


Hi community,
I'm big fan of treaps, but this task makes me feel stupid. https://www.e-olymp.com/en/problems/2957
There is no English translate for some reason. Task: Given N single-element lists with integers 1..10^9, perform next queries:
- merge L R -> take two already exist lists and create a new one, equal concat(L,R)
- head L -> create two new lists: first contains first element of L, second — the rest of L.
- tail L -> create two new lists: first contains all L without last element, second — last element.
For every new list you need to output sum of it's elements.
I've did it with persistent treap — for every merge query: merge(root[L], root[R], root[++versions]), for head — split(root[L], root[nextV()], root[nextV()], 1) for tail — split(root[L], root[nextV()], root[nextV()], cnt[root[L]]-1);
But this fails with "Memory Limit" as for every query it creates at least Log new nodes
typedef long long LL;
#define N 13000005
#define MOD 1000000007
int root[300005] , c;
struct Treap
{
int sum[N];
int nodecnt;
int L[N] , R[N] , cnt[N];
int key[N];
void clear() {
nodecnt = 0;
}
Treap () {clear();}
bool hey(int A , int B) {
return (LL)rand() * (cnt[A] + cnt[B]) < (LL)cnt[A] * RAND_MAX;
}
int newnode(int x) {
++ nodecnt , L[nodecnt] = R[nodecnt] = 0;
cnt[nodecnt] = 1 , key[nodecnt] = x, sum[nodecnt] = x;
return nodecnt;
}
int copynode(int A) {
if (!A) return 0;
++ nodecnt , L[nodecnt] = L[A] , R[nodecnt] = R[A];
cnt[nodecnt] = cnt[A] , key[nodecnt] = key[A], sum[nodecnt] = sum[A];
if (nodecnt == 5000000 — 100) {
printf("TREAP\n");
exit(0);
}
return nodecnt;
}
void pushup(int x) {
cnt[x] = 1;
sum[x] = key[x];
if (L[x]) {
cnt[x] += cnt[L[x]];
sum[x] = (sum[x] + sum[L[x]]) % MOD;
}
if (R[x]) {
cnt[x] += cnt[R[x]];
sum[x] = (sum[x] + sum[R[x]]) % MOD;
}
}
void merge(int& p , int x , int y) {
if (!x || !y) {
p = 0;
if (x) p = copynode(x);
if (y) p = copynode(y);
}
else if ( hey(x , y) ) {
p = copynode(x);
merge(R[p] , R[x] , y) , pushup(p);
}
else {
p = copynode(y);
merge(L[p] , x , L[y]) , pushup(p);
}
}
void split(int p , int& x , int& y , int size) {
if (!size) {
x = 0 , y = copynode(p);
return;
}
if (cnt[L[p]] >= size) {
y = copynode(p);
split(L[p] , x , L[y] , size) , pushup(y);
}
else {
x = copynode(p);
split(R[p] , R[x] , y , size — cnt[L[p]] — 1) , pushup(x);
}
}
void print(int p) {
if (L[p]) print(L[p]);
printf("%d ", key[p]);
if (R[p]) print(R[p]);
}
};
Treap T;
char s[10];
int main(void) {
int n;
scanf("%d", &n);
int version = 0;
REP(i, n) {
int x;
scanf("%d", &x);
root[++version] = T.newnode(x);
}
int q;
scanf("%d", &q);
REP(i, q) {
if (version >= 300005 — 50) {
printf("TREAP2\n");
exit(0);
}
scanf("%s", &s);
if (s[0] == 'm') {
int x,y;
scanf("%d%d", &x, &y);
T.merge(root[++version], root[x], root[y]);
printf("%d\n", T.sum[root[version]]);
}
if (s[0] == 'h') {
int x;
scanf("%d", &x);
int v1 = ++version;
int v2 = ++version;
T.split(root[x], root[v1], root[v2], 1);
printf("%d\n%d\n", T.sum[root[v1]], T.sum[root[v2]]);
}
if (s[0] == 't') {
int x;
scanf("%d", &x);
int v1 = ++version;
int v2 = ++version;
T.split(root[x], root[v1], root[v2], T.cnt[root[x]] - 1);
printf("%d\n%d\n", T.sum[root[v1]], T.sum[root[v2]]);
}
}
}
Any ideas how to improve it?







Auto comment: topic has been updated by stostap (previous revision, new revision, compare).
UPD: sorry i got the problem wrong.
scarped until I get a new solution :P
As far as I understood when you do head/tail operation you also need to keep the previous list and then add two more lists. How do you handle this?
I didn't get what you meant by "But this fails as for every query it creates at least Log new nodes". In fact you cannot do a persistent treap in complexity better than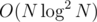 , because for each merge or split you create
, because for each merge or split you create 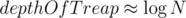 new nodes.
new nodes.
Auto comment: topic has been updated by stostap (previous revision, new revision, compare).
Auto comment: topic has been updated by stostap (previous revision, new revision, compare).
What do you mean by "it fails"? Wrong Answer, Time Limit Exceeded, Memory Limit Exceeded, Runtime Error? Maybe something even more specific?
Sorry, yes, it's memory limit exceeded in few tests. More here: https://www.e-olymp.com/uk/submissions/3233986
I have Runtime Error here, but I explicitly calling abort(), when we are close to ML.
Auto comment: topic has been updated by stostap (previous revision, new revision, compare).
I believe it's near to impossible to solve this problem with a simple persistent treap. Trap here is that depth of the tree is , where n is the number of all elements in the tree, which can be doubled with a single operation. Consider the following test case:
, where n is the number of all elements in the tree, which can be doubled with a single operation. Consider the following test case:
mergeoperations, each of which doubles the largest list.headoperations on that largest list, each operation creates ≈ 5·104 new nodes.That sums up to ≈ 2.5·109 new nodes which is both TL and ML regardless of any implementation details.
Hint: note that you actually cannot split the list at arbitrary point, you can only chop few of its first/last elements. Then create a smarter approach (which will still use persistent treap, though).
Yes, I know that depth is a problem. My main observation is that we could "cache" some vertex, instead of creating a new one.
Obvious one is a vertex with left or right result of head/tail. Now thinking about what will be appropriate "hash" for a vertex in treap.
Storing just one vertex doesn't help you as you cannot recalculate that when cutting head/tail off.
hm, I just crazy idea not performing actual splitting for head/tail, but just have 2 counters — cnt_left_cur & cnt_right_cut.
When head/tail query comes — just make 1 split & 1 merge without creating new nodes (in-place) in actual tree — this shouldn't change a tree.
When merge comes — make 2 splits (from head and tail) and merge results.
This is trick for head/tail queries. But I can't find anything for merge :(
UPD:
OK, for merge we could not merge them actually, but just hold that this treap constist of T1 & T2. Then when cnt_left_cut > T1.cnt totally forgot about T1, and working only with pair(T2, 0). Similar for cnt_right_cur