


I didn't receive an email for this round but it will happen in a few hours.
GL & HF.
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |
I didn't receive an email for this round but it will happen in a few hours.
GL & HF.







What common mistake was on A div1? My solution was hacked in a few seconds after challenge phase start :D
Suppose, that the common mistake was calculating length of the only one of the compared sequences.
That's not my case :)
2 of 4 targets failed it oO
I will never use Math.hypot in Java again!
I will never use Math.hypot in Java again!
I will never use Math.hypot in Java again!
I will never use Math.hypot in Java again!
I will never use Math.hypot in Java again!
Now just add it to a gif of Simpsons OP :D
UPD: here it is.
My teacher used to force us to write 100 times :(
What's wrong with it?
It works very slowly.
Wow
Did you check that scaling coefficient is the same for all segments?
I checked that two vectors are collinear and their length squared fraction is the same.
UPD. Code http://paste.ubuntu.com/8494300/
UPD2. This code is correct actually. See this comment :D
There are at least 2 possible reasons:
You compared fractions using floating-point arithmetic(and ran into precision issues).
If you compared them using multiplication of numerator and denominator, you could get overflow(length squared can be around 10^12, thus the product of such two numbers does not fit into long long).
After looking at your code it is clear that it failed because of the second reason.
But max rating was 5000, so x*y could not be greater than 5e9
Dates could be up to 10^6.
5e9 will overflow an integer (1e9 is roughly 2^30).
check this input :
date = {1 2 5 6 7}
rating = {1 2 5 6 7}
When your solution is wrong, just because forgot to click Load button in KawagiEdit, so I sent old version, which was totally wrong.
Gonna use another plugin, which would automatically generate testing code next time... Which one do you use?
UPD. I've edited the comment after I've got first reply. First reply is for rev. 1
Why not just use NoEdit?
I will check it, thanks!
Also try VanillaEdit
I couldn't find this in Google, could you give a link please?
NoEdit is just my name for "no ...Edit", in other words not using anything like that.
Unintentional troll is successful :D
haha :D
Sorry, I don't think I'm gonna use standard editor :)
So, do you actually really use no editor at all ?
Just the builtin Arena editor for TC. And Sublime Text 2 for web-based contests.
I use moj.moj
I know that pain, one time I would end up at #22, but stupid Kawigi sent two old versions and I ended up with 50 pts on a faaar position -_-.
Zero points brings to place #222, that was really tricky 250-problem.
I think my rating will increase again with 0 problems solved :D
UPD. Yes! :D
My soln for Div2 B was the positive soln for quadratic eq. t2 + t - d > = 0 and it failed system test. Any testcase that I missed to handle?
EDIT: Got wrong answer for d=999999998999999999. The right answer is 999999998. My program return 999999999. Does this happen because of sqrt() function?
The question was what t is possible. A lesson can't start at time t and end at time d - t2 < t, so you want t2 + t - d ≤ 0.
Yup, true, my bad. Nonetheless, my solution is (sqrt(1+4d)-1)/2, which works fine for all TCs except 1, i.e. 999999998999999999.
In Java: (long) (-0.5 + Math.sqrt(0.25 + d)) return 999999999, instead 999999998 (((
Precision errors, precision errors. When you just throw a formula in programming, there's always a chance that it'll fail because of stuff like this.
System> tourist unsuccessfully challenged LeBron's 250-point problem.
Achievement unlocked:) Anyway, this solution have stupid bug and actually failed system test:)
So, I was the writer this time around. I hope you liked the problems, or at least found them moderately okay...
I was also a bit surprised at how many solutions failed on div1 250. There are possible overflows when calculating length or when checking if a point can be zoomed to another by multiplying ints... did anyone hack a solution that does that with doubles?
And of course, div1 500 can NOT be solved with basic matching (the fastest submit used this, for example). There's a simple greedy solution, but it's not very obvious, so BLOOD in challenge phase is what I expected here (unlike with the 250).
Can you explain how to solve div1 500 without MinCostMaxFlow?
One of possible solutions:
Sort events by cutoffs (in increasing order). Then solve events one by one in this order. If your place from current event was not used yet, and it is valid for this cutoff — skip it. Otherwise you should increase answer and use some other place for this cutoff. And here greedy works well. You have to take place with highest cutoff among all remaining events such that place[i]>cutoff[i] and place[i]<=cutoff[current]. If there are no such events — place with highest cutoff among all remaining events with place[i]<=cutoff[i]. If still none of them matches — return -1.
First, you can sort the pairs by cutoff.
Then, go through the pairs by increasing cutoff and make them valid. I imagine that there are "holes" in places and store separately the elements taken out to form the holes. Then, the main question is just how to fill a hole; there are generally 2 choices for that and one is obviously better... so much for a detailed hint.
Also note that if the first few pairs up to cutoff[i] are valid, you can decrease all larger elements of places (even the ones taken from the holes) to cutoff[i] without affecting the answer.
Me and one more participant in my room had pretty simple solution which passed system tests:
Sort all pairs by cutoff.
Iterate all the pairs going from smaller cutoff values to larger values.
On each step you check if the current place is ok for this particular cutoff. If it's ok you go to the next element, otherwise you will need to swap this place with some other. So you look in the remaining part of the array for the place which will be less or equal than the given cutoff. There are two criteria how to select a place to exchange. First of all you're trying to take the element which was already swapped before. If there is no such element you take the one which has the biggest cutoff value associated with it.
If you didn't find a place to swap then solution doesn't exist. Otherwise you swap them and go to the next element.
While performing all these operations you remember which elements you were moving, at the end this will give you an answer.
I have absolutely no clue whether this solution is 100% correct or there is counter-test for it but it passed the system tests.
Can you explain how to solve it with MinCostMaxFlow? (assuming that it is not TLE)
O(N^4) (TLE idea:)
Build a bi-partial graph. In a left part we will keep our places, and in the left part — our cutoffs. Add edge between places[i] and cutoff[j] if places[i]<=cutoff[j]. It's cost is equal to 1 if i!=j or 0 otherwise. Now we should find maximal weighted matching in this graph. This problem is solvable using MinCostMaxFlow.
To get AC with this solution, one should use O(N) edges, not O(N^2). The overall complexity will be O(N^3) with really small constant. Please take a look at my solution in case you have any questions
cool, for some reason, I couldn't come up with this idea (how to use MinCostMaxFlow on this problem)
The obvious solution, with two layers of n vertices, will have O(n^2) edges. And it's definitely will get a TL because the total complexity will be O(n^3). But we can reduce the number of edges to O(n) by adding one additional layer of n vertices. Fist of all let's sort by cutoff. So the first(1..n) layer will correspond to places, the third(2*n+1...3*n) to cutoff. And we can add the edge of cost 0 from vertex i to i + 2*n, if place[i] <= cutoff[i]. The second(n+1..2*n) layer will be a chain with edges of infinity capacity. Also you need to add edges (n+i -> 2*n+i) for 1<=i<=n. For each vertex from the first layer, add edge to the first vertex from the second layer with cutoff[j]>=place[i], with cost 1. It's hard to understand, so you can draw it. The main idea is what we can just leave an object on it's place for cost 0. Or charge 1 and move to some position in the second layer, from which we can go only to positions where the cutoff is greater than place. Also you can check my solution at TC.
Thanks ,very nice problemset but I send to admin twice trying to understand what you need in 1000 Div2
as I understood you need to remove at most one edge and add another one with the same cost and result graph will be tree get the maximum cost of diameter of tree .
is that true ? can you clarify with TestCase 2 ?
Yes. You probably drew it wrong — the lengths are increasing so fast that you want all 100s and 1000s, but then you can only have one more edge in the diameter (so one 10-edge, for example 7-8 I think).
This How I draw it
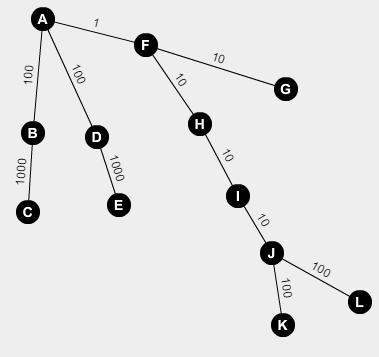
how we can get all 1000's and 100's with another 10
A is 0 B is 1 and so on
Thanks
Oh, so you just don't see it. C-B-A-D-E-(F-H)-K-J-L. F-H is moved to become E-K.
yep Thanks for clarification :)
I tried to ask admins for clarification for this testcase but the only response was the answer is correct :D :D
I know — but you should've found out how it works yourself. This sample isn't very hard when you know that you need to take all 100s and 1000s.
yep I solved it now it turned out to be very easy but sometimes the stress of contest itself prevent you from thinking in right way
but thanks for your problem set very cool
500 is quite interesting, I spent most of my time working on a DP solution before settling it down with a greedy one.
250's statement is a bit confusing though. Luckily, I assumed we must compare every pair of segments but after the contest ended, I realized that the statement just mentioned the overall interval.
Why isn't 500 a matching problem?
Because it's a greedy problem :D
Why use a slow boring (and copypastable) algorithm when there's a faster, more interesting one?
True :P But I saw some solutions that passed which used matching. So I asked. :)
I tried making a lot of various tests, but there is no way to catch them all. And I think the challenge phase did a good job there, anyway :D
as for 250 the word interval was not very clear, I'd better call it "interval between two contests" or even "some-strange-name" to not to allow misunderstanding.
And I don't really found in the statement why formally (1, 1) — (32,32) is not similar to (1, 1)-(2,2) in the first example so that I wrote wrong solution first (It was easy to fix through, removing few LOCs)
UPD: I've read it again and notice now that graph is sequence of points, not a line as I thought, so it's all ok then.
I like such greedy problems for 500 when tons of participants code buggy DPs because "500 is always DP"
It was defined that interval means subsequence. It kind of makes sense that it's a time interval...
Oh well, there was probably no way to phrase this problem without using a lot of formalism that you just need to read through very carefully. And samples are magic (I remember how I read the first few sentences of one statement, realized that I have no idea what it wants, read a sample and knew how to solve it immediately).
Also, well it's a sequence of points. The number of points doesn't change when scaling/moving.
Most stupid reason to fail 250 from me:
Solve it with hashes modulo 2^64, think it may fall on some anti-hash test, add some random stuff like %prime1, %prime2 in few different places, receive WA because of collision)
Of course, in case of dividing segments into buckets or using hashes modulo 2^64 this solution passes:)
That's like the definition of trying too hard :D
OK, I may admit, that MaxFlowMinCost was probably overkill and too time consuming for that task regarding presence of a greedy solution, but one thing grinds my gears. Why constraints were set to n<=1000, so that many people (including me) were thinking that this can pass -_-? "This can be solved in O(n log n) or something, so let's set constraints to smallest value such that MinCostMaxFlow won't pass!". Why it wasn't 100000 instead of 1000?? Or was that simply stupid TC policy about constraints not larger than X (previously X<=50, but that seems not to be the case right now) (that is one of million reasons why I hate TC)?
Problems were nice, but I'm not happy, because I solved 250+500 and almost got 1000 (I think), but MinCostMaxFlow turned out to be too slow and my 250 failed also (despite that I got long longs, I will have to figure that out), so that was just next TC when I end up with 0 pts :p.
By the way. Why have I even thought about MaxFlowMinCost in 500? In last SRM I participated in 500 pts problem was MaxFlow. In one SRM earlier 500 pts was ... another MaxFlow! TC seems to like MaxFlow problems, especially for middle ones :P.
Having had some experience with MPSQAS, I'll explain why the constraints of TC are often low (it may not be the only reason, but it surely is important for me).
I'll take Polygon as a counterexample. There, you have files to directly upload and you can view one at a time from a separate page; it's also truncated often (at several hundred characters or so, for example when viewing invocations). You also have a separate page for the problem statement, solutions as files, other uploadable files etc. All on separate pages or in files.
In MPSQAS, you have all of it in your applet at once, in text form (no files). At least not for all problems, but the currently loaded one, but still,
Apart from stuff like not being able to have more than one solution there (because there are no files, just a big text field where you can write/copypaste yours), the main restriction is in the tests: each argument of each test has an assigned raw text field. No truncation. You probably see now why the tests can't be too large: there's just no way loading/uploading them wouldn't make the applet a splode.
I noticed some slowdown of loading/uploading with div2 hard, and I made most tests there (around 50-60?) practically maxtest-size (which means around 30-40 thousand characters per test). A single test with N = 100000 on div1 500 would already have at least 400 thousand characters, so you can guess that it just isn't worth even trying to make some serious tests with that constraint.
So, the question isn't as much "why?" as it is "how?" :D
Did you do the O(N3) MinCostMaxFlow?
(I'm specifically watching out here not to phrase the question with an or. Come at me, logic trolls! :D)
I think so. I copy-pasted MaxFlowMinCost from marek.cygan's library, when there is written "Cheapest flow O(n^3) (higher complexity for weighs>1)" and I think this is a reliable resource, though I neither didn't read this code nor know how O(n^3) MaxFlowMinCost works :P.
In case of flows you never know, what time it will take. /contest/434/problem/D was a task where we had 10^5 vertices and edges and flow was a model solution, but "author couldn't find bad tests", so it was posed with such constraints.
Maybe its constant is too large. For N ≤ 1000, O(N3) will always be on the edge...
This comment explains an O(N3) solution, but also mentions that the constant is small — and it uses the fact that each place can be matched to an interval of cutoffs. For a generic O(N3), the constant would probably be larger.
Anyway, one does not simply solve this problem practically without effort (look, matching — copypaste).
I think the complexity of that solution is O(n^2 logn)
Isn't copy-pasting from others' libraries against topcoder rules?
It is :o? In that case I didn't know this. Though I know that not knowing the law is not good excuse for breaking it.
But... from the other side... Why is that so? In my opinion all publicly available codes should be allowed. What is more, there is no way to check that rule in contests. In such cases, there are always many people who will break that and in this situation you have kind of a moral conflict whether to be rightful guy or break rule like everyone other did. One time I was participating in a contest where there was a really "brilliant" problem "You got input consisting of 2n ints, treat this as an input to FFT or as an input to treap and print something (you have a choice). Author urges NOT to use prewritten code". How it ended? This task got loads of AC in first minutes, because people pasted FFT. It is a consequence of stupid rules, thinking that such kind of an arrangement will be fulfilled by all people is just a naivety. Rule about not using others codes is in my opinion stupid as well, because it can't be checked and if I ever have a situation that I would want to paste others codes I won't hesitate — that is my denial of such stupid rules. By the way I think that I did something like that first time in my life and what is more — it failed, so either way it is not that big deal :P.
I pretty much agree, having an unenforceable rule is worse than having no rule at all. If you do decide to break it, however, you shouldn't go advertising it in a public forum :P
Codeforces used to have this rule as well, but they have reverted it. Topcoder is a lot more bureaucratic, so I imagine it will take a long time and a lot of pressure for them to change this.
One possible reason is that the O(n*logn) solution was slightly more complicated to code than O(n^2), while requiring no additional insight, so they didn't ask you to do it. For example, I wrote the O(n^2) one for simplicity.
this is so depressing.. taking place 620 instead of 222 because of one unsuccessful hack.. thinking that division by 0 would give different numbers =\
moreover, 250pt was technically correct, but the array size was not 50 as usual ... and stupid looping over the length of the subsequence gave TLE =\
Some hint for 1k?
Div1 1000? You can split the colours into 2 and 2 (type A and B), then the sequence must look like ABABAB...A, where each A/B is a solution for 2 colours. There is a formula explained in one older SRM editorial, and you can apply it on some cases and for various cases. It's a bit long to explain.
Do you remember which srm was it?
I think it was around the end of the last year.
Can anyone explain Div II 1000?
Just linking now.
After tonnes of challenges in div1 250, I compiled a list of common sources of errors:
DmitriyH Calculating length of the only one of the compared sequences
qwerty787788 Using Math.hypot in Java
kraskevich Scaling coefficient should be the same for all segments
Xellos Comparing fractions using floating-point arithmetic(and ran into precision issues)
Xellos If you compared them using multiplication of numerator and denominator, you could get overflow(length squared can be around 10^12, thus the product of such two numbers does not fit into long long)
aranjuda Using rating_diff[i] to calculate reference score instead of date_diff[i]. Since rating_diff[i] can be 0, this can lead to incorrect solutions
Zzyzx Using == or != to compare doubles (precision error)
Username indicates user who mentioned that source of error on this post.
About floating point arithmetics, I was actually asking. I don't know if it's possible (if anything, I'd guess not) and want to know.
nic11 Using KawigiEdit (it syncs local file and text in itself bad)
That's not specific to this problem, so I'll leave it out :)
Many people(including me) coded an O(n^4) algorithm for div1 250 which of course TLEd
Did you think 4004 = 2.5·1010 would ever run in 2 seconds? Even with a constant of 0.1, there is no chance in this problem unless the test data are very shitty.
On the other hand, I think I could've made the tests for that problem still stronger (for example, I don't think I managed to make a test that has 2 overlapping intervals that are similar but not identical and very long, which means solutions that do O(N4) with breaks + checking if there are identical sequences could've passed, but I couldn't find a simple way to generate such a test). Good to see it still worked.
I wasn't calm while doing the SRM so I just did whatever came to my mind at that moment . I realized my mistake during the challenge phase and found some people who made a similar mistake as I made . So I was able to challenge one guy , The others were already challenged before I could challenge them .
Did anybody notice that today we had to scroll completely to right side in order to read the problem statement. Entire formatting was broken.
Yup...it was very infuriating!!
Perhaps the line breaks must be added to the long examples manually to avoid this problem.
Damnit, forgot to add them in div1 easy.
I think something wrong with this hack result.
Expected result is not same with recieved one. Am i missing something?
EDIT : my bad, it was defense result "no".
I don't know about any way to check from my side. Of course, the expected result should be correct, that's all I know.
Could you contact with admins please?
EDIT: no need
can anyone explain why is this the case for problem Div1 250:
{{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11}, {1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000}}
Expected: 9.0
Two equal parts: {1...10}, {2...11}. 10 — 1 = 11 — 2 = 9