


Update 1 : The contest is over
Update 2 : Final standings can be found here
Google's hiring contest,APAC Kickstart 2017 Round D is going to held on Sunday, July 16, 2017 05:00 UTC – 08:00 UTC

Ready to get started solving fun, challenging problems? Throughout the year, Code Jam hosts online Kickstart rounds to give students the opportunity to develop their coding skills, get acquainted with Code Jam’s competition arena, and potentially get noticed by Google recruiters, too. Participate in one—or join them all!






I can't find contest dashboard. Can someone give link to dashboard?
https://codejam.withgoogle.com/codejam/kickstart/
You can only go to the dashboard two hours before the contest
Solutions will update here soon after the contest ends. https://github.com/ckcz123/codejam
Good Luck!
Solutions and explanations of A, B-small and C have updated!
https://github.com/ckcz123/codejam/tree/master/kickstart/2017/RoundD
Approach for B small? I tried to do kadane for k/n^2 elements for each dp state. Is this intended?
submatrix sum is product of Sum of A from (X1 .. X2) and Sum of B from (Y1 .. Y2) , Now suppose you have the list of all subarray sums of A and B , then you can binary search on answer. But notice we don't need all subarrays but only the ones with Max sums , Min Sums , just > 0 and just < 0 , so we can use a vector segtree to get these.
No idea what you are talking about. T.T
Can you please explain that segment tree part again?
Nice display picture :)
bhen k lode
I guess you're talking about getting 10^5 maxsums, minsums, > 0 sums and < 0 sums. Am I right? How do i get these by vector segtree?
let sumi denote prefix sum from 1 to i , the max subarray sum ending at i is sumi-min(sumj for 0 < = j < = i - 1) , so we we keep a priority queue storing (Sum , Right endpoint , Range for left endpoint , Min element index) and using this when you pop the top element of priority queue , you can split the Range for left endpoints into 2 parts , (on the left of min element index and the right). This gives us the max subarray sums , the minsums part is also very similar. For > 0 sums instead of finding minimum subarray sum , we find the subarray sum just smaller than this (using vector segtree / persistent segtree) and do stuff similar to described above , Sums < 0 is very similar (Replace just smaller with just bigger).
Did a O(n^4) soln for getting all sub matrix sums. Also used a priority queue on the side for storing max K sums out of these
Well, I'm stupid enough to be concerned about complexity in kickstart :(
I didn't want to derive the formula for closest distance of a point from a parabola and did some slow heuristics , took long enough to run but luckily i was able to submit with 2 seconds left.
I finished just two minutes after the contest ended. My solution is basically a Russian Nesting Doll equivalent of Binary/Ternary Search.
Code
I also solved C-small two minutes after contest, so sad(( I do binary search for radius and checking for intersection with point by going through parabola with low delta x.
I couldn't run my solution for B-small on VS-2015 because of too large array (~ 4*10^8), but it works fine on GNU C++. Is there any solution for creating large arrays in MS C++ ?
You shouldn't remember all the sums. However, remember only the largest K (~10^5) sums is enough.
Thanks, I know this. But question generally is about creating large arrays, not especially problem B-small:)
UPD Solved, It's enough switch build mode to x64 to create large arrays (up to MaxInt bytes)!
what about std::vector?
Vector produce runtime error in MS C++
I couldn't get AC on B small due to one stupid bug. Nevertheless, here's my solution for which I got AC now. First we find all the subarrays sums for A and B. Now, we sort them, let's call them X and Y. And make a max-heap for the maximum product. So, in the starting we insert in the heap,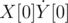 and X[size - 1]·Y[size - 1] (this is because max. product is either the product of two largest positive numbers or two smallest negative numbers). We keep track of the current indices which are there, let's say they are i, j then we insert in the heap, product of these elements (i + 1, j), (i - 1, j), (i, j + 1), (i, j - 1). Overall complexity of solution is
and X[size - 1]·Y[size - 1] (this is because max. product is either the product of two largest positive numbers or two smallest negative numbers). We keep track of the current indices which are there, let's say they are i, j then we insert in the heap, product of these elements (i + 1, j), (i - 1, j), (i, j + 1), (i, j - 1). Overall complexity of solution is 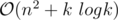
code please
There you go
Aren't you making the assumption that the kth value will always start from (1,1) of sorted Aprefixsum and Bprefixsum ? And both these prefix sum arrays were made taking first i or j elements of a and b. So, doesn't this mean no matter what result you get, you'll have a submatrix from top left corner of our initial matrix?
No, you got that wrong. The X and Y arrays consists of all the subarrays of A and B respectively, not just prefix sums. That's why the complexity is O(n2). That's why always the first maxm product will start from (1,1) and (n-1, n -1)[n denotes size of X array]
Yeah, I was about to edit that I misunderstood that part :)
This passes B small and large both I hope.
This won't pass B large as size of X and Y are way too large about 10^10
1sec = 10^8, and we get 8 minutes.
Although, a log factor will get multiplied, bcz you can't store 10^10 values. So, maybe not.
Is there a greedy approach for A ?
How to solve A large ? I solved A small using memoization .
d[i][j] = minimum time we can get if we do sightseeing j times and last vertex is i. Answer is maximum j that d[n][j] <= Tf.
Did exactly the same !
I solved A with memoization too, but instead array I had a map. It worked because "unique times" are not dense.
So,your dp state simply included the starting time for a given position ?
Yes it was something like map<pair<int, long long>, long long> memo. But I think approach of editorial is much better. I was just lucky that it worked fast.
No I solved the question taking the state as (position,no.of.cities.considered).but I'm curious to know how you concluded that your states will get repeated and the total no of.states will not become exponential
Well as I said before I was just lucky. I did not prove anything, but with the few testcases I felt that something like this happens. It was intuitive. If you see my submission was 2 minutes before the contest end. I risked and I won !
how to solve B-large
I look through scoreboard and it looks like that more than 90% contestants from China & India. Why is so low number european contestants?
Actually, these contests are for Asia PACific regions.
Where did you obtain this information?
Even though almost everyone can participate. Google's main target is Asian Pacific region. You can tell this by reading the FAQ link.
Official contest analysis is published:
https://codejam.withgoogle.com/codejam/contest/8284487/dashboard#s=a&a=3
Thank You very Much... :D
Was anyone contacted by recruiters? If so, what is your contest results?)
In problem B , how is the claim that we need to have only k largest sub array sums true.
Has the recruitment through Kickstart 2017 Round D started ? If not , till when will it start ?