


616A - Сравнение длинных чисел
Замечу, что в этой задаче решения, использующие стандартные типы длинной арифметики (класс BigInteger в Java, стандартные длинные числа в Pyhon) не должны проходить. Это связано с тем, что они хранят число не в десятичной системе счиления и соответственно при создании длинного числа происходит его конвертация из десятичной системы счисления, которая является тяжёлой операцией и работает обычно за O(n2), где n — длина числа.
Для решения задачи можно просто добавить лидирующих нулей к более короткому числу, а далее сравнить, получившиеся строки в лексикографическом порядке (алфавитном).
Сложность: O(n).
616B - Ужин с Наташей
В этой задаче нужно было сначала найти в каждой строке минимум, а далее взять максимум, получившихся минимумов. Это соответствует стратегии Павла и Наташи.
Сложность: O(nm).
616C - Лабиринт
Давайте сначала пронумеруем все компоненты связности, запомним для каждой её размер, а также для каждой свободной клетки запомним номер её компоненты. Это можно сделать с помощью одного обхода в глубину. Теперь ответ для непроходимой клетки будет равен единице плюс размеры всех соседних различных компонент. Соседних в смысле компонент всех соседних клеток (в общем случае четырёх).
Сложность: O(nm).
616D - Наидлиннейший k-хороший подотрезок
Эту задачу мы решили дать поскольку на страницах Codeforces часто видим вопрос "Что такое метод двух указателей?". Эта задача является типичным примером задачи, решаемой этим методом.
Будем искать для каждой левой границы l наибольшую границу r такую, что отрезок (l, r) k-хороший. Заметим следующее: если некоторый отрезок (l, r) k-хороший, то отрезок (l + 1, r), тоже является хорошим. Таким образом, поиск максимальной правой границы для левого конца l + 1 мы можем начинать с максимальной правой границы для левого конца l. Далее просто будем поддерживать в массиве cntx для каждого числа x количество его вхождений в текущий отрезок (l, r), а также количество различных чисел. Будем пытаться двигать правую границу пока можем, далее двигать на единицу левую границу. Итого два указателя l, r вместе передвинутся 2n раз.
Сложность: O(n).
616E - Сумма остатков
К сожалению в этой задаче в моём решении происходило переполнение. Ошибка была исправлена во время соревнования, надеюсь это не сильно убавило вам удовольствие от решения этой задачи, поскольку она мне кажется очень интересной и красивой (идея решения, конечно, является известной для искушённых пользователей).
Сначала преобразуем сумму, которую нужно посчитать 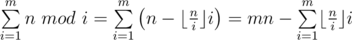 . Также заметим, что последнюю сумму можно суммировать до min(n, m), поскольку при i > n все слагаемые будут равны 0.
. Также заметим, что последнюю сумму можно суммировать до min(n, m), поскольку при i > n все слагаемые будут равны 0.
Заметим, что в последней сумме либо 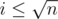 , либо
, либо 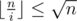 . Будем аккуратно суммировать эти два случая так, чтобы ничего не посчитать два раза. Первую сумму посчитать легко, просто нужно пройти циклом по всем таким i. Вторую сумму будем считать отдельно для всех различных значений
. Будем аккуратно суммировать эти два случая так, чтобы ничего не посчитать два раза. Первую сумму посчитать легко, просто нужно пройти циклом по всем таким i. Вторую сумму будем считать отдельно для всех различных значений 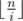 . Для этого во-первых нужно определить при каких i значение
. Для этого во-первых нужно определить при каких i значение 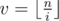 будет достигаться. Легко видеть, что это полуинтервал
будет достигаться. Легко видеть, что это полуинтервал 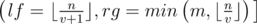 . Также нужно понять, что сумма вторых сомножителей в
. Также нужно понять, что сумма вторых сомножителей в 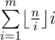 при постоянном первом сомножителе легко считается за константное время — это просто сумма арифметической прогрессии
при постоянном первом сомножителе легко считается за константное время — это просто сумма арифметической прогрессии 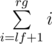 . Таким образом решение работает за
. Таким образом решение работает за 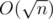 .
.
Сложность: .
616F - Дорогие строки
Эта задача была предложена и подготовлена Григорием Резниковым vintage_Vlad_Makeev. Его решение использовало суффиксный массив.
Вообще задача является типичным примером задачи на суффиксную структуру. Четверо из пяти участников сдавших задачу в основное время соревнования использовали суффиксный автомат, один использовал суффиксное дерево. Моё решение использовало суффиксное дерево, поэтому я расскажу решение с деревом (оно мне кажется простым, не считая построения самого дерева).
Построим новую строку, расположив друг за другом все строки из набора, разделив их различными разделителями. Количество разделителей порядка O(n), поэтому алфавит в суффиксном дереве тоже порядка O(n). Соответственно нужно использовать map<int, int> для хранения дерева и в асимптотике выходит O(logn). Построим для получившейся строки суффиксное дерево. Поставим в соответствие каждому разделителю строку слева от него. Теперь запустим на этом дереве обход в глубину, который никогда не переходит через разделитель и возвращает сумму цен строк, соответствующих множеству разделителей в поддереве вершины обхода в глубину. Легко видеть, что ответ это просто произведение глубины текущей вершины на сумму в поддереве этой вершины.
Сложность: O(nlogn).







А в задаче F существенно, чтобы разделители были различные?
Вообще да в подобных задачах всегда нужно ставить различные разделители. Например, здесь может возникнуть такая проблема. Есть у нас две одинаковые строки "abaca", "abaca". Мы сгенерировали строку "abaca#abaca#". И вот встречаем мы в дереве "#" и не знаем какую строку она обозначает, соответственно не знаем какую стоимость нужно дать. Не уверен, что это можно сделать с одинаковыми разделителями.
Допустим, такой вариант: сделать дерево явным (чтобы у каждого суффикса была выделенная вершина), а потом в каждой вершине суффикса добавить ту стоимость, которая соответствует строке, в которой он начался. Тогда при обходе уже не нужно ориентироваться на разделители, а только на инициализированные суммы в вершинах.
Кажется ты прав. Можно и так.
the equation in second sentence in solution of problem E why m*(m+1)/2 ?? I think it should m*n
me too.
Thanks. Fixed it.
Эх, мои мысли по задаче С были ровно такими же, как в этом разборе. Жаль, что за полтора часа до конца контеста я сдался(
Problem E is indeed a nice one I think, which helps me find that what a stupid ACMer I am..:P But fortunately, I learn a lot from this problem. Thank you!
Problem E is indeed a nice one I think, which helps find what a stupid ACMer I am. :P But fortunately, I learn a lot from this one. Thank you!
Скажите пожалуйста, как задачу F решать суфмассивом?
Скорее всего, в каждый суффикс записать число ci, а потом найти подотрезок, максимизирующий lcp(i, j) * sum(i, j). Наверное, кроме этого можно использовать, что нас интересует только O(n) отрезков (они соответствуют вершинам в суфф дереве), но я не настолько знаю суфмас, чтобы сказать, как их просто определять.
Построим суфмас, насчитаем LCP.
Теперь будем перебирать длину строки от большей к меньшей. Зафиксировали некоторую длину(то есть мы рассматриваем префиксы некоторой длины всех суффиксов). Тогда у нас есть активные(которые можно брать) и неактивные(чья длина меньше зафиксированной) суффиксы.
Активные суффиксы разбиваются на классы по равенству префикса зафиксированной длины. При этом на суфмасе эти классы являются отрезками суффиксов(если по краям LCP >= x, то внутри-то точно). Получается, для каждой длины, ответ — это (самый_дорогой_отрезок) * длина.
Отсюда, идя по уменьшению длины, у нас есть 2 типа событий: некоторый суффикс стал активным и 2 класса объединились. Для реализации можно использовать, например, 2 сета — в одном отрезки упорядочены по левой границе(для добавления/объединения), а в другом по стоимости(чтобы брать лучший).
Код: 15315527
Спасибо. Не догадалась от большей к меньшей перебирать.
Problem E was a better modified version to the problem www.spoj.com/problems/SUMPRO
Problem F could be done with suffix array or just with suffix automaton or with the suffix tree?
Yes.
Can someone explain the solution for problem F using suffix array.
Concatenate strings and build suffix array and build lcp table. Answer will be max value of "min element of lcp table in [L + 1, R]" * "sum of ci in [L, R]". Note that we can't try all [L, R] because there is a chance that we won't add some ci. If we think lcp table as histogram, we can only try rectangles which isn't cover by another rectangle. There is only O(LEN) pairs of [L, R] so we can try all of them. Here's my code.
O(N * log2(N)) : http://codeforces.net/contest/616/submission/15309183
O(N * log(N)) : http://codeforces.net/contest/616/submission/15309267
Problem C java tle
http://pastebin.com/E91JSjsV
my soln seems to be same as the one in editorial any inputs?
I think, it's because of adding strings when constructing answer (lines 56 & 86). As I know, it's expensive operation :) For example, try to add 1000000 digits to string.
Used printwriter in place of system.out Passed 13-14-15 Tle at 16 now Any other way to o/p large strings in java ?(with newline) Or create them without concatenation?
You can use StringBuilder. I believe that it's much faster than simple String concatenation.
StringBuilder worked thanks !!
Problem D can also be solved by a Regular Sliding window technique and Binary search on the length.
Problem D can also be solved by a Regular sliding Window technique and Binary search on the length.
I solved it using just sliding window technique, no binary search
Someone please guide me where should I learn Suffix arrays and Suffix trees from.
Somebody can please clarify the meaning of this line of code of the solution for E?
I didn't understand why you multiply
n(n+1) * (mod+1)/2[the mod part]. Usingn*(n+1)/2and then aplying% modwould be equivalent?(mod + 1) / 2 is inverse element for 2 in the field modulo mod.
UPD: For odd mod.
Thank you so much! I'm going to search and try learn more about that
Возможно ли решить задачу D при помощи бинарного поиска?
На контесте пытался решить при помощи него, построив массив частичных сумм, но понял, что правило включений-исключений тут не работает. Как надо делать правильно? (в тегах к задаче есть БП)
Можно. Бинпоиском надо искать длину подходящего отрезка, а при фиксированной длине отрезок можно найти за 1 проход по массиву.
Can someone tell me what is the difference between declaring a function as 'inline void' instead of just 'void'? Thank you.
You can refer to google with key words "c++ inline".
My code for problem A: http://pastebin.com/fYTUiV1P
I got TLE on problem A on test 20. Can somebody help me with that? I used PrintWriter and BufferedReader in my code but still got TLE.
Thank you so much.
Your algorithm is O(N^2) because insert in StringBuilder can't possibly work faster than O(N).
Nice trick To calculate (x/2)%mod, I used to think inverse modulo would be the only way to do this, but this can be easily fashioned as ""(x*(mod+1)/2)%mod"", as (mod+1)%mod = 1 and mod is an odd prime number.
I followed the problem B's editorial, but still got wrong answer in test case 9. could anybody please verify? (http://codeforces.net/contest/616/submission/15829627)
Swap n and m in array declaration.
How can I solve F using Suffix automaton? note: I don't know the code all people used to solve this problem, I only know the traditional one found on e_max.
has anyone did D using binary search? i am getting TLE for case 12.
First 4 problems were easy
Am I learning ?
we are EduForces, Whether one likes it or not, its our job to screwup problems so that you unscrew up the problems