


Hello CodeForces Community!
I am glad to share that HackerRank's EpicCode (Summer CodeSprint on Algorithmic Programming Challenges) is scheduled on 20-June-2015 at 16:00 UTC.
Go ahead and register now at www.hackerrank.com/epiccode to show off your coding chops, and win amazing prizes like GoPro Hero4, Oculus Rift Developers Kit Dk2, XBox One, Pebble Smart Watch, The Arduino Starter Kit, Raspberry Pi 2 and 100 HackerRank t-shirts!
All participants who completely solve one challenge (that’s just 1 out of 8 questions!) will get $100 of AWS credits.
Also, you'll get an opportunity to connect for a career opportunity with EpicCode contest sponsors — Amazon, Cogito API (Expert System), GoDaddy, iNautix, KCG, Location Labs, Pocket Gems, Rakuten, Salt, ShoreTel, Skyhigh and Vertafore.
Contest will be algorithms only and rated.
UPDATE Scoring is 20 — 30 — 30 — 50 — 70 — 80 — 120 — 150.
Tiebreaker is person to reach the score first.
GL&HF







Sounds exciting :)
What is the expected difficulty of the problems? According to the prizes, it seems to be Div1 D/E
I never understand when someone asks questions like this. Isn't it more interesting to figure it out yourself?
That's an opinion, if it's more interesting to you, it doesn't mean that it's more interesting to all people.
I understand that it is more interesting to you, but I prefer to know what to expect from the contest before participating.
Imagine going to a contest like IOI thinking that the problems will be Div2 C/D, you will be stressed if you can't solve them, which negatively affects your performance (At least for me :) )
Since there are 8 challenges you will see a full spectrum of difficulty ranging from Div2 A,B to something really hard.
Since there is a prize on solving even 1 challenge, I think everyone should give a try and claim that.
What are rules btw? couldn't find them on the contest page.
I mean scoring system, penalty system, feedback, etc.
I have updated it in the post. What do you mean by feedback?
I mean when you submit do you know final result for that submisiion like jn ACM?
Just simple feedback. You submit you get judged. You may submit any number of times, without any deductions in score.
Thanks for the information
Can't enter the contest: first the system proposed to register for round, now it keep saying 'Err. Looks like something went wrong.'
Same here
Same here.
Working now.
dont think so :(
A lot of 404s
Keep calm and press F5
Keep calm for <=5 minutes, huge load. We're fixing it asap.
24 hour contest we can relax a bit I think :P
Oh really ? can't load ?! when you are posting this entry EVERYWHERE it's impossible to participate on Hackerenk with 10k people (don't care minuses) sorry for my open position.
Website smooth and up in action, please continue coding :)
I submitted 20 minutes ago, still processing.
after seeing it so many times the python joke is not funny anymore
I get these for a change.
it is talking forever to process :(
Tell me pls anyone where can i see Time/Memory limits?
hackerrank.com/environment
1 exception C/C++ is 1sec in most of challenges.
i think that's not good idea to use time prior for same competitions
This contest made me look deeper into segment trees then ever before.
Was sqrt decomposition solution to problem square array? I was only getting 68/80 for this..
i got 80 using sqrt-decomposition.
also stupid sqrt-decomposition got 92(!!! O.o) on Set queries, but i submitted it after contest finished(
Can you share your code?
sure, but i think it's hard to read this code.
Can you explain the basic idea. I couldn't understand an optimal update strategy. My idea was to go for an offline method, but it timed out still.
I guess all problems of this kind can be solved using segmenet tree or even fenwick tree. I solved it using segment tree.
When we add an interval [x, y] then in fact we add log(n) align intervals which corresponds to our nodes in segment tree. On each align interval [a, b] we add sth like (k + 1)(k + 2), (k + 2)(k + 3), ..., (k + (b - a) + 2)(k + (b - a) + 3).
We keep four numbers in each node:
sum of actual values on this interval
number of k mention above
sum of k mention above
sum of k2 mention above
And we use lazy propagation. U can find similar task with good editorial here http://lbv-pc.blogspot.com/2012/11/rip-van-winkles-code.html
I solved it by Segment tree, {1 * 2, 2 * 3, 3 * 4, 4 * 5...} = {1, 3, 6, 10, 15...} * 2 = {1, 1 + 2, 1 + 2 + 3, 1 + 2 + 3 + 4, 1 + 2 + 3 + 4 + 5, ...} * 2
for each vertex in segment tree I save 3 value: first element,Difference,and difference of differences,here my code with easy "lazy propagation".
you can solve it with Fenwick tree by first calculating: sum(i = x to n) (x — i + 1) x (x — i + 2) , you will get a polynomial of degree 3, then you can use four BITs to heep all necessary information.
What is intended complexity of solution for "Set Queries"?
I tried sqrt decomposition with complexity O(N * sqrt(N) * log(N)) (with logN for Fenwick tree), but only manage to get 82 pts :(
I got a full score with the same time complexity(but in my solution the extra logarithm arises from a binary search). I know how to get rid of it, so
O(N * sqrt(N))is possible.Could you briefly explain your approach? I tried reading the editorial on Hackerrank, but it didn't make any sense as how to do solve the problem in O(N*sqrt)
Something like that:
Let's call a set heavy if its size is larger than
sqrt(N).For each heavy set, we can precompute its intersection size with all other sets.
To add something to a light set, we iterate over all its elements and perform point updates. Then we need to make updates to heavy sets.
To get an answer for a light set, we iterate over all its elements and also take into account all heavy sets updates(using the precomputed intersections).
To add something to a heavy set, we update its
addvalue.Answering a query for a heavy set involves a summation of updates for other heavy sets and its internal
sumvalue.A range update is just a range update and some changes to heavy sets.
Answering a range query requires getting a sum of the range and adding all updates for heavy sets.
How to do it quickly? Precomputing intersections of heavy sets with all other sets allows to process a pair of sets in
O(1). An intersection of a heavy set and a range can be found inO(1)using prefix sums(I used binary search here during the contest). Now the most important part: range sum and range updates. Instead of using a segment or a binary index tree, we will use an sqrt decomposition(by dividing the array intosqrt(N)blocks). It can handle point update and point sum queries inO(1)(it is necessary for processing light sets inO(sqrt(N))) and range update/sum inO(sqrt(N)).Almost the same here, but I tried different boundaries to divide subset into heavy and light, turns out 317 gets 82 pts and 200 gets 91 pts. Really interesting.
So I coded five sqrt decomposition codes in a day, two on IPSC, three on EpicCode. That must be something right
Did you get away with all of them?
Yep, except the one problem on IPSC, though I spend hours optimizing them
Can't stop thinking about my sqrt-decompositions being too slow for HackerRank! That time limit always gets me. Nevertheless, problems were great, it was a pleasure to solve them.
By the way, when information about acquiring the prizes will be available? For instance, "$100 of Amazon credits" is puzzling me.
Roughly in <=2 weeks you will get an email about claiming AWS 100$.
how companies select candidates for interviews? Any chance to get interview out of first 100 people? (namely I finished at 167 place)
I believe it doesn't really matter. They look for good CVs, not for exact places.
They will contact you on their own, position increases chances but there is no cutoff.
I wrote to support already, but I think I may get an answer here faster.
I selected the checkbox to be contacted, but still get a message on top of the page saying:
"Click here and select the checkbox 'HackerRank can share my name and email address with contest sponsors' at the bottom of the page, to connect with 16 awesome companies offering exciting career opportunities."
When'll you send a T-shirt? That's important for me, cause I'm living in Russia, but I'll get rest in Belarus during summer.
Actually, they didn't send anything to Russia at all for a while
Do you mean that Hackerrank doesnt send anything to Russia?
Well, I don't know current situation but that was true few months ago.
I was in top-100 in recent Indeed-smth challenge, and they didn't even asked for my postal address. Also no sign of $100 on AWS account.
In indeed-prime challange I was in top-100,and they messaged me:
Congrats — Claim Your Prize!
and in message they are explaining their things about marketplace, nothing about prize :)
That will be in a separate email. We don't take address, but send you a link to claim T shirt.
Do we need to be "authorized to work in the US" to get the prize? (for indeed prime challenge)
No, prizes are irrespective of anything. You can be a student, a professional anything
It was mentioned in the rules for indeed prime challenge
Yeah Indeed was different.
There has been trouble sending Tshirt to Belarus and Russia. We try to resolve that by sending to any alternate contact in USA for example.
Will still try and find a solution to this problem.
What about sending Tshirt to Ukraine?
that is possible.
Trouble is in Belarus, Russia, Argentina.
What kind of trouble do you have with sending T-shirts to Belarus? Few months ago I recieved T-Shirt from India (not hackerrank).
Our Vendor says it's not possible. I am trying to have different Vendor very soon and will ensure no one is missed out.
Can somebody give a hint on "Epic tree" problem. Editorial is not helpful, the only thing I got from it is that you need to split the query into "upper part" and "lower part" and use HLD for both. I figured it out myself that it makes sense to split query into two parts but I was unable to implement the second part using HLD. Namely I mean this part of the editorial:
So I have two questions here. First — how would you make this update given that each node has it's own size and you need to sum the values multiplied by unique size for each node?
And secondly:
Given you have a HLD which can answer sum queries on the path, how would you query "sum over subtree" then? My only idea is to put all HLD paths into same array in DFS order so that those branches in total will occupy a contiguous range in the array so you can use segment or Fenwick tree to sum things up. Looks a bit more complicated than the HLD I used to implement before, is it the intended solution here?
Instead of updating the nodes/subtrees on the path from a to b, we can do three separate updates. First and second start from a and b respectively, and finish at the root. The third one is similar but it starts from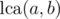 , and we update - 2t instead. For the "upper part" queries we must update all nodes on the path to the root, but for the "lower part" queries, we only need to remember how much it got updated with an integer fi, and increase it by t or - 2t.
, and we update - 2t instead. For the "upper part" queries we must update all nodes on the path to the root, but for the "lower part" queries, we only need to remember how much it got updated with an integer fi, and increase it by t or - 2t.
Denote P(u) as the sum we would get, if we walk from u to the root, and add the subtree sizes of each node we encounter . This is similar to the idea of prefix sums, and is needed for handling the "lower part" queries, as we are required to calculate the following sum for each query on the "lower part" of u:
Calculating this sum can be done with two segment trees storing P(v)·fv and fv respectively.
HLD can answer the query over subtree, HLD is a DFS order, so all the node of a subtree occupy a continuous range(U already knew that :) ).
And for Ur second question, we update a segment on segment tree, we don't care about the size of each node in the segment, since we are adding the same value to all of them and we want the sum of a segment in segment tree. So we can store the sum of size of all the mode in a segment and the value we add to the segment, then we know the answer is sum of size multiply by sum of value.
I am the setter of Epic Tree challenge. First, you are right about that part of editorial. I have tried to explain how to do such update with segment tree, but I could not manage to do it. It is hard to explain, but you can check my implementation. It is easier to understand in that way.
Secondly, When you traverse the tree with DFS you get an order of the tree. Let's call it DFS order. With DFS order you can do HLD. In the meantime you guarantee that all nodes in the subtree of node X has contiguous numbers. So you can easily query that subtree.
Is there a link/cut tree solution?
I do not know one, but there could be.
Yeah, turns out all I had to do is to leave that problem overnight and sleep well. While sleeping I gave it a thought and it looks much easier now. As far as I can see the main idea for this query with different sizes is similar to how I implement "add number on the range" with segment tree, while calculating the sum you push down values added on top and at the end multiply them by the total size.
Thanks, nice problem.
can anyone please explain how to use kadane's algorithm in this question https://www.hackerrank.com/contests/epiccode/challenges/white-falcon-and-sequence .i could not decipher much from the editorial . thank you.
Recurrence relation of Kadane's algorithm is Fn = Arn + max(Fn - 1, 0). It gives the value of maximum sum of segments that end at index n. However, this problem asks for the value of 2 segments not 1, so recurrence relation is not the same but really similar: Fl, r = Arl * Arr + max(Fl + 1, r - 1, 0). Fl, r is the maximum value of 2 segments where left one begins at index l and right one ends at index r. Then, you need to get maximum of Fl, r for different (l, r) pairs.
Here is my code.
The only different thing in the editorial is that the implementation is bottom-up.
I solved 6 problems:
perfect hiring O(N)
begin-end O(N)
dance in pairs O(2 * N*log(N) + N)
white falcon and sequence O(n * n) with DP
line segments O(2 * N * log(N)) sort + segment tree
square array O(Q*log(N)) with segment tree
I could not solve the problems set queries and epic tree
Can anyone tell me, how can solve this two problems.
Sorry for my poor english!
Thanks for all
MY CODE FOR ALL PROBLEMS.
All except set queries problem get full scores. I got 91 pts on set queries.
code This is my solution for LINE SEGMENTS can somebody tell me why this gets me only 8.88 points. This is a very short code . simple sorting + LIS using lower_bound. Thank you
I found a very similar solution . my low score was because I was not using comparator . like this code it . Isn't normal sorting according to the rules made by this comparator ? Help me :(
Consider this case :
Your code sorting produces (1,4), (1,5). The one with comparator produces (1,5), (1,4)
Did anyone receive promised $100 of AWS credits?
yes. You should've received email from hackerrank with link "Redeem your $100 worth of AWS Services here by July 12th"