


Hi everyone,
Recently I came across a problem RACETIME on SPOJ. After trying hard for the problem when I couldn't make a progress I searched internet for a solution.
Discussions on various forums talked about the technique of Square Root Decomposition.
So I studied about this technique from here.
I looked for various other problems also which used this technique like 1,2,3 and 4
But after going through all of them my question is
What thinking process does one undergo before coming up to the conclusion that a particular problem can be solved using Square Root Decomposition?
Sometimes they even divide the queries into sqrt N buckets and then solve them?How does that one even think that.
I have searched a lot over the internet but couldn't get anything useful except their implementation.
So it'd be really very useful if someone could explain me about how to approach such problems possiblly with some example So that whole programming community can get benefit from it.
Thank You!!







Basic example ("flattened interval tree");
You're given a sequence S with changing elements and you want to answer queries about a sum of elements on a given intervals. You can divide whole sequence to blocks of length
blocks of length  and we want to maintain a sum of elements of those blocks. If we want to perform a "change" query we need to update elements and change the sum in block it belongs to, so O(1). If we receive a query about an interval we can divide it to some number of blocks. If we are dealing with sequence of length 100 we divide it to 10 blocks of length 10 and if we are asked about a sum of elts on interval [15, 58] we divide it do [15, 20], [21, 30], [31, 40], [41, 50], [51, 58]. All but two border ones are full blocks, so we know sum within them and there are at most
and we want to maintain a sum of elements of those blocks. If we want to perform a "change" query we need to update elements and change the sum in block it belongs to, so O(1). If we receive a query about an interval we can divide it to some number of blocks. If we are dealing with sequence of length 100 we divide it to 10 blocks of length 10 and if we are asked about a sum of elts on interval [15, 58] we divide it do [15, 20], [21, 30], [31, 40], [41, 50], [51, 58]. All but two border ones are full blocks, so we know sum within them and there are at most  of them. Two border intervals have length at most
of them. Two border intervals have length at most 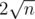 , so we can enumerate elements within them one by one and we get desired results using at most
, so we can enumerate elements within them one by one and we get desired results using at most 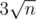 opertions. Of course that particular problem can be done in O(logn) per query, but this was just a clarifying example.
opertions. Of course that particular problem can be done in O(logn) per query, but this was just a clarifying example.
But sqrt decomposition is a very general concept. It means dividing n objects to groups of
groups of  of them. Here we divided a sequence, but it is possible to divide queries. Here you have two other examples of sqrt decomp with tutorials: http://codeforces.net/contest/455/problem/D & http://codeforces.net/contest/513/problem/F2
of them. Here we divided a sequence, but it is possible to divide queries. Here you have two other examples of sqrt decomp with tutorials: http://codeforces.net/contest/455/problem/D & http://codeforces.net/contest/513/problem/F2
What thinking process does one undergo
Often it is something like Oh, looking at constants, maybe I should figure out some solution with SQRT-decomposition.
If you already know some problems with sqrt-decomposition — solving another one may be easier for you. Some of those problems are tricky, but for most of standard problems you may just try one of standard approaches — dividing array into blocks, dividing vertices/colors/numbers into heavy/light groups, dividing queries into blocks and so on.
So you may look at editorials of few problems with such solutions, and next time you'll face some problem with SQRT-decomposition — you'll probably think oh, i've seen something similar before :)
And why the size of blocks has to be
sqrt(n)? Why notlog(n), or a polynomial, or other thing?Because if the size of block was log(n) then wwe would have n/log(n) number of blocks. A query could take n/log(n) time which very close to n and does doesn't give the edge.
We take sqrt because then both the size and number of blocks remains the same. Get it?
ash1794 is right. And in general, size of block isn't always sqrt(n). In most cases even if both parts of solution have same asymptotic — hidden constant is different, and optimal size of block isn't exactly sqrt(n). And often it happens that one part is much slower, and optimal size of block is far from sqrt(n) (even if idea is still like in sqrt-decomposition).
This problem comes into my mind, my solution with block size equal to 512 or 1024 receives TL, and my solution with block size equal to 2048 got AC.
How would you calculate the optimal block size?
Ideally if the optimal block size is X, then increasing X should increase run time and decreasing X should also increase run time.
And I think the optimal block size would depend on the type of testcases / number of queries / updates etc. But on general case you could generate some random test file and ternary search for the optimal X upto say 10 steps.
But it's not suited for a short contest and I haven't tried it either.
I have a very strong intuition that any problem that can get solved with "sqrt decomposition" can also be solved by a segment tree (more efficiently in time but more expensively in space).
Are there any problems where for whatever reason that is not the case?
I think there are problems that can be solved with sqrt decomposition but not with segment trees. I've solved a lot of query problems and segment trees are not always applicable. An example I can think of right now is to support queries:
1) Change/Access value of some element
2) Reverse order of elements in some segment
I know of no efficient way to simulate this with a segment tree, but sqrt decomposition-like solution works fine. It's not the best example and there may be some solution with trees I'm unaware of, but that's the only example I could come up with.
However what I'm sure of is that sometimes the tree solution can end up being O(log2) with very heavy and memory-consuming 2D structures, while the sqrt solution is light and low on memory.
I remember once I implemented O(log2) per query with some heavy structures and got lots of time limits, but O(sqrt * log) worked lightly!
Sorry to necrobump, but I'm also wondering — how would you support those queries?
Burunduk1's lection: http://acm.math.spbu.ru/~sk1/mm/lections/mipt2016-sqrt/mipt-2016-burunduk1-sqrt.en.pdf
Could you prove the trick in the 1st problem??
There are at most n - 1 edges in a tree where n is the number of vertices. Every edge has exactly 2 free ends. Hence, there are 2n - 2 free ends. Every heavy node takes up at least free ends.
free ends.
If you use treaps you can split and merge trees in O(log) and reversing segment is just a lazy propagation on treap. If you need to reverse some interval you just split tree into intervals [1, l-1], [l, r], [r+1, n] and change the flip value on root of [l, r]. Then propagating down just swap children and flip children flip value. If you need to access n-th element just search for it like in normal bst propagating down.
This response is rather late, but http://e-maxx.ru/algo/sqrt_decomposition offers some good examples. For instance, consider this problem:
You have N different nodes in a graph and is responsible for 3 queries:
1) Connect 2 nodes by an edge 2) Delete edge between 2 nodes 3) Query whether or not 2 nodes are connected.
You can break the queries into O(sqrt(N)) chunks and process each individually using Union Find.
I believe this problem can't be solved using Segment Tree but certainly using Sqrt Decomposition.
Assume we have created the reduction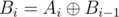 . Then the query is simply "Count the number of elements equal to K in a given prefix". Similarly the update is transformed to "Xor all elements in a suffix by a value".
. Then the query is simply "Count the number of elements equal to K in a given prefix". Similarly the update is transformed to "Xor all elements in a suffix by a value".
This can be easily done in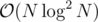 with a segment tree by keeping a trie or std::map of the numbers in the current node's range. You will need a lazy value to handle the update but this shouldn't be a problem.
with a segment tree by keeping a trie or std::map of the numbers in the current node's range. You will need a lazy value to handle the update but this shouldn't be a problem.
You're right, my bad. Thanks!