{ if } i = \frac{n}{2} \text{, unsplit } b_i \text{ and fuse the result in the opposite direction.} $$$
Note: when you fuse two elements $$$b_i$$$ and $$$b_j$$$, the state of the resulting element is the union of the split directions of $$$b_i$$$
minus the direction $$$b_i \rightarrow b_j$$$ and the split directions of $$$b_j$$$ minus the direction $$$b_j \rightarrow b_i$$$.
This process has to end because in each iteration you decrease the number of split elements by at least 1.
A similar argument can be constructed to convert all fuse operations to split operations.
This proof is also helpful. Thanks !
Any idea why this submission for Problem D is going TLE? As per my understanding, the time complexity for this should be O(q * 6 * logn) which should be within limits I guess. Thanks in advance!
https://codeforces.net/contest/2004/submission/276826924
Ok I see, issue was with 1., deep copying of vector. 2. Solves it. So dumb, it was going to be the first time I solved a D in div 2!!
1.vector<int> nodes = colorToNodes[all_colors[j]];2. vector<int>& nodes = colorToNodes[all_colors[j]];I thought of applying dfs for D but will it give tle?
probably yeah
Yes. If you're checking every possible index, then time complexity will be approximately O(N*Q) because in the worst case, let's say, you will be getting the same x and y each query, and every other string will be suitable. Then, for each query you will be checking N-2 elements. Rounding up, it is N*Q
It will be o(nq) so yeah
Can someone tell me why my code here isn't necessarily correct? 276831391
I understood the idea quite well, as you essentially need to check if there exists a city in between x and y, as well as if the closest two cities not in the range to x and y respectively, but I'm not certain why my above submission is WA, while this submission 276831747 is.
Thanks in advance :D
Take a look at Ticket 17468 from CF Stress for a counter example.
I see, I understand what I was doing wrong now. In my head I thought I was checking the two possible city locations, but I guess my code didn’t reflect that :/. Thank you very much!
Idk how the B task was for you guys. But for me, as a beginner, it's very tricky.
To be honest, I was also confused by this problem. I tried to solve it by math first, but decided to just write brute force.
Hello ...
https://codeforces.net/contest/2004/problem/D
Could anyone tell why this is giving TLE for Problem D and how could i improve .
In this line
you're copying a whole set which maximum size can be $$$2 \cdot 10^5$$$. Potentially this copy can be done for each query (again $$$2 \cdot 10^5$$$) and moreover a function solve() is called 8 times for every query.
If you really need this temporary variable, you can use a const reference:
Thanks a lot caustique for helping me .
I always skip problem C. Every contest, If I can not come up with solution as soon as I read problem C then I used to skip it. Then I would solve the next problem D. Educational Codeforces Round 169 is one example. I skipped D, then solved E. And in the EPIC Institute of Technology Round August 2024 (Div. 1 + Div. 2), I skipped C, then solved E. After contest, I was disappointed that I did not solve C. Could anyone explain me about this? I can not sure the reason.
For G, how do you get the digit you placed in the last odd block if in your transition you put a dummy state c=0? Thanks!
I was thinking of it like that. If you are in a state with $$$c > 0$$$, you are always placing the next (the $$$i$$$-th) digit into an even block. And you always add $$$c$$$ to the answer with that. You can opt to go to $$$\mathit{dp}[i + 1][0]$$$, telling the $$$(i + 1)$$$-st digit to be in an odd block. With that, you'll know that digit when you are in that state.
Ohhhhh I see thanks!
so slow
Idiot me, who wrote 500 lines of code in D :] 276672729
Honestly, only your effort deserves accepted.
Can anyone please correct my code for D ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~` void solve() { int n, m; cin >> n >> m; vector v(n+1);
for(int i = 1; i <=n; i++) { cin >> v[i]; } while (m--) { int a, b; cin >> a >> b; if (v[a][0] == v[b][0] || v[a][1] == v[b][1] || v[a][1] == v[b][0] || v[a][0] == v[b][1]) { cout << abs(a - b) << endl; } else { int pos = -1; int pos2 = -1; int ans = INT_MAX, ans2 = INT_MAX; int maxi=max(a,b); int mini=min(a,b); for(int i = 1; i< maxi; i++) { if(v[i][0] == v[maxi][0] || v[i][1] == v[maxi][1] || v[i][1] == v[maxi][0] || v[i][0] == v[maxi][1]) { pos = i; } } for(int i = maxi + 1; i <=n; i++) { if(v[i][0] == v[mini][0] || v[i][1] == v[mini][1] || v[i][1] == v[mini][0] || v[i][0] == v[mini][1]) { pos2 = i; break; } } if(pos != -1) { ans = abs(maxi - pos)+abs(pos-mini); } if(pos2 != -1) { ans2 = abs(mini - pos2)+abs(pos2-maxi); } int final_ans = min(ans, ans2); if(final_ans != INT_MAX) { cout << final_ans << endl; } else { cout << -1 << endl; } } }} ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~`
Can someone please tell what am i missing in this D problem :- 276639203. This got WA .
But this got AC :- 276654708
Could you please tell what is the difference
You can see the difference yourself using built-in "Compare" tool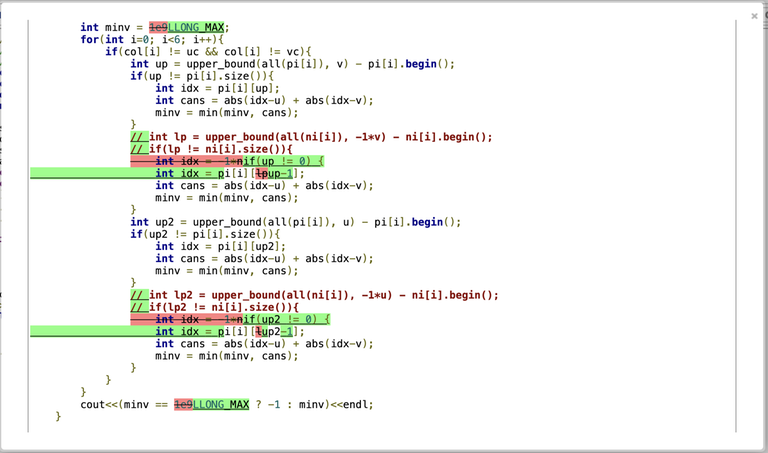
nvm, i got it .
Can some1 please help me understand why this won't work for prob C??
https://codeforces.net/contest/2004/submission/276886399
In your code inside accumulate function you are declaring 0 as L i.e Long int but for large values you must declare it as 0LL i.e Long Long, rest everything is correct.
Link for corrected code: Solution
So I lost ranks due to a single chars :sob::sob::sob:
It happens; the same has happened with me many times
Can anyone explain editorial of e , i read it many times still i didn't get approach , i understand concept of nim problem because there are alot of editorial are exists already but i'm not getting approach of this problem can anyone explain please ??? thanks
F. Can you tell me in more detail what what the line means: ans -= (s % 2 == 1 || !binary_search(p.begin(), p.end(), s / 2)); As far as I understand, this is a check for a palindrome of odd length. But why there are two checks here is not quite clear.
If S is not specifically determined to be odd, then S/2 will automatically be rounded down, which may cause some problems.
In problem E tutorial's induction proof, author writes "if x is a composite prime number", this should be corrected to "if x is an odd composite number".
Great explanation otherwise :)
https://codeforces.net/contest/2004/submission/276672351
this solution is O(n+q) but still gave TLE just because I was using python
I had some trouble grasping that the solution for F actually worked (going in increasing order through sizes of segments) because I thought you could end up counting disjoint segments. But all the elements being non-negative makes that impossible, that is, all arrays with equal p[l] + p[r] are one inside of the other.
can someone pls explain the idea behind D solution once again
Who can tell me why, in problem F, when the sample input is 1 2 3 4 4, the result is 18 instead of 15?
can anyone help me with D,I failed in the test 2 2651th number for lots of times:#277004006
Good problems!
can we get hidden testcases like we can get in cses problemset
where is my code getting wrong for problem D? Link to submission
based totally on tutorial idea
UPDATE:- ok, got the problem, it is giving -1 for this test case:
answer should be 5, my bad :(
please help me with this 277073432 it will be very helpful
Use
V<int> &ds = mp[temp[i]]instead ofV<int> ds = mp[temp[i]]at Line 98 to avoid copy.can you please provide some reason for this it will be very helpful for me in future cases
Nevermind, All this time in problem F, I thought we're asked to form a "PERMUTATION" NOT PALINDROME
I'm very curious why my code with primitive array in java 8 should get timelimit in 21 tests int a []. But the same code with Integer a[] should pass all tests and should be accepted the same logic. Can someone explain me why is that in java solutions.
In Java 13 and earlier versions,
Arrays.sortfor primitive types doesn't guarantee $$$O(n\log n)$$$. You can refer to this and this.Sorry, I am dumb in F what does the ans minus two values represent?
I tried all source shortest path (Floyd-Warshall) in D and apparently got tle. There have been many problems that I tried to solve with the algorithm yet failed again and again at the time limit. Can anyone tell me better approach to solve problems like these? (and also if there is a faster variant of the algorithm)
It will TLE. There is no cutting corner around Floyd-Warshall that would help you, the algorithm is doing its best (sort of, this is excluding any research paper improving it to an extreme, but as far as I understand, this cannot have a better complexity than quadratic).
D is more of an exercise to practice implicit graph. That is, you know what you are solving is a graph, but it has special attributes that you should take advantages of instead of blindly jumping into a regular graph algorithm just because you deduce "shortest path" from the problem statements.
What are the other implicit graphs properties are like? I think this codechef problem has also graph/tree like properties yet still my methods leads to tle.
Yes, your example is one out of many incidents. The vague term "implicit graph" simply implies a graph by concept and formulaic constraints — there is no fixed algorithm to solve them all since each constraints would leave different observations/loopholes that contestants must figure out.
Why algorithm described in solution for F problem is optimal? function f(l, r) is defined as minimum operations required to make a palindrome from a[l..r]. there's no proof in solution. can you explain it plz BledDest?
In the tutorial for problem E (Not a Nim Problem), the last paragraph says "if x is a composite prime number...", is this probably a typo? I think it would be correct to write "if x is an odd composite number..."
upd: I saw such a comment with such content, I apologize
Hello guys! Can someone tell me if it was possible to solve D using a graph + Dijkstra's algorithm? For some reason I have some problems)
From eq(1) and eq(2) it is clear that z can be either close to x or close to y and it should not matter. I don't understand how is D being solved.
~~~~~~~~~~~~~~
include <bits/stdc++.h>
using namespace std;
define ll long long
define pb push_back
define MOD1 1000000007
define MOD2 998244353
define NO cout << "NO" << endl
define YES cout << "YES" << endl
ll expo(ll a, ll b, ll mod) {ll res = 1; while (b > 0) {if (b & 1)res = (res * a) % mod; a = (a * a) % mod; b = b >> 1;} return res;} ll mminvprime(ll a, ll b) {return expo(a, b — 2, b);} ll mod_add(ll a, ll b, ll m) {a = a % m; b = b % m; return (((a + b) % m) + m) % m;} ll mod_mul(ll a, ll b, ll m) {a = a % m; b = b % m; return (((a * b) % m) + m) % m;} ll mod_sub(ll a, ll b, ll m) {a = a % m; b = b % m; return (((a — b) % m) + m) % m;} ll mod_div(ll a, ll b, ll m) {a = a % m; b = b % m; return (mod_mul(a, mminvprime(b, m), m) + m) % m;} void print(vector &ans){for(auto x: ans) cout<<x<<" "; cout<<endl;} void input(vector &v,int n){for(int i=0;i<n;i++){int e;cin>>e;v.pb(e);}} //===========================================================================================
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~```
void solve(vector &a,int n,int k){ sort(a.begin(),a.end(),greater<>()); ll i=1; while(i<n && k>0){ a[i]+=min(a[i-1]-a[i],k); k-=min(a[i-1]-a[i],k); i+=2; } ll alice=0,bob=0; for(int i=0;i<n;i++){ if(i%2==0){ alice+=a[i]; } else bob+=a[i]; } cout<<(alice-bob)<<endl;
}
int main(){ int T;cin>>T;
while(T--){ int n,k;cin>>n>>k; vector<int> a; input(a,n); solve(a,n,k); }}
Can someone please point out the mistake in my code?
Hello, can someone tell me in f, why the ans should do ans -= (s % 2 == 1 || !binary_search(p.begin(), p.end(), s / 2)); ?? Thanks!
Hey guys, I don't know why my solution for C got TLE. Can anyone tell me where it went wrong? Thank you ^^
Avoid using custom comparator function, instead using inbuilt greater () function to sort the array in descending order, as:
The use of a custom comparator function introduces additional overhead due to function calls, which becomes significant when sorting large arrays. On the other hand, greater() is a highly optimized standard library component that avoids this overhead, leading to better performance and preventing TLE (Time Limit Exceeded) in competitive programming or performance-critical applications.
In most cases, prefer using standard library comparators like greater() for better performance unless you need custom behavior that can’t be achieved otherwise.
link for corrected solution: https://codeforces.net/contest/2004/submission/277758988
ahh I didnt know that, thank you so much ^^
You're welcome! Glad I could help!
Same problem: TLE 9 in 280240613 I'm using built-in qsort and have no idea how to speed this code up...
// This is Code ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
746211
Did anyone try to solve D with using BFS?
278709370 can someone pls help me why my code always gets wrong answer at test 422
can anyone find the issue with this Code for the Problem D?
problem B was beautiful