


Всем привет!
Уже в эту субботу, 28 марта в 18:00 состоится первый квалификационный раунд Russian Code Cup 2015. Раунд продлится 2 часа. По итогам раунда 200 лучших выйдут в отборочный раунд, где сразятся за выход в финал.
Те, кому удача в субботу не улыбнется, а также те, кто по тем или иным причинам не смогут принять участие в раунде, смогут попробовать свои силы во втором отборочном раунде 25 апреля в 12:00, а при необходимости и в третьем – 31 мая в 13:00. В отборочный тур, назначенный на 13:00 14 июня, пройдут 200 лучших участников из каждого квалификационного раунда.
Для того чтобы принять участие в Russian Code Cup, нужно зарегистрироваться на сайте http://russiancodecup.ru/ (регистрация будет открыта до начала третьего квалификационного раунда).
Подробнее о чемпионате, правилах и призах и читайте на сайте http://russiancodecup.ru, по всем вопросам обращайтесь на [email protected]
Приглашаем всех принять участие в квалификационном раунде Russian Code Cup и желаем всем удачи!







А можно поинтересоваться, почему было решено отказаться от футболок для 600 лучших? Футболка куда круче сертификата, как мне кажется
Добрый день! от футболок решили отказаться в основном по двум причинам: во-первых, из-за больших сложностей с отправкой и доставкой футболок почтой и отсутствия возможности как-либо влиять на сроки и качество доставки, а так же негатив участников, возникающий из-за несвоевременного получения посылки. Наверняка здесь есть много участников RCC прошлого года, чья футболка так затерялась в недрах почты или по независящим от нас причинам была возвращена... Во-вторых, мы регулярно получаем просьбы и комментарии участников о желании получать сертификаты, подтверждающие участие или квалификацию.
Кстати, кто не получил футболку — напишите нам на [email protected] — отправим еще раз.
Даже если не получил футболку с RCC2013?
Дипломы тоже через почту?) Или пдф?
А почему нельзя давать и футболку, и сертификат?
Чтобы избавить участников от необходимости носить дополнительные тяжести с почты, вестимо.
Да мне как-то норм было
В таком случае негатива участников, возникающего из-за несвоевременного получения посылки будет в два раза больше. За футболку и еще за сертификат. Такого допустить нельзя, ни в коем случае.
Ребята, только если кто-то сольет финал, то не говорите публично вещей вроде Обидно, что в призы не попал — а то в следующем году вообще призовой фонд отменят, во избежание подобного негатива.
Так сертификат-то в PDF, как я понял. Иначе какой смысл менять футболки на сертификаты, если все равно Почтой России доставляться будут?
Видимо, расчет на то, что если не дойдет сертификат, то никто не расстроится...
Странно это, моя футболка в том году тоже потерялась, я написал письмо по другому поводу о ней и с удивлением узнал, что ее вообще мне не выслали. Ответили, сказали, что теперь выслали, пришла в течение двух недель чтоли. Никакого нигатива не осталось вообще, хотя удивился такому факапчику. Но факапы случаются, а решение выбрано странное. И так понятно, что самый гарантированный способ избежать ошибок — вообще ничего не делать.
Я бы сказал, что ожидание этих футболок не оправдывается их красотой и прекрасностью дизайна, удобства.
зато как мы радуемся, когда они приходят!
А всем по два одинаковых письма пришло?
да, почта майл.ру работает надежнее почты России!
Вот бы Почта России так работала!
Тссс, а то на следующий год откажутся от рассылки уведомительных писем.
Блин, время неудобное, у меня уже планы есть на вечер. Может отменить квалсы в ближайшую субботу, чтобы я не расстраивался?
когда Russian Code Cup проводит контест вечером в субботу, в мире расстраивается один knst
Для того чтобы принять участие в Russian Code Cup, нужно зарегистрироваться на сайте http://russiancodecup.ru/ (регистрация будет открыта до начала третьего квалификационного раунда).
При этом, как я понял, после начала раунда на него зарегистрироваться уже нельзя: несмотря на то, что первый раунд идёт на данный момент всего семь минут, регистрироваться система предлагает только на второй.
значит, прошлогодний баг (у зарегистрировавшихся после начала раунда не было кнопки "отправить") исправили самым простым способом :)
У кого-нибудь была проблема со сдачей задач через Visual C++ 2013?
Была, WA на втором тесте в первой задаче, тот же код в GCC зашёл
Аналогично =_=
Я томат. Весь контест решал третью, но как будто чуваки сидят по кругу. =\
Так вот почему у меня неправильно работает!! Спасибо =)
Раунд прошёл очень гладко, по сравнению с предыдущим годом. Спасибо большое организаторам!
Правда, очень раздражало прыгающее туда-сюда окно с задачами во время второго часа (об этом уже писали в комментариях к warm-up).
Задачи оказались интересными, но я смог решить только две. Придумал по четвёртой, как считать начальное количество способов, а с изменениями так и не вышло чего-то разумного. Предвкушаю поучительный разбор!
В четвертой у кого-то зашла корневая, или нужно было все же не халтурить и честно написать дерево отрезков?
У меня зашла корневая.
Так разрешён же prewritten code. Чего там писать, если есть template/generic класс дерева интервалов и класс матрицы?
Я криворук, но у меня и ДО получило TL 2.
Все фигня
Это нормально, что в задаче B зашло решение if x * y == z или я что-то не понимаю?
[ignore previous message]
А
*у тебя — произведение чисел в системе счисления по основанию 10 или произведение полиномов?Там вроде заходило простое умножение в десятичной системе счисления. На кф проверил.
интересно тогда =), т.е. у них похоже нет тестов вида 4 4 16
Да, из over9000 тестов там нет ни одного, в котором x*y==z в 10й системе, и чтобы перенос при длинном умножении был ненулевым.
Если у вас типы ограничены.
Произведение чисел в десятичной системе счисления.
ЛОЛ.. а эта ересь еще и прошла)
Я думал примерно так: заменим числа x, y, z в равенстве полиномами с неизвестной базой w и коэффициентами, равными их цифрам. Раскроем скобки и перенесем неизвестные в одну сторону. Получим полином от w, который будет равен нулю при любом w тогда и только тогда, когда все его коэффициенты будут равны нулю. Что и означает x·y = z
А за что минусы? Все правильно человек написал. Только произведение не в десятичной системе счисления, а произведение полиномов x * y = z. Сверху уже упоминали банальный тест 4 4 16. Немного глупо, что некоторые джависты просто перемножили 2 биг-инта и сдали задачку :)
Контест в Тренировках: 2015 Russian Code Cup (RCC 15), 1-й квалификационный раунд.
А что не так с этими посылками: http://codeforces.net/gym/100653/submission/10504555 и http://codeforces.net/gym/100653/submission/10504510 ? На RCC этот код зашёл.
Была тонкость: все решения в архиве жюри почему-то читают-пишут из файлов game.in/game.out и визард подготовки тренировок распознал именно такой ввод-вывод. Я исправил эту небрежность составителей архива и обновил тренировку — теперь ваше решение проходит.
Спасибо большое.
Как решать задачу E?
Храним для всех возможных 0<=x<m ответ. Переход n->(n+1) это тупая динамика, а n->(2*n) это уже FFT по тому самому модулю. К счастью, модуль хороший: MOD-1 делится на 2^23. FFT с комплексными не заходит по точности.
У нас в команде gchebanov писал FFT по модулю, но через комплексные числа. Надо представить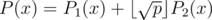 , где P(x) — многочлен с целыми коэффициентами < p, P1(x), P2(x) — многочлены с целыми коэффициентами
, где P(x) — многочлен с целыми коэффициентами < p, P1(x), P2(x) — многочлены с целыми коэффициентами 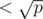 . Тогда перемножение двух обычных многочленов по модулю p можно выразить через четыре произведения многочленов с маленькими коэффициентами, и для них точности вполне хватает. Если не изменяет память, еще и работает быстрее, чем модульное FFT (впрочем, gchebanov поправит, если я наврал).
. Тогда перемножение двух обычных многочленов по модулю p можно выразить через четыре произведения многочленов с маленькими коэффициентами, и для них точности вполне хватает. Если не изменяет память, еще и работает быстрее, чем модульное FFT (впрочем, gchebanov поправит, если я наврал).
Да, именно так. Только не к 4м умножениям, а к 3м (по аналогии с Карацубой). Еще надо не забыть по модулю в конце взять.
И что, действительно быстрее работает? Плюс точность же зависит от размеров векторов, как я понимаю где-то до 220 хватает?
Да, хватает, даже если использовать double. Производительность когда модуль порядка 10^18 не сравнивал — но по идее там уже должно побеждать хитрое умножение по модулю в сравнении с запуском 9-16 комплексных умножений. Большей частью преемущество достигаеться за счет того что на умножение в комплексном случае уходит две фурьешки, а в честном — три. В некоторых случаях это не нужно — например возведение в квадрат, там может сложиться по другому.
А как тремя умножениями если мы не возводим в квадрат, а умножаем разные полиномы? Работает кстати не быстрее по крайней мере у меня (4 умножения полиномов, каждое за 2 fft, в long double) ~2400ms против ~500ms в случае обычного fft по модулю если нам повезло с модулем (1 умножение за 3 fft, в int). В double точности не хватает.
Как за 3 умножения: нужно посчитать
(a0 + B·a1)·(b0 + B·b1) = a0·b0 + B·(a0·b1 + a1·b0) + B2·a1·b1.
Пусть C = (a0 + a1)·(b0 + b1) (первое умножение).
Тогда ответ a0·b0 + B·(C - a0·b0 - a1·b1) + B2·a1·b1.
В double точности не хватает скорее всего потому, что каждый раз идёт домножение на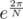 и накапливается погрешность, если каждый раз считать угол, то всё нормально.
и накапливается погрешность, если каждый раз считать угол, то всё нормально.
Код со всем сказанным выше (и работает довольно быстро, даже с кучей векторов).
Да точно как в Карацубе. Переписал на то чтобы каждый раз угол пересчитывался (правда это надо в предподсчете делать а то очень медленно получается) и норм потери точности пропали 358ms (3 умножения по 2 fft в каждом, в double, ручной complex).
Можно вообще 4-мя Фурье обойтись: a0, b0, a1, b1 за 2 FFT переводим во frequency domain, объединяя в пары, и обратно тоже за одно FFT a0b0 и a1b1 переводим в time domain, за другое (a0 + a1)(b0 + b1).
Как решать C?
Я решал через ДП по состоянию: 1. Кол-во пар, которые надо рассадить 2. Кол-во одиночных математиков, которые надо рассадить 3. Кол-во одиночных философов, которые надо рассадить 4. Кто был посажен последним (математик или филосов) 5. Кто был посажен предпоследним (математик или филосов) 6. Есть ли у посаженного последним напарник среди еще не рассаженных
Пересчитывать за O(1) думаю понятно как
Мне кажется или не стоит хранить "Кол-во пар, которые надо рассадить". Так как если мы смотрим на pos стул (нумерация с нуля), то "Кол-во пар, которые надо рассадить" равняется (2*n — pos — fil — math)/2, где fill = -это "Кол-во одиночных философов, которых надо рассадить", math — это "Кол-во одиночных математиков, которых надо рассадить".
У меня в состоянии нет "pos стул". Эту позицию я вывожу из того, что есть.
Можно такой динамикой:
dp[n1][n2][pairs][last][last_paired]— сколько способов расставить числа на первыхn1+n2местах, чтобы среди них былоpairsпар одинаковых чисел, чтобы маска типов последних двух чуваков былаlast( ≤ 3), и что у последнего (была пара)/(не было пары). И математиковn1и философовn2.Переход -- перебрать, кого из 2-х ставим, будем ли использовать число, которое уже было или не будем. Когда-то вычесть 1 случай, когда текущий равен последнему.
ДП ([номер позиции на которую надо поставить очередного М или Ф], [число непосаженных математиков у которых парного им философа уже посадили], [число непосаженных философов у которых парного им математика уже посадили], [кто предыдущий-М или Ф], [кто пред-предыдущий-М или Ф], [поставлен ли предыдущим М или Ф из тех, чья пара уже выставлена]). итого 16 млн состояний при N=100 и переходы между ними что-то около O(1).
Как решать задачу D?
Если бы в задаче не было изменений — понятно, что можно написать простенькую динамику "сколькими способами можно валидно нарезать такой-то префикс".
Как сюда прикрутить изменения? Сделаем дерево отрезков (да и корневая, как выше подтвердил Zhukov_Dmitry, тоже заходит, потом перепишу свою аккуратней:) для корневой можно посчитать ответы внутри каждого блока той же наивной динамикой), которое будет для каждого отрезка знать, сколько есть способов валидно нарезать этот отрезок без 0/1/2 символов слева/справа. При изменении нужно будет проапдейтить только логарифм отрезков. Как сливать такие отрезки? У отрезка-объединения слева будет столько свободных символов, сколько было свободных символов на префиксе у левого отрезка, справа — столько, сколько было свободных на суффиксе у правого; нужно перебрать, что происходит на стыке левого и правого отрезка — либо они просто сложились, либо же код какого-то числа был разбит на части, и попал и в суффикс левого отрезка, и в префикс правого (т.е. объедиение свободных символов суффикса левого отрезка и префикса правого отрезка дало нам валидный код). Так как коды у нас короткие, то все такие разбиения можно перебрать.
А ответом будет число разбиений без свободных символов слева и справа для вершины-корня.
Кажется проще понимать так: вспомним как мы считаем динамику на префиксах, текущее состояние зависит от MAGIC = 3 предыдущих, причем линейно. Т.е. это просто умножение на какую-то матрицу, нам надо уметь изменять эти матрицы и считать произведение всех. Это можно делать деревом отрезков с обновлением в точке, ибо меняется всего MAGIC матриц.
Вместо Infinity выводил Infinite и полтора часа сидел над ошибкой( В итоге забил на раунд и не прошел квалификацию(
А что приходило? PE?
Ну по wa/pe на первом тесте можно было догадаться, что что-то здесь не так
(а еще можно тулзы использовать, которые сами на тестах проверят :) )
Впервые вижу на контесте long arithmetic, пришлось вспоминать Java и его ввод-вывод — дискриминация по языку. Еще как-то кривенько сделана сложность задач — хотя бы две задачи решили куча человек, хотя бы три задачи сдали куда меньше, за счет чего в раунд проходят не те, кто больше рубит, а кто быстрее нагуглил "Java BigInteger example", имея установленный eclipse :)
BigInteger... дааааа :)
Ага, а в питоне вообще считал два числа с 1000 знаков и просто вывел (a*b), без никакого BigInteger. Дело не в том, знаю ли я алгоритм умножения числа на число, а в том, что нормальный проблемсеттер не допустит, чтобы один и тот же алгоритм, который требуется в задаче, был доступен изначально в одном языке, и не был доступен в другом
Вообще там не должно заходить a*b — выше читай.
На паскале нет встроенных сортировок! Дискриминация по языку!
На паскале вообще ничего нет. Никто не виноват, если вы его используете и каждый раз заново пишете аналог STL :)
Полный абсурд. Такое можно говорить и про плюсы относительно питона. Никто не виноват, что Вы пишете на плюсах и не умеете писать сортировки / длинку за 1 минуту. (особенно, когда стандартная длинка питона и джавы не должны были заходить)
Есть стандартный способ, не использующий длинку — посчитать все по N случайным простым модулям.
Это нормально, что (как я понял) у них на сервере не подключена ссылка на System.Numerics (MSVS C#) и соответственно, когда я подключал (для использования BigInteger) оно мне кидало ошибку компиляции? Соотвественно я убил кучу времени, потом осознал, что такое решение (x*y==z) неверное (хотя и заходило) и переписал с огромным штрафом
P.S.: код посылки я уже не найду, но если та посылка проходила тесты, то я проходил в следующий раунд
Да, это нормально, к сожалению, хоть и не хорошо. Я для таких вещей пишу инкапсулятор для программы. Т.е. программу, которая загружает сборку другой программы из массива байт и вызывает в этой сборке функцию Main.
А это законно (не противоречит правилам)? И можно код, пожалуйста.
Обычно законно, но на CF такое, я думаю, нельзя использовать, так как данный метод можно считать обфускацией.
Вот код загрузчика из памяти
А вот код инкапсулятора:
Непонятно как это использовать применительно к System.Numerics, но вы подали мне идею:
Выводит 2^100, аналогично доступны остальные методы, работает для CodeChef/SPOJ/ideone, Codeforces(Mono) и Яндекс.Контест - везде System.Numerics не подключена. Нет возможности проверить на RCC, но скорее всего будет работать.
Да, подобный метод я тоже рассматривал, но вы же понимаете, что рефлексия — дело не очень быстрое? По тому лучше раз загрузить сборку и выполнить.
А теперь объясню, как работает мой метод. Дело в том, что вы можете скомпилировать программу у себя на машине, указав в ней ссылки на нужные библиотеки. Затем эта сборка загружается из памяти и подгружает все, что используется и было указано при компиляции.
Т.е. я просто компилирую код у себя, ссылаясь на System.Numerics, а затем отправляю байт-код скомпилированной программы в исходном коде, который отправляю в систему
Понял теперь, хитро :) Выглядеть такой сабмит действительно подозрительно будет.