


Hello Codeforces!
Japanese Olympiad in Informatics Spring Camp 2017 will be held from Mar. 19 to Mar. 25.
There will be four online mirror contests during the camp.
- day1 : Mar. 20 (00:30 — 05:30 GMT)
- day2 : Mar. 21 (00:30 — 05:30 GMT)
- day3 : Mar. 22 (00:30 — 05:30 GMT)
- day4 : Mar. 23 (00:30 — 05:30 GMT)
The contest duration is 5 hours and there are 3 to 4 problems in each day. Problem statements will be provided both in Japanese and English this year.
There might be unusual tasks such as output-only tasks, optimization tasks, reactive tasks and communication tasks, just like International Olympiad in Informatics (IOI).
Details are available in contest information.
Good luck and have fun!
UPD1:
We will use CMS (customized version) on our server to hold the contests. The registration URL will be announced just before the first contest.
Providing English statements is our first trial for this year, so there aren't past English problems. If you try past problems with Google Translate, you can get them from here.
UPD2:
Registration is available now.
- Contest page : http://cms.ioi-jp.org/contest/
- Ranging : http://cms.ioi-jp.org/ranking/
UPD3:
The contests are over. The judge is open now. You can submit your codes in the contest page.
Unofficial Simple Editorial:
- cultivation: East and West wind have almost the same effect. You don't have to consider the order. The essential value is the sum of the number of east and west wind. The candidates of this value are O(N2). You can easily calculate how many north wind and south wind needed to fill each column. The number of the essential columns are O(N). So you can solve this by O(N3logN) or O(N3) with precalculate.
- port facility: Let's assume the containers nodes and make edges between the nodes which can't put on the same area. If this graph is bipartite, The answer is 2^(#connected compornent). Otherwise, the answer is 0. First, count the connected component. Sort containers and use Segmenttree, then you can BFS with O(NlogN). You can check wheather the graph is bipartite by just simulating the transportation.
- sparklers: The first insights are you can do binary search the answer v, no two persons don't have to burn sparklers simultaneously and burning sparklers looks like an interval. If you can merge [l, r - 1] or [l + 1, r] and (Xr - Xl) / v ≤ (r - l)T, then you can merge [l, r). You can do some greedy algorithm to check you can merge [0, n)
- arranging tickets: Open the circle at point 0. You can use binary search by determining the answer m. You don't have to flip the interval [a, b], [c, d] such that a < b < c < d. So Filipped interval share some point t. Let's determin t and the number of flipped interval n. Actually, the candidate of n is at - m and at - m + 1. ( ai is the sum of initial passengers through point i), the candidate of t is leftmost and rightmost argmax ai. You can greedily determin flipped intervals.
- broken device: Divide bits into groups of size 3. There is a code of 3bits that translate 2 bit if intact, 1bit if 1 bit lost, 0 bit if more bits lost.
- railway trip: If you make edges to adjacent greater stations, It looks like a tree. You can use doubling to answer queries quickly.
- coach: Sort refilling points by SimodT and passengers by by Di together. Each adjacent refilling points can purge passengers between them from the back. You can do DP and you can fasten DP by convex hull trick.
- long mansion: Let Llink_i be the rightmost j s.t. j ≤ i and ci is in Aj. Rlink_i is alike. Then JOI-kun can't go out from [l, r] iff Llinkr < l and r < Rlinkl. Let Lretr be min{ l | Llink_r < l and r < Rlink_r }. Then JOI-kun can't go from L to R iff there exists r s.t. L ≤ r < R and Lret[r] ≤ L. You can use segtree to speed it up.
- natural park: Let's consider the case of tree. You can add node one by one. First, you can determin wheter the node connects currect tree directly. If Yes, Number the tree nodes BFS order, then you can binary search which node connects the node directly. If No, binary serch a node between this node and the current tree, and solve recursively. In the case of general graph, you can solve with almost the same solution.
- abduction 2: Memoize. If you speed up finding the street with sparse table, you can get AC. Time complexity analysis is a little complicated. This margin is too narrow to contain. If you want to know, you shold read the Japanese editorial slide.
- city: Index the nodes by euler-tour order. Encode nodes by pair of the id and interval length. Sum of the number of the descendants of each nodes are at most 18 N. So most of the lengths are very small. Representing length like 1.05n ( if you can't, add dummy nodes ) is very efficient in this case.
- dragon 2: Sort points by the angles from X. sweep them by the angle. Use segtrees or BITs to manage current points by the order of the angle from Y. You can now answer queries efficiently. Sqrt decompose queries by the size, you can solve with O(NsqrtQlogN)
UPD4:
The score distribution and official editorial slides (Japanese) are distributed.






It's wonderful! Many coders will participate :)
BTW, your account name is joisino, are you related to / staff (?) of JOI?
Sorry for my poor English.
I am a kind of staff of JOI (tutor), though this account name is irrelevant to JOI.
During his first camp as a student, he didn't have a handle and asked seven people (I was one of them) to choose a letter. The chosen letters were 'i', 'i', 'j', 'n', 'o'. 'o', 's'. He rearranged the letters to get a readable string.
I was also one of them. If I remember correctly, the arrangement was generated by drawing. It was a little miracle.
I see the websites and I got confused. Could you please give a link to have the problems of JOIs?
.
May I upsolve this contests and where can I do this?
Auto comment: topic has been updated by joisino (previous revision, new revision, compare).
Auto comment: topic has been updated by joisino (previous revision, new revision, compare).
Will you share the onsite ranking?
No. The onsite ranking will not be published.
The frequency distribution of each tasks will be published on the JOI website after the camp.
What about the solutions? Will you publish them?
Yes. Input / Output files and editorial slides will be distributed on the JOI website after the camp.
But editorials will be available only in Japanese, not in English. Sorry for inconvenience.
Please give a link to the editorial!!! :) Please something we can use google translate to know the solution not pdf!!! If here will be some English hints it will be the best!
Contest Time is not suitable for a lot of people i think
will there be a practice mode after the contest ends?
Yes. After the contest, we will open the judge on CMS for about 1 day (until the next day contest.)
After the camp, judges on atcoder will be available.
Awesome :D Thanks :D
Where are judges on Atcoder?!
Is there an English editorial? If there is, could it be posted every day after analysis mode?
Day2:
My solution to Broken Device which exploits hashing can get > 99% of the data correct. However, it doesn't depend on K. The minimal of K I get WA determines my score, so I can't even beat my first solution which got 51.
So exciting. I think I have the highest percentage of correct answers.
How to solve Day2 arranging_tickets?
Same question here. Got accepted because of weak data. Algorithm wrong. Haven't found out any real solutions ever since.
I can't even solve Subtask 2, can anyone tell me how to solve it ? :/
Does anyone know how to solve Cultivation day 1?
Auto comment: topic has been updated by joisino (previous revision, new revision, compare).
wait n^2 wasn't intended in dragon2????
May not be. Online contest sever was 2-3 times faster than onsite. So most of O(N^2) solution got TLE onsite.
Well, mine runs under 1.2s.. :p I was trying to write O(nsqrtnlgn) solution, so I tested it with my naive code. After getting 100p, I was quite surprised, and soon I thought that this code should run in time (As operations are at most n^2 and they are quite simple comparison operations) So I was confused whether this was intended or not :D I will try to optimize it later.
Regarding problems — it was really challenging. The problems were very simple, but they were all really hard. I'm surprised how someone can come up with such problemset! I also liked your past problemsets very much, but it was even better this year. Thanks for your awesome effort, and good luck for IOI 2018!
Besides, who are selected as your national team?
Thank you!
IOI2017 Japanese team is yutaka1999 (yutaka1999), maroonrk (maroonrk), (goto), (KeiyaSakabe).
I will also participate in IOI2017 as a deputy leader of Japanese team. I'm very looking forward to it!
Hi joisino :) Thank you for sharing the solutions with us. Unfortunately, I couldn't find the right greedy for arranging tickets. Would you mind explaining me the greedy approach for a fixed t and m ? It seems unclear for me how to build the tree for railway trip, also. Thank you
Arranging: Just sweep from left to right. Let already flipped interval be x, passengers at current point be y, then you have to flip ceil((y + (n - x) - m) / 2) intervals at this point. Intervals which have greater right point is better, so flip greedily such intervals. You can manage intervals with segtree when sweeping.
Railway: Let the level of the current station be L. You can go to the next and previous station whose level is equal or greater than L with cost 1. Such intervals fully contains or separated each other, in other words, it forms a tree. Details and implementation is complicated. We distribute sample source codes and official Japanese editorial slides in JOI website in a few days, so if you want to know more details, you can read them.
Thank you :) I wish your team the best results at IOI 2017
Can i find the problem set on any OJ for upsolving ?
Now you can submit code in http://cms.ioi-jp.org/contest/
We are preparing atcoder judge. It will be available in a few days.
Hi. I know your comment is pretty old, but I couldn't help myself from asking: where are the atcoder judges? The time frame for the online mirrors was bad for my country, so I decided to start working (and reading) the problems only after they are published on some online judge and I was waiting for the atcoder one. I'm not sure whether you prepared them or not, but I didn't find them, so, if you added the tasks on atcoder, could you please tell me where can I find them?
Where is the Japanese Editorial slides?
My solution to day 2, 'broken device' is as follows.
Suppose Anna and Bruno have a shared, predetermined set of 150 64-bit integers. Our strategy is: Anna marks some of them (by bit, on the device) and sends it to Bruno. Bruno will then XOR-sum the corresponding numbers, and we want it to be X, the number given to Anna.
Anna will need to use some 110 integers since the other 40 integers are unable to use. If we have already created those integers, then we have to solve the following problem: Given 110 64-bit integers, make an 64-bit integer X by XOR-summing some of them.
Some of you would be familiar with this problem. Let's think of a vector space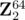 . Don't worry, it's just a tuple containing only 0 and 1 with all operation defined on mod-2 basis, element-wise; so each 64-bit integer is a vector with size 64. Then the problem would be about making a linear combination of given 110 vectors to make X. This can be solved with Gaussian elimination. Then, you'll have a set of vectors that make X, and Anna would be able to send them to Bruno, who would decode it with no problem.
. Don't worry, it's just a tuple containing only 0 and 1 with all operation defined on mod-2 basis, element-wise; so each 64-bit integer is a vector with size 64. Then the problem would be about making a linear combination of given 110 vectors to make X. This can be solved with Gaussian elimination. Then, you'll have a set of vectors that make X, and Anna would be able to send them to Bruno, who would decode it with no problem.
There are a few things that we have to take care about.
Anna(), we would select 110 64-bit vectors randomly (or not), and in the language of linear algebra, we need X to be in the span of those vectors, or more strictly, those vectors should span the wholeIn fact, it would almost certainly do. (Think of the fact that if you take N2 random numbers and make them into a square array, the matrix will be almost always invertible, and how it can be shown.) Let's try to add vectors one by one. If the current dimension is
k, the new vector would do not contribute to a new dimension for 2k cases, and it would contribute for 264 - 2k cases. Whenkis small, the probability of dimension increase is very high, and even ifk==63, the probability is 0.5. So 110 vectors seems enough to span the whole 64-dimension space. You can even try a simple DP on it. You have to consider the fact that can be at most a thousand calls toAnna(), and we should pass them all. Mine says 0.99999999999997.I don't know, but it works. Don't blame me D: I used
bitset, and to reduce more, 260 > 1018, we only need 60 bits. And, as the row reduction by pivot wouldn't occur on every row pairs (it might, but the probability is very low; maybe 0.5 probability for each row), it seems fast enough to pass each test case (containing up to 1,000 queries) by 70 milliseconds on the provided online server.P[]. We need the samesrand()seed for both Anna and Bruno. (try guessing on which seed did I use!)Now it scores 100. The source length is about 2,200 bytes altogether. It took me a few days to think of this solution. I just kept trying on finding the deterministic solution, to no avail :(
You can also submit all the problems here: https://oj.uz/problems/source/192