


514A - Chewbaсca and Number
Author: Rebryk
It is obvious that all the digits, which are greater than 4, need to be inverted. The only exception is 9, if it's the first digit.
Complexity: 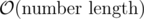
514B - Han Solo and Lazer Gun
Author: Antoniuk
Let's run through every point, where the stormtroopers are situated. If in current point stormtroopers are still alive, let's make a shot and destroy every stormtrooper on the same line with gun and current point.
Points (x1, y1), (x2, y2), (x3, y3) are on the same line, if (x2 - x1)(y3 - y1) = (x3 - x1)(y2 - y1).
Complexity: 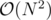
514C - Watto and Mechanism
Author: Rebryk
While adding a string to the set, let's count its polynomial hash and add it to an array. Then let's sort this array. Now, to know the query answer, let's try to change every symbol in the string and check with binary search if its hash can be found in the array (recounting hashes with 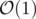 complexity). If the hash is found in the array, the answer is "YES", otherwise "NO".
complexity). If the hash is found in the array, the answer is "YES", otherwise "NO".
Complexity: 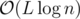 , where L is total length of all strings.
, where L is total length of all strings.
514D - R2D2 and Droid Army
Author: Rebryk
To destroy all the droids on a segment of l to r, we need to make 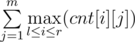 shots, where cnt[i][j] — number of j-type details in i-th droid. Let's support two pointers — on the beginning and on the end of the segment, which we want to destroy all the droids on. If we can destroy droids on current segment, let's increase right border of the segment, otherwise increase left border, updating the answer after every segment change. Let's use a queue in order to find the segment maximum effectively.
shots, where cnt[i][j] — number of j-type details in i-th droid. Let's support two pointers — on the beginning and on the end of the segment, which we want to destroy all the droids on. If we can destroy droids on current segment, let's increase right border of the segment, otherwise increase left border, updating the answer after every segment change. Let's use a queue in order to find the segment maximum effectively.
Complexity: 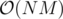
514E - Darth Vader and Tree
Author: Antoniuk
It's easy to realize that 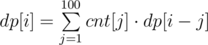 , where dp[i] is number of vertices, which are situated on a distance i from the root, and cnt[j] is number of children, which are situated on a distance j. Answer
, where dp[i] is number of vertices, which are situated on a distance i from the root, and cnt[j] is number of children, which are situated on a distance j. Answer 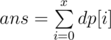 .
.
Let the dynamics condition
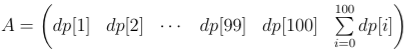
Let's build a transformation matrix of 101 × 101 size

Now, to move to the next condition, we need to multiply A by B. So, if matrix C = A·Bx - 100, then the answer will be situated in the very right cell of this matrix. For x < 100 we'll find the answer using dynamics explained in the beginning.
In order to find Bk let's use binary power.
Complexity: 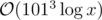







In C problem I used set< string >. After for every new word I did the same with you. I was changing each letter and I would try to find if changed word exists in set< string >. I think set's search with binary search has same complexity. Then why mine solution took TLE in 20testcase?
You must use set< hash >, not set< string >. hash may be an int64.
Set compares strings using O(min(|s1|, |s2|)) time, so the complexity of your solution will be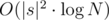 , where |s| is the length of the largest string. It should not pass.
, where |s| is the length of the largest string. It should not pass.
Yea,I see you are right. So if I had use a hashing method(e.x Rabin Karp-Rolling Hashing) I could pass all testcases?
Yep. Polynomial hashing will work here, but keep in terribleimposter's comment below. More details here
Could you give me some details about polynomial hashing? And how to use that in this case?
Also, is there no stl hash function for strings in c++? I am new to coding. Thanks.
We can calculate the hash of the string this way: h(s) = s[0] + s[1] * P + s[2] * P2 + S[3] * P3 + ... + s[N] * PN. We should do all calculations by some big modulo. P must be not even and approximately equal to the size of the alphabet used. We can store this values in array H, where Hi — hash of the first i + 1 symbols.
Now the key moment: Hash of substring from i to j will be Hij = s[i] + s[i + 1] * P + s[i + 2] * P2 + ... + s[j] * Pj - 1. So Hij * Pi = H0j - H0(i - 1), now we can divide it by Pi and get the hash of this substring, but we can't divide because we do all calculations by modulo. We can use extended Euclid algorithm for division or use other known trick instead... just multiply by Pj - i, if i < j. So we can get a hash of any substring using O(1) time.
There're no built-in hashing functions in C++, at least I don't know such.
Thanks a lot. It helps me understand others' code
how i can recounting hashes with O(1) complexity!! miloserd can u help me :D
Just read my previous answer more carefully. To get the hash Hij of substring of s from i to j we need to substract Hi - 1 from Hj and then multiply the result by Pj - i if i < j (otherwise by Pi - j)
can you please explain the code??? plzzzzzz....
C++, starting with C++11 has built-in hash function for many standard types. However, its exact behaviour is unspecified, so for example if one character of a string changed, you can't recalculate its hash in O(1).
Yes,you are right. I use this function but I get TLE on test 19.
There ans comparisons in set < string > , which take O(n) and the query of set < string > take O(len ^ 2 * log n) , not O(log n) , as set < int >
B can be solve in O(nlog(n)) just by maping the slops.
Complexity of problem E will be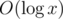 , as 1013 is a constant, that should not be counted in big O notation. Although we should keep that 1013 in mind :)
, as 1013 is a constant, that should not be counted in big O notation. Although we should keep that 1013 in mind :)
Just because we did not call it with a lowercase letter it does not means it is a constant.
If author was using 109 instead of x, i think you would say complexity is O(1), would not you?.
Hell yes.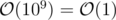
Please, read this: https://en.wikipedia.org/wiki/Big_O_notation
Then lets generalize the problem to let m = 101; now the complexity is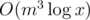 . Happy?
. Happy?
To be completely precise, it is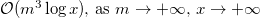 .
.
Everyone here understands the theory, it's after understanding the theory can people use shorthands. Are you going to be upset that someone uses u = x, dv = e^x dx while integrating by parts xe^x? No, because they get it, they know dv and dx aren't differentials because differentials aren't rigorous. That doesn't justify using a more cumbersome notation if a shorthand works perfectly fine.
Every algorithm we ever write on CF will always be O(1), since it's always capped at MAX_INT or MAX_LONG. But you'd have to be ridiculous to expect them to write O(1) for the time complexity of every algorithm.
Or, even if you ignore the 2^32 and 2^64 limits and consider the algorithms from a theoretical perspective with infinite memory, they're still all wrong. Because even addition is O(n), and multiplication is O(nlognloglogn) at best.
Theoretically, anti-hash test cases can be generated for any reasonable hash function. Hence, hashing should never be the intended solution for a task in my opinion. Sad to see something like this happen in codeforces. :(
I didnt really undestand what you mean,so why you believe that hashing should be never an intended solution for a task?
Because the probability that author's solution will produce the correct output on any custom test case is always less than 1 (theoretically). So, basically its not 100% correct.
I see.
(deleted)
Assume that you have a randomized solution which fails with probability 10 - 50 — you should be familiar with such problems and such solutions from ACM contests, it is a common practice to do some stuff like "let's try some magic for some random permutation of input 1000000 times, let's pick some random elements, let's move in some random direction...". And given problem either have no exact solution for given constants, or this solution is extremely complicated. In this case author should not give this problem at all? Because it have no solution or those cheaters will solve it with wrong solution instead of complicated but correct one?
Now let's make your hashing solution non-deterministic. Simplest way to do it — by picking constants for your hashing function using random.
Maybe it is still a bad idea to ignore this 10 - 50 risk when you are running space expedition, but for ACM contests it sounds OK. At least for me. Maybe just because I am already used to such problems.
Once again, you may not like such problems for some reasons (like that analogy with space expedition); but Petr, Gassa, Burunduk1 and lot of other authors are often using such ideas in their contests, and usually feedback for problems with intended randomized solutions is positive — and I guess they would stop doing it in case most contestants does not like this stuff.
ACM styled contests are totally different because there your solution need not be 100% correct to affect the results. But here, if you submit a solution using hashing, there is always some probability that it'll fail system tests and there is nothing you can do about that (unlike in ICPC where you can modify your hash function until it passes).
The biggest risk in codeforces is that if someone tries to hack a solution and gives an input to which the author's solution produces incorrect output then that's not good.
What I am saying is that problems like these are fine but the solution against whose outputs our outputs are checked should produce correct outputs for all the inputs that is possible to get in the contest. In an ACM styled contest, these inputs are just the system tests but in Codeforces/Topcoder, since hacking is allowed, these include all possible inputs. Hence this is technically not correct.
Of course randomized solutions are many a times much cooler than their deterministic counterparts, but they should not be given in Codeforces/Topcoder as intended solutions.
Well, in ACM you are also risking — sometimes 20 additional minutes of penalty have same cost as failed problem at CodeForces.
But now I finally got your point, thank you for explanation. I thought about the fact that author can check correctness of his cases using slow but correct solution, but totally forgot about hacks. You are right about this part:)
I just assumed that author uses some correct solution (like one with trie) for checking hacks (even if he didn't mentioned it in editorial). Long time ago, in Round #109 (prepared by Endagorion) author's solution for one of the problems (154C - Double Profiles) was using hashes, and it was discussed that it's bad idea (for reasons which you mentioned here).
Probably Rebryk should also describe safe solution without hashes in his editorial to make this part clear :) And I agree that if hashing was used to get correct answers for hacks, instead of some N*sqrt(N) (or other fast&safe) solution — then it was really author's fault.
The problem is that everyone is using incorrect hashing algorithms (e.g, from here (http://e-maxx.ru/algo/string_hashes ) which may indeed produce incorrect results. I agree that such algorithms should not be used in author's solutions (and, probably, anywhere else).
A proper implemented hashing algorithm is always correct, it just has a probability of taking more time than expected (not necessarily much more). It should be allowed for author's solution to run for more than time limit. Even in case some hack suddenly makes author's solution run much more than expected, it be easily detectable. The probability of such a hack is negligible though, if, again, a proper implementation is used.
Agreed. always expecting a better solution with certainty.(without any possibility of making mistakes.
How to find anti-hash test case for
H = (H * p + s[i]) % q?B is easy to solve in O(n) time. Algorithm : Move gun to (0,0) and each points according to this. Calculate tangens of each point and add to set. http://codeforces.net/contest/514/submission/9857015
set works O(log), so it's NlogN
Is there a way to do it in O(n) in C++?
unordered_set — insert works in O(1) on average.
Putting doubles into set you're just waiting for the precision problems.
Could someone please elaborate on how they are using a queue in problem D to get linear time?
First of all, you can implement queue using two stacks. And two pointers algorithm can be implemented with a queue (moving right pointer is equal to adding new element to the end of a queue, moving left pointer is equal to removing front element).
For every element of every stack you can maintain maximum value in part of the stack bounded by this element (it is either given element or maximum value in part bounded by element below). This value for top element of a stack will be equal to maximum value in this stack.
And maximum in queue will be larger among two values for stacks.
Wow that is really neat!
Update: Got AC 9858168. Thanks!
Implementing your queue in that fashion means your .dequeue() operation is O(k) worst case where k is the number of elements in the stack. So your solution is not linear, but quadratic in the worst case.
EDIT: Or I guess each element gets moved from the inbox to the outbox exactly once, so it would still be linear.. My bad!
EDIT2: Tried it myself, it works :)
great idea, thanks a lot, now I_Love_Bohdan_Pryshchenko
Is it possible to solve C using prefix tree?
Yes, i solved it using prefix tree. :) You can see my code here: http://codeforces.net/contest/514/submission/9841932
Great solution! Thank you.
**Problem C — Watto and Mechanism **
It can be solved using trie (prefix tree) and dfs in trie.
(did a TLE sol. in contest though)
You can see the code here: 9857974
deleted
deleted.
In the first question, only thing that the problem stated was answer should not contain extra zeroes. It didn't make it clear that we should not invert the first digit if it is 9. I mean the answer for 95 could be 4 without violating the problem statement.
You can invert digit, but you can't delete digit. So 95 cannot be converted into 4, only to 04, but it violates the statement.
In the problem C , I was using
set<string>for storing the input strings. Now if I do afindoperation with the query strings, what would be the time complexity of single query operation ? (with the total length of query lines as large as 6 * 10^5 ) —O(log n) or O(L log n)or something else ?And how would the set of strings compare any two strings — char by char or using some hash function?
For the first question, the complexity is
O(Llogn)... Because in theset<T>(T is a kind of type), we should give the way to compare two Ts, which means we should provide a function likebool operator<(const T&a,const T&b)const;However, the comparing function between two string is provided by#include<string>and it isO(L)And the second question, in order to compare correctly, the comparing function provided is comparing char by char.
Thanks a lot mathlover for the answer.
in order to compare correctly, the comparing function provided is comparing char by char.
Is it literally char by char? I made this hacking attempt yesterday — for given pair of strings, each of length 100000 , provided solution will twice compare pair of strings with lcp==0, twice compare pair of strings with lcp==1 — and so on, up to 99999. It gives us almost 10^10 operations in terms of char by char. But this solution works in 1.6s — a bit fast for 10^10 operations. Isn't there some block comparison used to speed up running over lcp?
I test your hack case and the code in my computer. I find that it cost 9 seconds in my computer! So I think the Online-Judge in Codeforces is very very fast.
This code costs only about 0.7s in my computer.
The most strange thing is that, the time cost by string comparing is 0.00% in all running time according to a
gprofanalysis. I think there must be some strange optimization inGNU libstdc++.I can not understand, why hash in C is full solution. As far as I can see 3^(6*10^5) is larger than 2^64, and hash is not unique. Moreover, I got full points writing prefix tree Can you prove me?.
I think a prefix tree can be considered as a set of string(if we add a counter, it can be a multiset or map), and it can find whether a string is in the set(prefix tree) in
O(length). I think it is correct.Most hashes are certainly not unique or why do we use hash? If C is in ACM/ICPC, you can simply choose a prime other than 3 because the problem setter does not know which prime you used so he can not construct data against you. He can only guess some contestants will choose 3 and build some data to make them failed. However, in Codeforces, hackers can construct data against a solution. So you have to compare two strings themselves when the hash of them are the same. However the probability of two different strings have same hash is low so only a few strings will be compared. So, the hash helped you to evade TLE.
It is very strange for me to see the solution based on hashes as the official solution on such a competition as codeforces, especially when another solution, not involving hashes is possible, because a participant does not see if his solution is fully accepted or not during the contest. That is why i expect that prefix tree solution should be somehow much worse, but I do not see the reason.
Yes, its very strange indeed. There is a possibility that a legitimate hacking attempt of some user failed because the author's solution also produced wrong output.
I think you can make the prime in hash be a variable P. Then you prepare hundreds of different primes and make a table of them, when the program begins, it choose P randomly from the table. I think no one can hack you, or your program has some bugs out of hash.
Another thing we have to consider: in this problem if we regard character 'a' as number 0, then
a,aa,aaa... will have same hash 0, whatever P. So it's better to regard 'a', 'b', 'c' as 1, 2, 3.Is it really so important that P in hash is prime? I think you can choose any random P in some segment.
problem b also can solved by o(nlogn) with save the y/x
Can Someone elaborate on problem C? How to hash the strings. I am not able to get it
Let every letter has value ('a' — 0, 'b' — 1, 'c' — 2), and there is a KEY (in this case suitable to take KEY=3, usually it is prime number greater than size of alphabets(3)) than simplest hash of the string s[0], s[1] ... is value (s[0] * KEY ^ 0 + s[1] * KEY ^ 1 ...) modulo 2^64, where s[i] — value of the letter on i-th position
I don't think it's correct. Since you assign $$$'a'$$$ to $$$0$$$, that means that the strings $$$bc, bca, bcaa, bcaa, ...$$$ will all have the same hashes. In other words, in your case, the no. of trailing $$$a$$$'s don't matter. To avoid this, all the chars must be assigned to non-$$$0$$$ values.
also modulo 2^64 is not that good idea: https://codeforces.net/blog/entry/4898
I have recently solved some problems on hashing and I realized that even modulo $$$10^9 + 7$$$ is also not a good idea. Hashing with a fixed base and modulus can be hacked. So, I've started using double hashing now, since it's very difficult to hack double hashing solutions.
I think the complexity of problem C is O(26*L*log(n)). Is that true?
Size of alphabet is only 3, not 26. So, O(3*L*log(n)) ~ O(L*log(n)) is enough. Correct me, if I am not right.
Thats correct. Still that gives TLE on test 28
can anyone explain the solution to problem E.I cant understand the editorial's solution
for problem 'A', nowhere it was written that the final answer should be of the same length of the original number. Disappointed........
"The number shouldn't contain leading zeroes."
How is it that Trie solution, with DFS on Trie, passing for C? Won't DFS check the whole input tree and the complexity will be O(M.(Sum of length of input strings)), which can be very slow?
No,
It will only check for 3*(Size of word to be checked) in worst case.
You can refer my code for clarification : 9857974
i.e.,
In the dfs recursion i've checked:
if(i==s.size())
if(x && cnt==1)
return true;
else
return false;
I guess complexity is:
Max(building trie, 3 x Σ(Size of m words) )
Which is O(max(n,Σ(Size of m words)))
Which can be max 3 * 6 * 10^5 operations
no, it's N * sqrt(N)
let A = sqrt(N);
long words more than A -> count of them < A.
short words lower than A.
so copmplexity is N * A
Can anybody tell what is the complexity of DFS solution for problem C? I agree with PrakharJain.
Check previous comment
The constructed trie can contain atmost nlog3(n) nodes. For every query, we would traverse the whole tree in worst case. Then the complexity will be O(nlog3(n) * m). That would go above 10^10. That should give TLE right?
No, i break off the function if there are more than 2 mismatches as well...
So if there are more than 2 mismatches, that dfs is dropped, else it will go only till the size of string.
I figured out that it will pass in time by trying to disprove that it won't. (couldn't really find a case)
Suppose we're trying to construct max test for problem. Let's define L as length of strings in input.
Let's take query strings as "aaa...aaa".
To make DFS run as deep as possible we need it not to meet two or more different characters till it reaches last character of the string, so DFS could scan whole tree. We can change only one character in any position. And we need last character to be different from 'a' not to interrupt DFS. Then we have 2 * 2 * (L — 1) strings satisfying these constraints or ~ 4 * L.
Then total number of operations is 4 * L * L * (Total — 4 * L * L) / L where 4 * L * L is number of characters of strings for trie and (Total — 4 * L * L) / L is number of queries for strings of length L.
To maximize this expression we need 4 * L * L to be equal to Total / 2. Notice that total number of characters in input is 6*10^5. Having this we can estimate total number of operations and see that it's about ~ 3 * 10^8.
Really nice! Thank you
How did you obtain 2*2*(L — 1) strings? Shouldn't it be 25 * 25 * (L — 1), since we can choose any character from the first L — 1 positions and replace it with any character other than a (which is one from bcd...yz).
I'm new to Hash
Can someone teach me how to avoid HashValue overflow or make hashValue still work?
My submission
looks like my hash will overflow in some case and then get wrong
ex:
1 1
bccbccababcaacb
bbcbccababcaacb
newfp -= Pow*(p[j]-'a'+1)%PRIME_Q;newfp += Pow*(k-'a'+1)%PRIME_Q;After the first operation
newfpcan become negative (too large if you use unsigned type) and the second one might not return it to "positive" numbers.Generally, if you want to subtract
afrombmodulom, it's advised do it the following way:a = ((a - b) % m + m) % m;.Let's use a queue in order to find the segment maximum effectively? how to use the queue?Could you tell me
When you increase the right end of the segment, you add the corresponding number to the queue; when you increase the left end, you remove the number. We need a way to maintain the maximum of all numbers in the queue. Let's first do that for a stack. That's easy: we just maintain a parallel stack that contains current maximum. Now recall that a queue can be implemented with 2 stacks. If those stacks maintain their maximums, we calculate the maximum value in the queue as the max of the two maximums. Submission: 9842348
Thanks for you help.Before that I can only solve the problem by segment tree...
Use doubly-ended queue (Linked list) here. Whenever you have to insert a number, remove all the numbers from the back until you find a number that is more than it. After that, insert the number. In this way, you'll have a queue with numbers sorted in decreasing order from front to back.
Oh!thanks!Now I know I can keep the queue monotonicity.
Can someone explain to me why my solution for problem C gets TLE on test case 18? thanks! My submission
Firstly you are computing length again and again using strlen() function inside a loop. Remember that strlen() is O(L). Secondly, you are also computing hashes using getHash() function inside a loop which is again O(L). Third, you are taking array of size 300001 instead of 600001. However the last one is not causing the TLE but Segmentation fault. Look at your corrected submission here
Can somebody elaborate solution for E? For me, it escalated too quickly from DP to transformation matrix.
It may help:Matrix Expo Tutorial
In problem A, for input 90909, AC soln gives 10000, shouldn't the right answer be 9 as it is asking for minimum positive number without leading zeroes.
You cannot delete digits...only invert them
Am I the only one who failed D because of binary search over length of segment and increased complexity to N log N. The tags have binary search but my solution didn't pass is it so because of poor complexity or poor implementation?
I've also solved this problem with N log N algorithm. Got 'Exceed Time Limit' with python implementation, but eventually 'Accepted' with C++.
alexander.kolesnikoff: I also tried the segment tree + binary search approach but getting TLE on test case 14. Link to my submission: 11563790. Can you help me finding where I am going wrong.
Thanks
In problems that require binary search over segments, it is always preferable to use SparseTable (RMQ) over Segment Trees. The problem with latter is that it adds another logarithm factor while querying hence degrading the complexity.
Here is my solution with SpareTable implementation:
As I can see you have got runtime-error, not time limit. My solution's complexity was O(N**M*log^2 N) because of segment tree(I can code it faster than RMQ) + binary search and it passed.
P_Nyagolov: My solution also has the complexity same as yours but I am getting TLE on test case 14. Can you please help me? Solution id: 11563790
In problem C , i used "trie" to solve the problem .But it is giving memory limit exceeded.Can i know why ?? Submission id: 10300905
I had the same problem, there is no need for the string to be in the function parameters
I solved it hours ago, my submission: 20196208
Can someone please explain solution for D? Why are we using queue in the first place? I understand its a DP based problem but not able to get the solution.
In Problem C, why not put the hashes in an unordered_map<int, bool>, instead of a set? Expected time of searching for a element in an unordered_map is O(1) while in a set it would be O(logn)
https://codeforces.net/contest/514/submission/59140838
Why does this soltion fail? It saves all the entry string's hashes in a map, goes through the queries, changes the current string in all possible ways (2*|s|), and checks if a hash of any of the changed strings is saved in the map. P = 5, MOD = (1 << 64)
Please someone help using the same technique my solution is failing for test case 7 https://codeforces.net/contest/514/submission/60584041
My C solution with Trie https://github.com/joy-mollick/Trie-Data-Structure/blob/master/Codeforces-514C%20-%20Watto%20and%20Mechanism.cpp
nice work bro! it helped me.
216571360
problem C can be solved using trie submission: 216571360