

Всем привет!
Второй раунд соревнования MemSQL Start[c]UP 2.0 состоится уже сегодня, 10-ого Августа в 21:00 MSK. Одновременно будет два контеста: для тех, кто участвует онсайт, и для тех, кто участвует онлайн. Набор задач в двух контестах будет одинаковый, и за них будет начислен рейтинг на основе общего монитора.
Участники, участвующие в онсайт раунде, получат специальные призы за первые три места. Все участники онсайт раунда и топ 100 участников из онлайн раунда получат специальные футболки start[c]up.
Участники, не прошедшие во второй раунд, могут участвовать неофициально. При этом раунд будет рейтинговым для таких участников.
На соревновании будет предложено шесть задач, длительность соревнования -- три часа. Распределение баллов 1000-1000-1500-2000-2500-3000.
Удачи и отличного кодинга!
UPDATE: результаты будут опубликованы позже







Первая задача действительно будет стоить всего 100 баллов, или?..
Какое было последнее проходное место на онсайт, если смотреть по общему монитору контеста? В анонсе соревнований было сказано о 25 местах в онсайт-раунде, сейчас там 42 зарегистрированных участника. Было принято решение взять всех желающих?
В английской версии написано
Кстати, мне до сих пор не пришло уведомление о раунде по электронной почте.
Письма были разосланы топ-500 раунда 1 + первому дивизиону.
А как же мы, серо-зелено-синие? Наибольшая аудитория КФ...
Я прошел в топ500, но не могу зарегистрироваться в MemSQL Start[c]UP 2.0 — Round 2, в котором сейчас 41 участник, нормально ли это?
Видимо нужно регистрироваться на Онлайн-трансляцию
на он-сайт соревнование регистрируются только те, кто находится географически в Кремниевой Долине. На онлайн трансляцию регистрируются все остальные. Те кто пропал в топ500 пишут его "в конкурсе".
Радует что теперь две А-шки, а не Е-шки. Мб решу больше задач =)
По очкам, скорее 2 В-шки.
это как???
1000-1000-1500-2000-2500-3000
Имеется ввиду, что B-шки обычно 1000 стоят. Ну вот здесь 2 по 1000.
В анонсе первого раунда говорилось, что второй раунд будет сложнее обычного раунда Codeforces, так что возможно это две C-шки (или A-шки div1). И это даже логичнее: две A, B, C, D, E (div1).
Но тогда сложнее обычного раунда только наличием дополнительной A... Вряд ли это будет так, возможно что: две B, C, D, E и супер задача (div1).
Простите читать разучился.
"Since you are not in the top-500 of MemSQL start[c]up Round 1, your participation in Round2 will be marked as out-of-competition. However, the round will be RATED for you. Please be advised that this problemset is not designed for Div2 participants, and you might end up with zero problems, which will result in a significant loss of rating. Are you sure you want to register for the round?"
Awesome Warning :D
Forget what I have written before. Something strange has happend with me. xD
Congratulations!
Good for you :)
Clap clap! clap for him :D
Proved true! :(
Yay , I did not played :D
should have followed that :(
The time of this round is too late.I like Chinese round.But I'd like to take part in this round. (●′ω`●)
So, I plan to go to bed at 7 p.m., and wake up at 0:30 a.m..
It's a good idea.
In my country, the contest was held from 0AM to 3AM (Aug 11). Despite having to go to school at 6AM, I still participate :)
me too,It's very sleepy for me to participate..
At least, It was a great round for tourist. He broke another record. (Rating 3260)
100, значит...
Кстати, можно ведь сделать какую-нибудь такую задачу с символической стоимостью — и акцентом на взломы)
для всех русскоязычных 100, для остальных 1000 :)
Санкции.
Может быть это потому, что условие для задачи будет только на русском. Ну а что, я вон с гугл-переводчиком решал гугл код джам и фейсбук хакер кап.
The only way I can solve a problem is if it is math. So.. hope for math!
The only way I can solve a problem is if it is math.. so lets hope for math!
do you have to be respectfully reminded again that this is not IMO.
What if I tell you that all the problems here are about math?
Being pure math [which he refers to] is not equivalent to being about math.
In other words, your definition of "about math" cannot be correlated with his definition of "math".
Sorry I thought this was IMO webpage.
Yes, I thought so.
Well, A was math and because of this I managed a +111! I think i'll be posting "lets hope for math" more often!
I think i'll be posting "let's not hope for math more often".
D was math too. Why didn't you solve it?
Because it is D :(
are you fu**ing kidding me again??!
The only difference between official and unofficial participation is that TOP100 receive T-shirts :P?
hmm, good point. i wonder if unofficial participants who finish in top 100 will receive a T-shirt or not.
Last year I finished 19th and received nothing, because didn't participate in the first round.
tourist win the online round last year, but he couldn't receive anything
If so, then there won't be absolutely any difference between them :P.
Yeah. Unofficial participants cannot receive T-shirts, no matter how good their results are :P
Note : Problems not designed for Div.2, so have very people out of competition (Link)
umm, but the post says that the contest will be rated even for unofficial participants.
But the post not this.Are you sure?
А с чем связано столь малое количество участников на онлайн трансляции? Вероятно, многие думают, что те, кто не писал первый раунд, не могут писать второй раунд.
Возможно, потому что сообщения не разослали им?
Всех честно предупреждают о сложности раунда для Div2 участников. Пока что число зарегистрировавшихся вполне типично для Div1 раунда.
Можно ведь зарегистрироваться, почитать задачи, а потом уже по ходу дела видно будет: стоит сабмитить что-то или нет.
По моему для участников Див2 наоборот есть мотивация писать такие контесты. Во-первых ты можешь попробовать свои силы среде первого дивизиона, а во-вторых, мб какой-то фиолетовый (по типу меня) завалится на более-менее изи задаче и есть шанс неплохо подняться за счет таких фейло-провтыкавших раунд.
Прям как я умудрился поднять рейтинг в первом раунде этого соревнования на целых 6 единиц. Хотя, решив всего 2 задачи, я думал что вот — сейчас опять в див2 вернусь.
я 219 поднял с первого.
Ну так у тебя и изначально меньше было =) У меня изменение с 1802 до 1808, а у тебя с 1517 до 1736.
Сегодня что-нибудь сабмитнуть для некоторых участников было выгодней, чем не отсылать вообще ничего: для superhy, Kenneth-nlogn, Al_Helal_ и многих других результаты довольно позитивные:)
Сегодня были такие задачи, что даже если хочешь сабмитить — не всегда есть что:)
В прошлом году тоже было не густо: MemSQL start[c]up Round 2 — онлайн-версия — 1225 зарегистрированных участников, если верить списку соревнований.
Offtop: кто-то знает, как можно посмотреть число участников в таблице, если меня интересуют внеконкурсные, но не интересуют виртуальные? Хочу узнать, сколько участников тогда что-нибудь сабмитили, с включенным отображением внеконкурсных — видно и виртуальных, с выключенным — пропадают внеконкурсные, которые не писали/не прошли первый раунд.
В прошлом году и задачи были менее дружелюбны.
Good Luck :)
Round 1 -> 3700 registrants
Round 2 -> 1800 registrants
It seems that the warning for hard problems is very scary and effective!
b.... it's because today in chine is ghost day. and it's begin in 1:00 to 4:00. so many people already sleep yet,like me haha...
You are wrong : Round 2 : Total: 1826 Contestants: 368 Out of competition: 1458 have only 368 contestants
Интересно, хоть одна задача у меня зайдет сегодня?
so sad..... can't understand what B said... so b.......
thanks to Google translation....
don't you go to sleep... today i will translate in baidu translation... sad
I think if I go to bed now, I won't wake up after 2 hours... And I will miss an important date.
…clock
Я многое сегодня понял о жизни
Прикольные задачи, попробую потом С дорешать. Какая-то у нее сложная техническая реализация:(
Тернарка по максимальному количеству голосов у соперников — строк 40. Старый баян с usaco.
воу-воу, палехче
А как доказать, что эта функция выпуклая?
Я шел линейным проходом по убыванию по максимальному количеству голосов у соперников, а остальные величины считал с помощью очереди с приоритетами и двух деревьев Фенвика.
>баян с usaco
>доказывать
))))))))))))))))
А вообще, надо подумать :)
Legitimate warning . couldn't solve one !! and more sad is that , there will be no editorial !! :( :(
We will publish both editorials.
When?
when?
When?
Как А нормально делать?
Нормализовать каждое число так, чтобы не было двух единиц подряд. Формулы: 11 = 100, 200 = 1001.
А как это просто сделать не за квадрат?
Я держал список позиций, которые ещё не обработаны, и по мере обработки добавлял новые позиции, если в них нарушалось условие нормальности. Сложность этого O(n+количество применений формул), правда, как оценить количество применений формул, я не знаю.
Наверное, количество применений формул будет порядка количества единиц в строке, так что сложность решения будет линейная.
Вроде бы можно делать нормализацию от старших разрядов к младшим. Тогда в префиксе никогда не будет двух единиц подряд после полного шага нормализации. Если после очередного шага нормализации получается две единицы подряд — пройдемся по хвосту префикса, нормализируя его. Поскольку каждый такой "шаг назад" уменьшает число единиц, то понятно, что их общее число будет линейным.
Наивно. Бежать от старших разрядов к младшим, при виде двух единичек прокидывать вверх и проверять там. Квадрата на самом деле не будет из-за большого количества нулей. Или, например, потому что каждая такая операция уменьшает количество единиц в числе.
Пройдет ли такой тест?
Да, конечно. Проверять там имелось в виду, что там вы тоже увидите две единички подряд, опять прокинете и опять проверите ещё выше. После этого вы уже никогда не пройдётесь по этому месту, ибо оно заполнится нулями.
А я как-то догадался, что
q^2 = q + 1умножить наqи тогдаq^3 = q^2 + q, то есть100 = 11,1000 = 110,10000 = 1100и т.д. Таким образом можно заключить все единицы в первых двух разрядах и потом сравнить... но сравнивать их считая значение в dooble не очень умная мысль, так как меня взломали...110011001100110011
Как все свести к первым разрядам?
110011001100110011 = 21011001100110011 = 3211001100110011 = 541001100110011 = 96001100110011 = '15'901100110011 = '24'15'1100110011 = '39'25'100110011 = '64'40'00110011 = '104'64'0110011 = '168'104'110011 = '272'169'10011 = '441'273'0011 = '714'441'011 = '1155'714'11 = '1869'1156'1 = '3025'1870' = 3025 * q + 1870. Но у этого решения есть небольшой минус... оно переполняется...
Я должен поставить Вам плюсик просто потому что Вы не поленились всё это расписать.
Просто qn = qFn + Fn - 1, логично, что числа Фибоначчи при достаточно больших n не вместятся в 64-битный целочисленный тип.
Так как q2 = q + 1, то qi = qi - 1 + qi - 2. Тогда пусть мы стоим сейчас на n-ом бите, тогда от a[n], b[n] отнимем min(a[n], b[n]) (так как они сократятся). И тогда заметим что a[n - 1] + = a[n] и a[n - 2] + = a[n], b[n - 1] + = b[n] и b[n - 2] + = b[n]. И в конце останется a[0], a[1], b[0], b[1] их просто сравниваем и все.
В таком случае, что делать, если какой-то из элементов массива a или b перестанет вмещаться в 64-битный целочисленный тип? Такое ведь теоретически может произойти?
Тогда будет больше та строка у которой переполнение.
Почему?
потому что сумма всех элементов от 0 до n не превышает удвоенный (n+1)-ый элемент. если в каком-то разряде разница 2 или более, можно сразу выводить ответ.
Пробовал сравнивать цифры порядков начиная с наибольшего (идя слева): если в наивысшем порядке цифра больше, то первое число выходит в лидеры на два параметра, если следуещая тоже больше, то значения параметров достигают критическую величину и первое число побеждает (являеться большим), а если следуещее меньше, то один параметр уменьшается, а если и третия цифра меньше, то и второй параметр уменьшается — тогда числа "выравниваються"...
Сейчас реализовал таким кодом — 7426874. Счетчики f и g. Если f переполняеться (abs(f)>1), то вывожу ответ. И оба счетчика немогут в одно время быть разных знаков.
Кстати, нашел что можно два раза пройти по строке (справа налево) ее изменяя, и в итоге оставить ее без соседних единичек: 1) один раз проходим меняя подстроки такова типа
"0" + "10" x N + "11", (N >= 0)на подстроки"1" + "0" x (N+1)*2, 2) второй раз проходим меняя подстроки"0" + "11" x N, (N >= 1)на подстроки"10" x N + "0". Решение на Perl — 7427468в С умею решать задачу(потратьте наименьшее колво денег если вы хотите чтоб за вас голосовало X человек), как найти оптимальный X?
и еще как Б решать?
решение Б как у туриста. немного успокаивает xD
Перебрать:)
Например, тернарным поиском. Другой вариант -- зная ответ для одного X можно за константу пересчитать для X + 1.
В C есть решение проще декартячки?
Я писал тернарник. Правда, неуверен, зайдет ли.
Я решал на set'ах + ДО. Типа храним в ДО всех избирателей, которых ещё не подкупили. После этого перебираем сверху вниз количество избирателей, которое мы не хотим видеть у конкурентов. "Срезаем" лишних избирателей у них, удаляя из ДО. Потом если нам не хватает избирателей, добираем нужную сумму из ДО.
Пока систесты не прошло, правильность не гарантирую.
А в ДО типа засчет того что удаляем что-то просто не у каждой вершины степень двойки детей?
Удаляем — значит, в вершине, соответствующей x-ому элементу поддерживаем количество элементов со стоимостью х и их суммарную стоимость. Когда удаляем, уменьшаем счётчик и сумму.
У меня решение с массивами и сортировками. Сложность , причём основной цикл (перебор нужного количества голосов) за O(n).
, причём основной цикл (перебор нужного количества голосов) за O(n).
Основная идея — отсортировать всех людей по стоимости, и составить общий список и список для каждого кандидата. В основном цикле люди перекладываются между двумя стеками — те, кого мы подкупили ради увеличения своих голосов (а не уменьшения голосов соперников), и все остальные.
А можно поподробнее начиная с основного цикла ? что и как мы перекладываем? какая разница между теми кого мы подкупили ради своих голосов, или ради уменьшения голосов соперника?
В моём решении перебирается максимальное количество голосов соперников в порядке убывания. В первую очередь подкупаются самые дешёвые люди у тех соперников, у кого голосов слишком много. Потом, если своих голосов не хватает, подкупаются самые дешёвые люди из оставшихся. Чтобы это быстро пересчитывать, люди хранятся в двух стеках, отсортированных по цене (один по возрастанию, другой по убыванию, причём перекладывание между стеками сохраняет сортировку). При попытке подкупить человека по одной из причин (или, наоборот, отказаться от подкупа) нужно проверить, не подкуплен ли он по другой из причин, и действовать соответственно.
Если всё равно непонятно, можешь посмотреть моё решение 7417483.
awefully hard contest :(
btw I dont know the point of giving 6th problem when no one can solve that, I feel like that one problem is being wasted which could be used in other rounds ?
ACrush had 3 wrong submissions on 6th problem. Another day, may be, he could have solved it :)
And its called "An easy tree problem"
Что такое "Неизвестный вердикт" во взломах?
Кстати, как по-нормальному ломать людей, использующих Arrays.sort() на Java? Тест слишком большой, генератор довольно долго работает. Может, добавить возможность загружать заgzip'ленный тест?
Это, видимо, особенность Codeforces. У нас есть одно из решений (не основное) на Java, и оно падало на твоем тесте. Почему-то падение не основного, но помеченного правильным, решения приводит к Unknown Verdict, отписал Мише про проблему.
Может не надо? Пожалуйста...
Надо, Федя, надо
Логично сделать такой вердикт, чтобы он у жюри высветился как можно скорее. Если решение, помеченное правильным, не работает на взломе, это нештатная ситуация, и без человеческого вмешательства не обойтись.
В хорошем случае это решение и не должно работать на этом взломе — тогда его можно просто перепометить как неправильное.
Но мог случиться какой-нибудь плохой случай: например, ошибка в валидаторе, позволившая ввести некорректный взлом — тогда нужно что-то срочно исправить.
Иногда эти особенности сводят с ума, когда qsort на С++ НЕПРАВИЛЬНО сортирует массив (sort'ом обычным решается), и когда swap в контейнере работает неправильно. Приходится неспортивно лезть в тесты
Казалось бы, названное — это особенности C++, а не Codeforces.
Не-а, в визуал студии один вывод, в "запуске" кф другой вывод
Для более предметного обсуждения, пожалуйста, дайте ссылки на посылки с указанными выше проблемами.
Когда происходит такое, то не надо первым делом грешить на компилятор или стандартную библиотеку. Чаще всего виноват сам код, который где-то вызывает неопределённое поведение или не соблюдает требования (например, функция-компаратор для
qsort()сравнивает элементы неправильно).Забыл сказать, что вообще идея ломать Array.sort кажется мне не спортивной :о) Но это тема отдельного обсуждения.
Ну тогда надо давать отсортированный input :) Я решил, что раз уж мне пришлось считать хеш input'а и использовать его как rand-seed для random_shuffle, то я имею моральное право почелленджить этим.
Да, я тоже считаю не спортивно :( Тем более, что взломали меня :(
Хм, а между тем, мой второй взлом неуспешен, т.к. человек предусмотрительно использовал Integer[] вместо int[]. Оказывается, в отличие от Arrays.sort(int[]) (который просто qsort, и может работать за квадрат), Arrays.sort(Object[]) — это Timsort, если верить википедии, он работает за O(n log n).
Остаётся только гадать, какими веществами упарывались разработчики java, сделав нормальную сортировку для объектов, и квадратичную — для примитивных типов... Означает ли это, что Collections.sort() всегда безопасен?
Ну это вообще грусть :'( Зачем так делать... Даже авторы это не ломали.
Qsort быстр на реальных данных и для примитивов является stable.
Тут вопрос возникает почему вместо qsort не используют introsort.
А Collections.sort(), судя по исходникам, вызывает Arrays.sort(), поэтому безопасен.
На stackoverflow есть некоторое обоснование (вещества не упоминаются).
Collections.sort()гарантировано NlogN и stable на сколько я понимаю, но не гарантировано Timsort(в частности, раньше был merge sort)Сортировка объектов в Java стабильная, поэтому там используется MergeSort или TimSort. Для примитивных типов любая сортировка будет стабильной, поэтому в качестве оптимизации можно сортировать с помощью quicksort за квадрат.
Было бы неплохо научить CHelper выдавать warning, если в коде присутствует вызов Arrays.sort() с массивом примитивов.
Problem B may have a greedy solution... Many people have passed the pretests, but I haven't. So sad Can you tell me any idea? :(
mine: consider to construct all pairs between the most heavy i nodes from side A to all nodes from side B (cost: total of side B * i) and construct single pair from every other m-i lightest nodes from side A to any heavy nodes from side A (cost = m-i), choose the best i. Reverse for side B.
But tourist hacked a lot on B, so it may have no greedy solution :)
I guess those hacks were about integer overflow, not algorithm. The greedy solution is very easy to prove!
The system test will tell us the truth
Results of intermediate calculations may overflow long long — one can receive ~(10^5)*(10^5)*(10^9). This number is bigger than 2^63, and it was easiest and most common way to hack B today.
Note however that the calculations (up to 1019) fit into unsigned 64-bit integer.
So, does it need to use biginteger in java?
One can use unsigned long long, as Gassa mentioned, or do some safe multiplication — if result is larger than some constant (1e18 for example) — return that constant. Actual answer is always not so big, so you may just don't care about these possibilities — is does not matter if it gives result of 1e18 or 1e19, if you know that answer will be <1e17:)
And safe multiplication can be done this way:
Hope this test has been already included in system tests.
Oh no :( didn't notice that
Edit: I think my solution won't have this problem. (maybe?) If the light partition is smaller than the sum of the other side, copy it to the heaviest partition. Or copy all rows in the other side to it. This may guarentee the answer smaller than 2e14.
I agree.
There was a problem. In one of the solutions overflow can happen (even for long long (10^5*10^5*10^9)). A lot of solutions were hacked because of that.
I think this kind of situations should be avoided by the authors. It is really annoying to have a good solution and fail because of that.
It is generally expected that the person who solves the problem is responsible for avoiding integer overflows in his solutions :)
Thanks. Lesson learned...
And congrats for the round ! I liked alot C.
The integer overflows made me lose a T-shirt... I will remember it very well
Forgot string.length() is unsigned, so can't go negative...cost me 500 points lol
Дайте мне этот гребаный 8 тест к задаче А! извините за эмоции Как вы ее решали? Я тупо перебирал первую и вторую строку, находил в позициях i и i+1 единицу, и в позиции i-1 единицу во второй строке и обнулял их (100=011), затем итоговое сравнение двоичного числа.
Если банально идти по строке слева направо, то эта нормализация будет работать не до конца — после того, как заменили пару соседних единиц, может образоваться новая пара, которую мы пропустим. Например, 101011->101100->110000->1000000. Решения, которые делали только первую замену, падали на 8 претесте.
Ага.. Наверное, я велосипедист. Придумал, блин, преобразовывать строки удалением 1010001 и 1001101 = 1000001 и 1000001 А все так просто :(
Тогда, естественно, идти по строке надо не слева направо, а справо налево, с конца
В таком случае нужно будет еще придумать, что делать с двойками)
Если будет больше двух единиц подряд, то последние две при превращении сделают из третьей из конца единицы двойку:) Это, конечно, можно разрулить, если использовать какие-то еще свойства чисел Фибоначчи:) Но если идти слева направо — таких проблем не визникает.
Да блин) Тогда уж после превращения в цикле откатываем i до индекса последнего нуля плюс один/начала, если нулей не было. Спасибо
Тогда цифры могут стать отличными от 0 и 1, и непонятно, как правильно сравнивать полученные числа.
я выше уже написал: значения надо сокращать, и если появляется ситуация, когда в одном числе в разряде 0, а в другом 2 или более, то то число где 2 или больше заведомо больше.
When can I expect system testing to start?
I forget to judge the answer of D with 1e99............TAT....what a sad story!
Wow I found that my Chinese name pronounced the same as yours. XD
How delayed will the results be? What I want to know is, should I wait or sleep?
It can take another hour or may be longer, so sleep might be a better option.
is it done because onsite participants can be surprised by the results (like in ACM-ICPC)?
i'm asking this because i noticed that access to /contest/457 (the onsite round) has been temporarily blocked.
Seems like I didn't take your advice!!! Now the question is, do I wait for rating update too.
Привет Div2. Я так скучал по тебе вместе со своими переполнением в А и глупой логической ошибкой в Б.
Finally, testing has started.
It's not really fair when one got only 4 participants in the room who's rating is less than 1900, and when there are more than a half of div2 participants in another room at the same time.
Не выиграл футболку из-за того из-за того, что обнулял по массивы до N а не до 100000 :(
кто-нибудь объясните почему так происходит!
Ссылка
Вердикт — ТЛ, но там написано вывод 844, что является правильным ответом!
Или вывод это ожидаемый от вашей программы ответ, или что-то поломалось.
Обычно вывод — это как раз ответ участника, вроде бы.
это походу баг какой-то. вот вывожу принтфом и все норм(не выводит ничего)
Ссылка
Да, точно. Видно, фантастический случай из разряда "программа успела вывести ответ, но не успела завершиться".
Там для 200к векторов вызываются деструкторы и освобождается память. Это конечно не особо долго, но чтобы вывести ответ и не успеть завершиться, хватает и без фантастичности.
Не выиграл футболку, потому что в задаче B неверно вызвал сортировку массива b[]. Печаль...
Не только футболку потерял, но и ещё один шанс получить красный цвет упустил:(
Да станешь ты красным, чего переживать-то?
Спасибо) Кстати, поздравляю с новым званием:)
Спасибо, но это ненадолго)
Как же я тебя понимаю(
Does the t-shirt prize apply to all participants or only to the ones that have qualified to this round ?
"only to the ones that have qualified to this round"
Не выиграл футболку, потому что нуб
Any information on when will rating update happen?
I just get rank 90 in this round, but i failed in the last round by getting rank 509.
OH!! WHAT A PITY! :(
leave me alone.
I will count the prime number until i find the new Mersenne prime. :(
Petr solution of problem B become TLE because he uses primitive data type array instead of wrapper class Integer array. Same happened to Egor too or any user who submitted his/her solution using primitive data type. So unlucky:(
I don't get it, maybe because I'm not fluent in java. It looks like O(n) and it's safe against overflow, what's the problem?
Actually Arrays.sort() in java uses quicksort algorithm when uses on primitive data type but use O(nlogn) timsort for Object. It has nothing to do with their algorithm.
Quicksort is O(nlogn), you mean it doesn't use O(n) radix/counting sort? Ok, but plenty of solutions used sort and passed under 100ms. I still don't get the problem.
Unless you mean it literally uses plain quicksort with worst-case time O(n^2), but I would be doubly amazed if that's the case (the library being that bad, and Petr not knowing that).
Quicksort is O(n^2) in worst case and Codeforces seems to have anti-quicksort test for Java-implemented quicksort
It does perform O(nlogn) on many data sets but some special data set which increases randomisation overhead ,it becomes O(n^2) as it implemented in java library. It has happened previously, you can see here long comment
I met a problem yesterday.
I use a data structure called treap, which is a binary search tree with a expected depth O(logn), to solve 455D. Its depth is determined by a random process similar to quicksort. And then I got TLE by purely assigned rand() to each node's priority. The code is here: 7409879 (change the seed by srand didn't help.)
Then I change the priority to rand()*(RAND_MAX+1)*rand() and got AC. But I thought it didn't make sense because 10^5 is not very large in comparison with RAND_MAX, so I tried rand()+rand()%2 and still got AC in 300ms, while the time limit is 4s.
I still don't know why, maybe this is a similar issue?
and what if you change rand seed?
7409899 7409907
Oh, interesting, I don't understand how adding rand() % 2 may help. And it's even consistent between compilers. So, it's hardly an optimizer bug
Even this code got AC by generating a random number and doing nothing with it after each construction. 7410439 However this code got TLE if I only generate one random number after every two construction: 7410459
Possibly the test case uses some property of rand() which doesn't depend on the seed. If the function isn't rand(), there's no problem.
Hmm, I think this is the best possible explanation.
Oh wait, I think the shape of the largest bst is only related to the input size, and the size of other bst is not too big if the test case is uniformly distributed...
It seems that Codeforces' version of GCC has not so big
RAND_MAX.http://codeforces.net/contest/455/submission/7423378
Yeah I've tested this in custom invocation, but I thought it is large enough. May be I was wrong. :(
So if you have issues with rand you can try new pseudo-random number generators implemented in C++11 like
mt19937orranlux24. Here is your code withranlux24_base. But surely they are rather slow in comparision with(rand() << 16) ^ rand().Surely (rand() << 16) ^ rand() is the best way to solve this problem, but I'm interested in why rand() was so slow. I thought testcase don't affect that much because the treap shape has nothing to do with key inside the node...
are u talking about the anti-quicksort test?
yes
Вывод: 1 Ответ: 0
.........................
I am really surprised at how this code got accepted: http://codeforces.net/contest/458/submission/7419996 look at the calc function return value at the end when it calls itself
EDIT: Sorry, i misunderstood.
This is undefined behavior, which, as we know, may do anything. This case shows that with some luck "anything" also includes "work correctly".
This probably works like this: when the function does return a value, it stores it in a specific register according to the calling convention, say, R1. When it returns without
return, R1 still has the value from the tail call and is interpreted as the return value from this invocation. So it magically works.Looks like compiler automatically returns tail recursion result?! Amazing but that strongly rely on the compiler, maybe on Codeforces it works but not always work.
FFFFFFFFFFUUUUUUUUUUUUU одна пересылка задачи А стоила мне 4 баллов которых не хватило до желтого минусуйте сколько хотите
Country wise ranking have been update. Easy to see how many of your country mates are getting Tshirts :)
SnapDragon got +51 rating increase for 2610 pts while Furko +152 for 2590 pts.
Last year rating was also calculated this way, separately for online and onsite contest:) Compare performance of Auster (MemSQL start[c]up Round 2 — online version, 1860 points, rating change 1988->2100) and zcg.cs60 (onsite contest, 1876 points, rating change 1927->1958). Comparing bottom part of standings — onsite contestants lost not so much rating like those who participated online; and in upper half we have opposite situation — they also gain less:)
i think this maybe because SnapDragon participated onsite, but Furko participated online.
Everybody in Ukraine knows that Furko is damned cunning :)
I got rank 111 in all participants, but rank 88 without unofficial. Will I get a t-shirt?
Luckily I am the same as you.Got rank 88 without unofficial.I think we will get t-shirt!
got AC in B now just by changing long long to unsigned long long what a pity
Unfortunately my rating decreased in all two rounds. So sad :(
but i can see only one round you participate in :/
in 457A - Golden System is the length of each string not larger than 100000? because when i use an array of 100003 numbers my solution got runtime error but i got AC after switch to an array of 200003 numbers.
So yes, the length of each string, not the sum of the lengths of the strings.
There's your problem.
fixed, thanks :)
Can someone explain problem C(elections)? I made each politician a vector, and sorted so that their cheapest voters are at the top. Then I found whether it is cheaper to get one bribe from the politician that has the most votes, or if it is cheaper to get two bribes from a politician that has less votes than you currently do, and to bribe either the one or the two people. You continue doing this until you win the election. I never could test this, as I ran out of time in the compiler but not on my computer. What was the correct solution?
1) Let's sort all votes (for other candidates) by their cost. Now we make a segment tree. Each node is a pair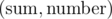 . To this tree we put each pair
. To this tree we put each pair 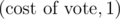 , cheapest on position 0, second cheapest on position 1 and so on.
, cheapest on position 0, second cheapest on position 1 and so on.
2) We make an array A of vectors, for each candidate there is a vector with costs of bribes. We sort each vector (by costs) and then the array (by number of votes). Let N be a number of candidates and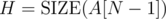 .
.
Ok, so these are data structures that we will use. Now the algorithm. Let's consider 2 cases:
We buy more than H votes. Then it really doesn't matter which votes we buy. So we just take H + 1 cheapest votes. To take this number we can use our segment tree.
We take X votes, where X ≤ H. First part: for each candidate with number of votes T, where T ≥ X we have to bribe some of them, at least T - X - 1. So for each such candidate we take this number of his cheapest votes. And here is the trick — we take these votes from vector associated with this candidate (take and remove from vector) and then we remove these votes from our segment tree. Second part: now each candidate has less than X votes, so we can proceed as we did in first case.
To make this algorithm fast we need the most important observation — it's easy to find a result for X - 1 when we found a result for X. We just take a cheapest vote from all candidates who have currently X - 1 votes, than we remove these votes from vectors and segment tree and we are done.
Let us decide on how many votes the runner party gets at the most. I will call it x. Let us say we know optimal x. Now we need to buy candidates from parties which have more than x voters. It is optimal to by least cost voters from each such party. At this point all parties have atmost x voters. We have initialCount + BribedNow number of voters. We need x+1 voters for our party. If we have enough, then we are done. If we do not have x+1 voters, say we are short by y voters. Now we need to bribe y more voters. This voters can be from any party, so we take the least cost voters irrespective of party. Done. We know how to solve for a given x. Now we need to loop over all x and find the best answer. Loop over x from 10^5 down to 0. Let us sort the voters of each party before hand. So now in each step we might bribe some voters from some parties. And calculate y (still needed voters), then we need to answer what is the sum of least y voters from left out voters. We need a data structure to answer this in log N time. I used BIT. one BIT keeps track of "active or not", another keeps track of respective sum. We binary search for first index such that number of active voters <= that index is greater than equal to y. Once we get the index we need the sum of active voters <= that index which we can get from another BIT. This seems bit confusing, but take a look at my code.. See how query, update operations are made. Also when we remove voters from each party (due to <=x condition) we make those voters inactive and reduce respective sum.
After looping over x from 0 to n-1 I noticed that the cost function is most likely convex and used ternary search, got AC.
submission for A with biginteger 7420935 without any normalization xD -
How to solve problem D?
Maybe not the easiest way to go, but still one.
Let S be the set of all rows and columns. We're asked to compute
exactly covered — no other rows and columns are covered.
Now I state it's the same as
(in this sum, we add a possibility that there are other covered rows/columns).
Why? Consider all the situations when set A gets exactly covered. How many times will it be counted in the second sum? Of course, it's counted (only) for sets B which are subsets of A. It means each such situation will be counted exactly 2|A| times. Now we'll focus on computing the second sum.
The second observation is obvious: let's say we choose r rows and c columns. Then the probability doesn't depend on which rows and columns we've chosen! It means we can compute all these situations at once:
Now it's easy. We've already chosen r rows and c columns and now ask how many are there ways to cover them. Let fr, c = N(r + c) - rc — the number of cells that make these rows and columns. Then we need to choose fr, c numbers from K correct numbers and distribute them in any way; then we choose remaining N2 - fr, c numbers from remaining M - fr, c ones and again distribute them in any way we want. And how many bingo boards are there? Of course we choose any N2 numbers from M and distribute in any way. This all gives us the sum
(where nPk are partial permutations, equal to ).
).
It's of course the final result, but we may change it into a fraction of products of factorials (it looks ugly, but it's easy to put into the program and compute). Also note the factorials in the fracions may be huge, so it's a better option to make the computation on their logarithms.
//Edit: the expanded equation is here:
Of course, if any of factorial arguments in the fraction is less than 0 (K - fr, c can be), the fraction is equal to 0 (because then KPfr, c = 0).
Great explanation, thanks!
after selecting r rows and c cols, there are
m-f(r,c)left, we still havek-f(r,c)to choose, the total choosing method isC(m,k), so we have:which results the same in another way.
Is there any tutorials for this ?
http://codeforces.net/contest/458/submission/7427428 here is my solution for problem c. When I want to get x votes, I get from everyone who has votes more than x. then if I still dont have x votes I pick the ones with lowest cost if they didnt get picked. And I assume that the the cost function f(x)(I want to get x votes. returns min cost) first increases and then decreases. So I binary search on it. I dont know if this is a true approach but I pass 53 test cases and get wrong answer on the 54th. Can you help?
If your assumption is true (f decreases and then increases) you have to do a ternary search instead of binary. Personally I've just calculated f for all possible x.
it is like a ternary search. I take 2 values x and x+1 and check if f(x) is > f(x+1). If so I search for the left side, otherwise the right side. I have also done it with ternary search with the same code above but it didnt work. It gave wrong answer again in the 54th test case.
what to do if f(x) == f(x+1)?
btw my messy ternary search solution passed http://codeforces.net/contest/458/submission/7418801
If the function is not strictly increasing/decreasing, then ternary search also fails, so I suppose you shouldn't worry about that.
I think f(x) should be non-increasing til some point and non-decreasing afterwards. So it may fail.
The function is actually convex, not just unimodal, so if f(x) == f(x+1) you're at a minimum anyway. Ternary search works.
Your ternary search may work, but problem is with this line (maybe on more places too)
for(int i=0;i<N;i++){ai < ndoesn't hold for test 54Oh you are right. Thank you so much. :D Got AC when I changed every N I saw to 100000 :D.
Here's a strong hint for problem E (my submission in the contest failed, but only due to missing a case).
Instead of thinking about this as network flow, think about it as electrical flow from source to sink. Bandwidth becomes current, weight becomes resistance, and cost becomes power. Electricity flows to minimise total power (principle of least action), so the current flows will be the solution to the intern's problem.
The standard way to solve current flow on a general graph (well, not quite this general), is to solve for the potential at each node, relative to some reference node. For each given link, you have the potential difference between the endpoints. The problem thus becomes to determine whether there is a set of potentials that is consistent with these differences, as well as enough extra links to make the network biconnected and satisfy the flow constraints.
May I ask you a question: why do you define your functions and global variables as static while there is only one file?
А когда будут наши футболочки?
ну в прошлом году, мне прислали, где то в районе 7 месяцев, после контеста.
give me '-' pls
Still no editorial neither to Round 1 nor Round 2?
Still no results of this round.
Прошу прощение это недорозумение. Писал это не я, скорее всего меня взломали. Этот аккаунт будет заброшен и сменен пароль.
Omg editorials pls?
My guess is that editorials will be published when someone solves F. :)
http://codeforces.net/contest/457/submission/7687485 So, it is a time to finally publish the editorial :)
omg still no editorial. People can't understand how to solve the questions they missed without a editorial; this is the importance of publishing one.
They can look at other peoples' submissions.
But they still can't understand how to solve problem F...
These are the advantages of editorials:
1) Time efficient [you don't have to go through submissions looking for a good one and then read the code];
2) Can present more than one way to solve a problem
3) Like qwerty said, can help people solve unsolved problems.