


Educational Codeforces Round 1 is over. During 24 hours after coding phase many of you tried to hack other's solutions. And it were many successful hacks!
It was 573 successful hacks, made by 101 hackers. Here are most effective:
| # | Hacker | Number of succ. hacks |
|---|---|---|
| 1 | yashkumar18 | 36 |
| 2 | halyavin | 31 |
| 3 | TrungPhan | 26 |
| 4 | Orenji.Sora | 25 |
| 5 | ykaya | 24 |
| 6 | NotPassedCET4 | 23 |
| 7 | greencis | 22 |
| 8 | kondranin | 20 |
| 9 | Allanur | 19 |
| 10 | bayram98 | 18 |
| 11 | waterfall | 17 |
| 12 | kalimm | 17 |
| 13 | muratt | 13 |
| 14 | lifecodemohit | 11 |
| 15 | hnust_zhaozhixuan | 11 |
| 16 | BigBag | 11 |
| 17 | Luqman | 10 |
| 18 | choosemyname | 10 |
| 19 | White_Bear | 10 |
| 20 | liao772002 | 9 |
Thank you! Now I'm pretty sure that tests of this problems are really complete. Moreover hacks shown that writer's tests are often incomplete. In short, it seems it was really good idea to make open hacks phase.
I'd like to crowdsource editorial for such rounds. Please, write in comments if your are ready to write/improve a editorial for problems C-F. For sure, you should solve problem to help with editorial.
Please, write in comments your feedback. It is very important for us to get it. Thanks!







The idea of educational rounds is very good, i think many div2 users will learn a lot from this rounds.
Thanks for this type of rounds.
eagerly waiting for Educational Codeforces Round 2 :) I think it was really a great idea :) thanks mike :)
Nice round though. Looking forwards to Educational Round #2 :)
Is it possible to extend this idea to normal round? It's ok if the in-contest result are kept the same (and used to update rating). But for training purpose, I believe it's better if we can have improved tests. On many occasions, it was found after the round that test data is weak and it seems no one does anything about it.
It was so interesting for me. Maybe next time it should be rated. xD
I think I would also like to see data on each problem and the amount of hacks it received.
Can someone please explain how to solve the 3rd question?
I sorted all the vectors according to the angles they make with the X-axis, and then just checked the angles between consecutive (sorted) vectors, and also checked the angle between the first and last vector at the end.
But, I'm getting Wrong Answer for the test case :
4
-6285 -6427
-5267 -5386
7239 -3898
7252 -3905
I know my logic is right, but how to handle cases where the difference between angles cannot be taken properly in double? :|
I suppose it's better using vector and scalar products (in long long) and not angles themselves...
UPD: http://codeforces.net/contest/598/submission/14261096
And it was better to write on Java :(
I had get WA(Wrong Answer) in that test case too :-| after that I was change all of my doubles too long double and I get AC
Sorry for bad English my English is not good
I've solved the question in java :|
Same Problem Here.Just Change Double to Long Double.
I simply changed all of the double in my code to long double and got AC. This took me an entire day to figure out that long double seems to be a must for this problem. Powerful long double...
if you ues atan2 for sort with double, it can't get right answer. you should use long double instead. moreover this case made by liao772002.
you should use long double
Guys, here is the bug: after someone hacked one of my solutions, I still see on contests page like I solved 4 problems:

Very interesting; 1-day hacks + crowd-sourced editorials. Post upvoted immediately!
problem C : Can someone please tell me why my answer for test case number 127 is wrong ? :\
this is my solution : 14235169
my answer is : 1 2
jury's answer is : 3 4
angels of vectors is :
angel[2] — angel[1] = angel[4] — angel[3] = 0.287916211
:\
change doubles to long doubles
no change ! :(
I have the same problem... Can try not to use standard functions of search of a corner, and it is simple to consider y/x? And to use type of data of decimal (if you have C#)? Excuse for bad English, I translated this text through the translator.
I think my idea for problem C is quite simple and easy to understand.
I split the vectors into 2 sets, vectors with +ve y and vectors with -ve y, then take 2 reference vectors which I chose the vector
( 1 , 0 )and the vector( -1 , 0 ). then I calculate the angle between each vector and the chosen 2 reference vectors. and then sort the vector by their angles between the first reference vector. so the answer will be one of 3 cases.the minimal difference between the angles of 2 consecutive vectors in each set.
the first vector in each set if the sum of their angles less than the minimal angle calculated in 1st step.
the last vector in each set if the sum of their angle "the angle between the 2nd reference vector" is less than the minimal angle calculated in the last 2 steps.
This is my code 14260106 to fully understand the idea.
For test case #119, this is what I can see :
link
It's written that :
v1=1.47669e-008 v2=1.47669e-008and still it's showing wrong answer! is it a bug?
It simply does not print enough decimal places to show that the numbers are different (expected smaller).
thanks for this great idea :)
Who did discover test case #128 in problem C, and how he came up with this evil test case?
and how to avoid double errors in the future? :D
Test 128 is probably one of mine. I just enumerated all pairs of vectors in some area and then sorted all angles between them. Then I looked at all neighbor angles and choose all pairs where the difference is below 1e-15. To avoid precision problems, I used 64-bit integers in calculations — all angles and difference between them can be represented as arctan(p/q). I was only interested in angles less than pi/2, so arctan range was not a problem.
For test 127, I used enumeration for vectors with coordinates less than 100 and then I noticed the pattern in the worst case. So I created the similar test for coordinates up to 10000.
Mother of geometry!! only 30 solutions accepted in C, and 1 in F !!!
Nope. Mother of long double!!
Lesson learned: use long double when you have enough cpu-time and memory. Don`t be cheap...
Solution verdict: WRONG_ANSWER
Checker: v1=0.761852 v2=0.761852
wrong answer Jury answer is better than participant's :-)
Precision inaccurates are sad. It looks like that correct solution have to have "long doubles".
Want to see task F editorial. (btw, nobody solved it during contest)
I would like to see F, too. But also I eager to see proper solution for C, because long double does not work for me. I am pretty sure that's because of some build-in functions that I am using, such as "acos" and "sqrt", but not sure enough about this.
You can see mine. link
You have two problems. First of all usage of
double— just throw#define double long doubleon top of code (or use it properly — defines tend to obscure stuff...). Secondly, never ever hard codePIby yourself. Better useM_PI(though AFAIKM_PIprecision is not defined in standard...) or even betteracos(-1).This may be a dumb question but what was exactly "educational" about this round?
I am personally think that it is perfect idea to create rounds like this. Especially after failure on ACM ICPC, I am able to prepare carefully. I think rounds should and even must go on! I also think that it is good idea to show authors solutions and more rigorously explain solutions and ideas than in usual Codeforces rounds. My thoughts base on the fact that it is generation of young people in Estonia and Ukraine who do not have trainers, therefore, it is one the awesome possibilities to support their eager to be involved in Competitive Programming world. Special thank you for open hacks round, because many weaknesses were found from both sides.
I don't think using float in solving problem c is accurate( including atan2/acos etc.),That's why I use only integers.I'm wondering how is the standard solution written.My solution 14247557
Can someone please tell me what's wrong with my code for:
Problem C: https://ideone.com/OlaPog passed the pretest, then got hacked. Now it is stuck on test 45
Problem D: https://ideone.com/Z0fT1R got TLE on test 10
Thanks.
Problem D: Your 3 nested loops (under long long ans=0) are problem. It can go up to 10^12. In test that your solution fails it is about 10^10 operations. Limit for 1s solution is around 10^8.
My solution for Problem F : main idea is to find where the cutting line intersects with polygon sides.. then we sort those points of intersection by X then Y..the line enters the polygon at the very first intersection point then gets out at the second intersection point then enters again and so one.. so we need to sum lengths of periods inside the polygon and this should be the answer if there's no corresponding lines ,but unfortunately there is :P try to figure out how to deal with corresponding lines ..if u couldn't this my code CODE if u still can't then lets all hope for good editorial because i'm suffering to explain the solution in english :\
There's a problem: The contest area shown that I have solved 5 problems for this round, but actually I have only solved 4 problems (my C got hacked).
Mine is same.
I really think that having a 24-hour hacking period really helps the problem set to gain the best test cases(Perhaps we can extend this to other Codeforces rounds?). After failing several test cases that's well over a hundred, I really do think that the idea to open manual hacking to everyone over a long period of time, and allowing the hackers to copy-paste code for local testing, are undoubtedly the best decisions made on creating this round. It's amazing to see some short test cases but got tons of people WA verdicts. Without a doubt, this is the best way to gain best test cases for contests!
Great round and great rules, cheers!!
Problem C. Editorial.
The author solution works only with integers, so there are no precision problems. Firstly we should sort vectors by quadrants (or by semiplanes). Then we should sort all vectors in quadrants (semiplanes) by cross product sign.
Now we have some answer (a, b) and want to update answer by pair (c, d). Let's consider new coodinate system where vector b matches to x axes: the coordinates of vector b will be (dot(a, b), cross(a, b)) and also we should take cross(a, b) by absolute value, because we need the smallest angle between vectors. Let's do the same with vectors (c, d). The length of vector b can differ from length of vector (dot(a, b), cross(a, b)), but it's doesn't matter.
So now we have two vectors (dot(a, b), abs(cross(a, b))) and (dot(c, d), abs(cross(c, d))) with coordinates at most 108 by absolute value. So we can compare them by quadrants and cross products and update answer.
14264085
P.S.: Validator in this problem is also user only integers and the same comparator.
I'm not allowed to view the context of the link.
I can't view the link either.
Could you tell me why this would get TLE? https://codeforces.net/contest/598/submission/127645132
Two problems:
x*width+yor just don't use hashset/hashmap and just use a 2d array).Nice trick. I wish I'd come up with that. Instead I decided that it is possible to compare the angles by comparing there respective cos. The bigger the cos, the smaller the angle. And cos(a,b) = dot(a,b)/|a||b|. |a| contains sqrt, so instead we can compare sign(cos(a,b)) * cos(a,b)^2. This way we will no longer need doubles. The only problem is that numerator would be of order 10^16 and so would be the denominator. Because of this I had to resort to using big integers...
It is possible to compare fractions using only long long if both the numerator and denominator are at most 1016. Instead of clearing denominators and comparing directly, we compare the continued fraction expansions of the two fractions.
We look at the integer parts of each fraction first. If they are unequal, then we know which is larger. Otherwise, we can discard their integer parts and consider only their fractional parts. To compare these, we take the reciprocals of the two fractional parts and apply this process recursively. (Note the similarities between this algorithm and the Euclidean algorithm---both run in .)
.)
My implementation is here: http://codeforces.net/contest/598/submission/14257824
my solution was wrong just for PI ... WA: 14235457 AC : 14265438 :(
For Problem E:
my approach is to go after
k =min(k, w*h-k)through cutting the current bar from its width(the shorter side) with just rows from height enough for the next bar size to be above the required k by modifying heighth = ceil((float)k/w)and calculating the cost in my way.why this greedy approach fails?
verdict: WA on test 2. solution: 14270061
I hope there will be an editorial eventually .
101 people..? That's kinda unusual number lol.
For problem B: the constraints where small enough for brute-force, resulting in an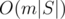 solution, but this problem can be solved in
solution, but this problem can be solved in 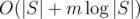 expected time using an implicit cartesian tree, which would allow inputs with m, |S| upto, say,
expected time using an implicit cartesian tree, which would allow inputs with m, |S| upto, say, 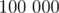 . Here is my accepted solution: 14232624.
. Here is my accepted solution: 14232624.
Of course we know about faster solution.
Sure, but since the editorial is being crowd-sourced I thought I'd post it for other people.
Eagerly waiting for the editorials. When will it be posted?
Is there any update about the editorial ?
where is the editorial ? can someone plz give me the link for editorial I m not able to solve the problems.
https://codeforces.net/contest/598/submission/42694507 Somehow I use disjoint set in problem D, I've got TLE in test #23. Could anyone explain for me.
My idea : Using disjoint set to find connected components in the graph. While unifying disjoint set together I calculate the number of pictures of each component, which is the sum of the number of pictures in each cells.
Unfortunately I wasted a lot of time on problem (C), don't make the same mistake I did: you may know both formulas
$$$\lvert u\cdot v \rvert = |u||v| |\cos\theta|$$$
$$$\lvert u\times v \rvert = |u||v| |\sin\theta|$$$
And theoretically you could use either of them to distinguish between angles. However if test cases 1xx are giving you wrong answers due to floating point precision, then it will be wise to choose one over the other; as an example, let $$$\delta, \epsilon$$$ be very small angles like .0001 and .0002. Then it seems we can tell that $$$\delta<\epsilon$$$ either using $$$\cos\delta >\cos \epsilon$$$, OR because $$$\sin \delta < \sin \epsilon$$$. However one of the functions $$$\sin$$$, $$$\cos$$$ is much better, and that's because of derivatives. Notice that $$$\cos$$$ is very flat near $$$0$$$, while $$$\sin$$$ is almost the maximum steepness. So computationally it will be harder to use $$$\cos$$$ to tell which is bigger. Similarly if you are dealing with two angles near $$$\pi$$$. So in those cases it is better to use the cross product.
On the other hand, cross product is not always safe! The writers could also force a precision error by having 4, $$$u,v,w,z$$$ which are very small perturbations of the 4 main directions. In that case, $$$\cos$$$ would be better at detecting small differences.