


25 февраля 2012 года в 12:00 по Москве состоится Восьмая индивидуальная олимпиада на сайте http://neerc.ifmo.ru/school/io/index.html . Задачи теперь с feedback. Подробнее будет указано в условие задачи(что-то мне подсказывает что будет работать только через web-client). После окончания олимпиады предлагается здесь обсудить задачи.
→ Обратите внимание
До соревнования
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
4 дня
Зарегистрироваться »
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
4 дня
Зарегистрироваться »
*есть доп. регистрация
→ Трансляции
→ Лидеры (рейтинг)
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
→ Лидеры (вклад)
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | maomao90 | 163 |
| 2 | Um_nik | 163 |
| 4 | atcoder_official | 161 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | nor | 153 |
| 9 | Dominater069 | 153 |
→ Найти пользователя
→ Прямой эфир






Codeforces (c) Copyright 2010-2024 Михаил Мирзаянов
Соревнования по программированию 2.0
Время на сервере: 19.11.2024 12:30:01 (f1).
Десктопная версия, переключиться на мобильную.
При поддержке

Как решалась D на 100?
D — это поздача задачи H с открытой олимпиады и немножко случаев. Только 1 часа на неё мне внезапно оказалось мало :)
Если кратко: найдём двумя указателями касательные к многоугольнику для каждого человека. Если дверь лежит по эту сторону, то ответ — расстояние до неё, если по другую — переберём, через какую сторону пойдём, добавим длину пути по соответствующей касательной, а расстояние между вершинами многоугольника легко вычисляется за O(1) (с линейным предподсчётом).
Расскажите решение всех задач, пожалуйста.
Сильно интересует 6-й тест задачи D, первой группы.
Как решать B, C не в лоб? Полконтеста над ними думал, так ничего не придумал. Есть идея в С решать деревом отрезков с хранением подмассива в вершине? Подскажите если кто умеет быстро решать...
B, кратко идея за линию: 1)Порядок операций неважен 2)Один человек является концом максимум для одного запроса 3)Храним ответ в двусвязном списке 4)Научимся решать для подотрезка (в изначальном массиве) за линию. Если в первый элемент — не крайний, свелись к меньшему и дописали в начало. 5)Если первый элемент — крайний для чего-то, свелись к двум меньшим (внутренность и остаток). Теперь поменяли у внутренности местами начало и конец. У нас изменится смысл next/prev, ну да ладно — он однозначно восстанавливается при обходе. Сконкатенировали внутренность и остаток.
Б видимо можно так: у нас не играет роли в каком порядке мы делаем реверсы
ну тогда отсортим отрезки по длине (чтобы после реверса границы больших отрезков оставались прежними ai = apos bi = bpos и будем делать обычным декартовым
C — решение за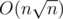 (можно чуть проще за
(можно чуть проще за 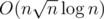 ). Посмотрим на кандидатов, которых больше
). Посмотрим на кандидатов, которых больше  . Таких мало — предподсчитаем для них суммы на префиксах и для каждого запроса прорелаксируем "в лоб". Теперь разберёмся с остальными. Сгруппируем запросы в "корзины" по левым границам, каждая корзина захватывает
. Таких мало — предподсчитаем для них суммы на префиксах и для каждого запроса прорелаксируем "в лоб". Теперь разберёмся с остальными. Сгруппируем запросы в "корзины" по левым границам, каждая корзина захватывает  бюллетеней. Отсортировали запросы в каждой корзине по правой границе. Теперь двумя указателями двигаем отрезок: правый двигается только вправо, а левый — не более, чем на
бюллетеней. Отсортировали запросы в каждой корзине по правой границе. Теперь двумя указателями двигаем отрезок: правый двигается только вправо, а левый — не более, чем на  . За O(1) пересчитываем количество каждого кандидата и еще за O(1) мы можем пересчитывать количество кандидатов с таким количеством голосов. Так как мы уже учли кандидатов, у которых более
. За O(1) пересчитываем количество каждого кандидата и еще за O(1) мы можем пересчитывать количество кандидатов с таким количеством голосов. Так как мы уже учли кандидатов, у которых более  голосов, то мы можем "в лоб" за
голосов, то мы можем "в лоб" за  прорелаксировать для каждого запроса.
прорелаксировать для каждого запроса.
не очень понятно, что значит левый указатель двигается не более чем на N * sqrt(n)
p.s. насколько я понял у вас N — количество бюллетеней, n — количество запросов?
Внутри каждой корзины левые границы запросов отличаются не более, чем на . Поэтому в худшем случае левый указатель передвинется на
. Поэтому в худшем случае левый указатель передвинется на  за обработку одного запроса.
за обработку одного запроса.
Они одинаковы, поэтому всё равно. Везде стоит читать как n
Спасибо, за подробное объяснение =) насколько я понял получается что в каждой "корзине" мы храним все запросы начинающиеся в текущем блоке длины sqrt(n), сортируем запросы по возрастанию правых концов и получается наш правый указатель в каждом блоке пройдет суммарно не более N. И тут же появляется вопрос как быстро брать ответ? Я только понимаю как set'ом или деревом отрезков по сжатым кандидатам? Можно ли как-нибудь за O(1) или я что-то не так понял?
Да, всё так. Фишка в том, что если будет set или дерево отрезков — будет долго. Зайдёт, наверное, но можно за O(1).
Изначально сожмём координаты. Заметим, что никакой кандидат не встретится более раз (иначе мы его обработаем в предподсчёте). Храним две вещи: массив (кандидат => сколько раз был, длины n) и обратный к нему (сколько раз был => количество таких кандидатов, длиной
раз (иначе мы его обработаем в предподсчёте). Храним две вещи: массив (кандидат => сколько раз был, длины n) и обратный к нему (сколько раз был => количество таких кандидатов, длиной  ). Пересчитываются оба за O(1). Ответ извлекается за
). Пересчитываются оба за O(1). Ответ извлекается за 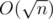 для каждого запроса — пробежались по обратному массиву. Итого — избавились от логарифма set'а/дерева отрезков.
для каждого запроса — пробежались по обратному массиву. Итого — избавились от логарифма set'а/дерева отрезков.
А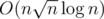 заходило тут? Я так понимаю, это SQRT-декомпозиция запросов + куча?
заходило тут? Я так понимаю, это SQRT-декомпозиция запросов + куча?
Я сначала написал такое, только не с кучей, а с деревом отрезков. Работало 10 сек примерно.
А зачем отдельно считать для тех кого больше корня? Можно-же пересчитывать за О(1) максимум если число только на 1 увеличивать/уменьшать.
Можно было легче решать за линию рекурсивно. Идем, пока не встретим конец какого-либо отрезка. Когда встретили, запустились от конца этого отрезка, но идем в сторону, обратную той, в которую шли до этого. Собственно, и вся идея.
Отлично — первые 47 минут контеста решал не те задачи а в А не дал unsigned long long!
Насколко я понимаю, вот результаты (но не всегда почему-то показывает)
результаты Not found.
ну они сначала были, потом всплыли
оказывается в С и Д тесты последней группы оцениваются пропорционально пройденому... как я так не прочитал это(