


Всем привет!
Приглашаю вас поучаствовать во втором раунде Яндекс Алгоритма, который состоится завтра в 21:00 по Москве. Этот раунд был подготовлен мной с огромной помощью GlebsHP. Хочу поблагодарить Chmel_Tolstiy, snarknews и Gassa за их поддержку и советы во время подготовки, а также всех сотрудников компании Яндекс, которые тестировали набор задач.
Good luck and have fun!
Ссылка на вход в контест появится здесь, как только я сам её узнаю :)
UPD: как мне подсказали, войти в контест можно будет здесь: https://contest.yandex.ru/algorithm2016/contest/2540/enter/
UPD2: Спасибо за участие, надеюсь, вам понравились задачи! Результаты будут доступны в ближайшем времени. Я бы хотел запостить разбор, но он что-то не собирается на Codeforces, и я сейчас пытаюсь побороть эту проблему.
UPD3: Поздравляем победителей:
Опубликована предварительная pdf-версия разбора: http://codeforces.net/blog/entry/45354. Продолжая традицию сопровождать разбор интересными вопросами, связанными с задачами, я подобрал несколько и в этот раз. Приглашаю вас над ними подумать.







There is no way to participate for those who didn't took part in previous rounds, am I right?:(
Unfortunately there is no way to participate during the contest for those who didn't qualified.
Though after each round is held, it becomes available for participation on http://contest.yandex.ru. We will also, most probably, publish archives containing test data and all materials of all rounds in the nearest future.
Why is there no mirrors on CF? I don't know how difficult to make mirror but think it should be simpler than make new round from scratch (in this case CF get all problems for free).
Darn, it overlaps with first match of Euro : /.
Yep, I'm choosing a nice bar with live football to conduct the contest from there right now :)
Sorry for that, I couldn't do anything with the time of round.
I can send you messages about goals via testing system :D
At least we will be able to watch second half. What is worse is that DCJ overlaps with first match of Poland ;__; (also first half)!
Easy, just quickly solve all problems.
Easy, when you know how.
Thank for sending me notifications about all of the goals ;).
I had an opened tab with text footage of the match but they didn't give me an option :)
Don't forget to participate!
Была ли регистрация к раунду ? Было бы лучше если её открыли во время контеста.
Её не было и не будет. Регистрация была на участие в квалификационных раундах, которые уже прошли.
Thanks for making the system fast and stable this time. :)
How to solve C?
I used bruteforce. Code.
Notice that for integer a number of used banknotes is
(all divisions are done in integers).
It can be rewritten as
So we need to maximize the subtrahend
This can be done with DP.
Code.
Well... it is kind of the backwards sieve of Eratosthenes, isn't it?
An N log N DP solution:
We'll pick coins from smaller to bigger. Suppose we already picked some coins and the biggest of them is A. We used coins <A to make all prices divisible by A. dp[A] is the minimum number of coins used to do so. dp[A*k]=min(dp[A*k],dp[A]+sum(price[i]/A%k)).
6 years ago I wrote the same problem: https://community.topcoder.com/stat?c=problem_statement&pm=10569
Yes, d1 med was easier at that time.
Ouch : \
It's funny that I wasn't able to solve the problem back then, but it was a piece of cake today (I didn't remember it at all).
The other way around would be funny ;)
http://petr-mitrichev.blogspot.com/2015/10/a-week-with-old-self.html
I solved it 6 years ago, but WA today... (somehow I thought k and n are the same variable)
BTW, consider the other version of the problem I've came up with before this one. It is formulated in my editorial. Are you able to solve it efficiently?
Как решать шизофренические суммы?
Ответ — это количество путей по сетке идущих вверх или вправо до какой-то точки вида Ax + By = C. Динамика dp[C] = dp[C - A] + dp[C - B], свертываем в матрицы.
Предполагаю, что можно также предположить, что мы считаем количество разбиений отрезка длины C на отрезки длины A и B и запустить рекурсию с запоминанием по параметру C, перебирая, каким отрезком занята центральная клеточка и как расположен этот отрезок. Вроде должно обработаться порядка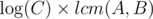 состояний. Правда, у меня пока WA 25.
состояний. Правда, у меня пока WA 25.
Я решил A, B, Е, не решив C и D.
Что со мной не так?
И расскажите пожалуйста как решать C =(
я писал ДП
dp[i][j] — ответ если i-ое число равно j. Идём с конца и для каждой ячейки поддерживаем то сколько нам надо ещё оплатить. Ответ очевидно в dp[1][1]. размер dp 20 на max(a[i]) т.к. иметь купюру большую чем стоимость любого товара нам не нужно, а 20, т.к. одинаковые купюры нам не нужны, т.к. любую и так можно брать сколько угодно раз, a минимальное число для X, которое кратно Х это 2*Х, то есть купюр максимум будет log2(max(a[i])). дальше есть свойство что
n/1 + n/2 + n/3 + n/4 + ... = nlog(n). из этого выходит асимптоматикаlog2(max(a[i])) * max(a[i]) * log2(max(a[i])) = log(max(a[i]))^2 * max(a[i]).CODE
How to solve B?
Write L and R in binary form.
Now the problem can be solved independently for each bit: you need to calculate for each bit how much there will be nums in [l, r] with this bit set and unset. And then select the bit value, based on this info.
How to count how much nums in [l, r] with such bit set? Traditional trick: it is count in [0, r] — count in [0, L — 1].
So how much nums in [0, r] with i'th bit set? let r = A C B (where A value of highest bits, c value of i's bit, B value of lower bits) It is A * 2^i + c * (B + 1).
(At first consider all numbers which are less than A * 2^(i + 1), and then the all other)
In first group exactly half will be good, and in second none will be good if i'th bit unset (c == 0), and all numbers in [A C {zeros}; A C B] otherwise.
How did you calculate the number of nums in [L, R] with this bit set and unset?
I've written second part and updated comment.
I dont know how he did it, but I think it can be done easily using DP on digits with state DP(bit, lower, larger, tofix) which is O(323·2·2·) where bit is the bit we are currently on, lower is {0, 1} denoting whether any previous bit is lesser than the bit in R, and larger is {0, 1} denoting whether some bit has been strictly larger than that of L. tofix denotes the bit we are fixing to be true. After that, it can be solved by using a lot of if-elses. I couldn't get it accepted in contest(WA on #10), but I dont think the DP would be wrong. My transition probably has bugs :/
Is there anything wrong with this approach?
UPD: Damn, extremely overkill :/
Got this strategy but couldn't count how many times it occurs. Can you explain you method to count how many times each bit is set in range [l,r].
For Problem B, finding the number of integers in [L, R] with ith bit set could be used to decide if the required number should have ith bit set or not, to minimize the hamming distance.
So, how do we find number of integers in [L, R] with ith bit set?
Find count of '1' for every position for all numbers from 0 to n;
It's linear in number of digits.
Then you can do F(r) — F(l-1) to find what you need.
We can calculate the number of integers in [0, R] with i-th bit set using the following fact: if we consider consecutive blocks of size 2i + 1, the first half of integers has i-th bit set to zero, and the second half with i-th bit set to one. Therefore, one can come up with simple formula.
That awkward moment when your solution to D fails because of
That awkward moment when the bug in your code is that you forget to return your answer...
an awkward moment when you haven't finished reading A, wrote solution in 5:24, sent it blindly and it obviously failed because it never outputs -1 xD
That's why keep warnings flag on always, same thing happened with me 1 year ago and your's is still int returning function mine was bool returning which doesn't show warning also.
Thanks for the tip.
У соревнования какая-то очень странная система оценки: фиолетовый, решивший 2 раунда по 3 задачи, но не смогший написать 3-й, проиграет из-за штрафа синему, который нашел время прорешать все. Не очень понятно, зачем тогда вообще делать целых 3 раунда.
Эта система плоха только тем, что требует участия во всех раундах — если меньше, то это риск участника. Т.е. затраты времени. Хороша тем, что используется усреднение по трём раундам, целых 15 задач, решённых в три разных захода. Поэтому любые случайные факторы — плохой день / плохая задача / застрял на одной и не решил и прочее — нивелируются. Меньше случайностей => достоверней результат соревнования.
А еще теоретически можно попасть в топ25 в каждом из раундов, и при этом не попасть в топ25 по сумме, если писать все время усредненно :D
Видимо, чтобы понизить элемент случайности, который всегда есть у одного отдельно взятого раунда. Если хочется проходить в финал — стоит всё-таки уделить время на все три раунда. А для футболки, вроде бы, 2 раунда по 3 задачи должно будет хватать.
How to solve D?
ans(C) = ans(C - A) + ans(C - B), ans(0) = 1 and use fast matrix exponentation.
Sum of required f(x,y) is sum of f(x-1,y)+f(x,y-1)
if Ax+By=C, then A(x-1)+By=C-A, Ax+B(y-1)=C-B
so you need to calculate answers for C-A and C-B and sum them
the rest is converting linear recursion to matrix powers
Thanks a lot! It was simple but i turned it into a complicated series of binomial coefficients and could not simplify it :(
Как решать Е? были подвижки, но как-то не добил..
Подвешиваем за 1, выписываем эйлеров обход (в обходе приоритеты), строим простое двумерное ДО на эйлеровом обходе (там где сорченный список в ноде).
Считаем кол-во инверсий для ноды 1 (просто используем ДО), затем учимся пересчитывать при сдвиге корня на одно рёбро в какую-то сторону (Тоже с помощью ДО).
Запускаем DFS и считаем ответ для каждой ноды, делая такие сдвиги.
http://pastebin.com/nWPTCRyb
Для одного корня за NlogN решать просто — запустим дфс, будем хранить в ДО/Фенвике сколько есть вершин с определенным значением на пути от корня к текущей вершине, в каждой вершине посчитаем, сколько инверсий она прибавляет, сделав один запрос к этому Фенвику.
Осталось научиться пересчитывать, что происходит, когда мы двигаем корень из одной вершины в другую. При переходе по ребру изменения затрагивают только два его конца — для вершины, которая была корнем, раньше инверсии считались со всем деревом, а теперь только с каким-то его поддеревом, так что надо посчитать, сколько есть вершин со значением больше текущего в каком-то поддереве графа; для вершины, которая стала корнем, все ровно наоборот. Эти запросы "сколько каких-то вершин в каком-то поддереве" можно перегнать в оффлайн и тоже порешать обычным Фенвиком/ДО по Эйлеровому обходу.
Upd. Код.
Спасибо за идею с Эйлеровым обходом! Вот чего мне не хватало)..
Есть ещё такой вариант (но не писал): осуществить heavy-light декомпозицию и на каждом пути завести аддитивное дерево отрезков с обновлением на интервале, в котором мы будем считать количество инверсий для каждой вершины. Далее, добавляем числа на вершины в порядке убывания. Добавляя очередное число, мы видим, что в каждой ветке в каждой вершине добавилось столько инверсий, сколько уже было ранее добавлено чисел в других ветках. Обновляем информацию с помощью деревьев отрезков на путях.
Я хранил для поддеревьев списки значений вершин в декартовом дереве по явному ключу и мерджил их от меньшего к большему, узнавая для каждой вершины v и каждого ребра из нее вниз в вершину to, сколько вершин в поддереве to больших, чем наша. Также в отдельном массиве складываем эти величины по всем to, а также считаем сумму этих величин по всем поддереве v. Потом считаем количество инверсий вершины v со всеми кроме поддерева v (запрос к итоговому декартову дереву + вычесть сумму в поддереве v), и уже по этой информации можно найти ответ еще одним dfs-ом по дереву (спускаем в вершину сумму количеств инверсий для вершин не в поддереве v, эта величина через полученную информацию легко пересчитывается). Код
Good interesting problems, thanks for the round!
Is there a simple approach for problem E? I have several overcomplicated in mind, however wasn't brave enough to implement any of them.
First, you need to compute, for each vertex, how many vertices with a higher number are there in its subtree (nIni), in each of its childen's subtrees (nChildij), and outside of its subtree (nOuti).
To compute the numbers, first sort the vertices in the order of preorder traversal. Each subtree will be represented by a contiguous interval in this order. Create a Fenwick tree. Process vertices in the order of assigned numbers, and use position in preorder traversal as an index in the Fenwick tree. Then, you will be able to compute how many already processed vertices are in any given subtree in .
.
Then, you can move the root along edges and maintain current number of inversions in O(1) time for each move. Let's call "current root" the vertex you are currently computing the answer for, and "initial root" is the vertex that you used as a root in the previous steps. The answer can be computed as the sum of contributions of each vertex, where contribution of vertex i is defined as:
As you may see, when moving the current root along an edge, only contributions of two vertices may change (ends of that edge). So, the answer can be updated in O(1). Since it is possible to visit all vertices using O(n) such moves, this part takes O(n) time, and the entire solution takes time.
time.
Last round I was afraid to submit anything blindly and because of that I was a victim of wrong tests in C. This round I thought I need to risk ans submit something blindly, so since I was pretty sure of D (it can't not work if it works on samples, right?), so I submitted it blindly and it turned out to be only one of my submissions that wasn't right :|. a=b case xd.
How to solve F?
I've just posted a PDF-version of an editorial: https://yadi.sk/i/1hC1divYsQtTQ
Has somebody encountered WA #18 in problem D? I have no idea what's wrong with my code (linear recurrence -> fast matrix exponentiation).
It is said in the editorial that A = B in that test.
Well, there are smaller tests with the same condition (for example A = B = 100 in test #10), and I did
so it's something different I guess.
Ooops, WA #18 checks int overflow (C >= 2^31). I feel stupid right now. =)
Are there any chances for me to get a T-shirt if I missed Yandex Algorithm Round 2?
If you get to the top 512 competitors — yes, sure. You can track your position here.
How to solve E that fast? I create some BSTs and "merge" them in some way to count the inversion, which leads to an O(n log^2 n) solution. My code is a little bit complicated so I wonder if there's a better solution...
Edit: Well I just saw the editorial. It seems not easy to implement though...
Edit: I saw tonynater's code. Now I know how to solve it :P