


Предлагаю обсуждать здесь задачи.
Вопрос — как кто решал задачу B? И каким образом авторы гарантировали, что точность правильная у них, а не например у нас? Upd: у авторов всё правильно, у нас неправильно, посыпаю голову пеплом.
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 3856 |
| 2 | jiangly | 3747 |
| 3 | orzdevinwang | 3706 |
| 4 | jqdai0815 | 3682 |
| 5 | ksun48 | 3591 |
| 6 | gamegame | 3477 |
| 7 | Benq | 3468 |
| 8 | Radewoosh | 3462 |
| 9 | ecnerwala | 3451 |
| 10 | heuristica | 3431 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 168 |
| 2 | -is-this-fft- | 162 |
| 3 | Dominater069 | 160 |
| 4 | Um_nik | 159 |
| 5 | atcoder_official | 156 |
| 6 | djm03178 | 153 |
| 6 | adamant | 153 |
| 8 | luogu_official | 149 |
| 9 | awoo | 147 |
| 10 | TheScrasse | 146 |
Предлагаю обсуждать здесь задачи.
Вопрос — как кто решал задачу B? И каким образом авторы гарантировали, что точность правильная у них, а не например у нас? Upd: у авторов всё правильно, у нас неправильно, посыпаю голову пеплом.







Как решалась задача G и задача F?
G — пересечь окружности с прямыми, получить несколько отрезков на прямой, пересечь их. F — задача о назначениях, которая решается Венгерским алгоритмом http://e-maxx.ru/algo/assignment_hungary
писали по G такое и ВА 5 было. можешь исходник кинуть?
Нет, анонимам решения не отсылаю.
у нас в G был WA 5, потому что в одном месте не учли, что прямая может быть горизонтальной.
как решать J?
А какой сервак там стоит? На моем старом ноуте 4-летней давности задача I работает 1.5 секунд. Утверждается, что TLE = 2 секунды. WTF?
Решение динамикой на O(NR) работает мгновенно. Какое решение у вас?
Ну мы то за куб написали, но дело в том, что старенький ноут делает это за 1.5 секунды, а Core 2 Quad, который раза в два мощнее, не сумел это сделать за 2 секунды.
Ну дк на старом наверное одно ядро, а на новом 4, каждое из которых будет послабее, на одном из которых работает программа.
У меня дома на десктопе такой процессор, так что у меня есть пруф, что он в 2 раза быстрее ноута
B: Гарантировать можно, посчитав всё точно, у авторов же бесконечное время. Ключевой кусок зашедшего кода:
Эм.... A + B ~ 10^9, никакой Math.pow не сработает. Утверждение "если A+B большое, то надо брать A или B" — неверно (ну или я что-то в этой жизни не понимаю). Что-то у меня появляются сильные сомнения, что у авторов всё хорошо...
Upd: ну т.е. мы считали в BigDecimal'ах с точностью 600, возводя матрицы в степень. Наши ответы были абсолютно стабильны, но наше решение не зашло.
Да, мне тоже не нравится это утверждение. Ждём комментариев тех, кто решил с плюса. Не зашло именно по WA?
Хм, проверил — для самого "страшного" теста ответ, вычисленный таким образом, совпадает с нашим. Так что утверждение может и верно, но каким образом у нас WA — я не понимаю.
А у вас работает для A = B = 109 и p = 1, а также для p = 99? Ответы должны совпадать.
Ага, работает. Но нашёлся тест, на котором отличается от формулы на 1E-8, даже если её в BigDecimal переправить. Так что видимо с нашим решением теряется слишком много точности, чтобы BigDecimal её компенсировал (мы не знали явной формулы, поэтому у нас линейная реккурентность с возведением матрицы в степень). Значит, в итоге мы не правы, а авторы правы :( Ограничения конечно тоже жестокие — зачем просить такую жуткую точность, чтобы только знающие явную формулу загнали? Ну да ладно.
Всем спасибо за помощь :)
У нас возведение матрицы 3х3 в степень с BigDecimal. Прошло с первого раза.
Ну понятно, что это зависит от матрицы. Например, мы делали так: у нас есть трёхдиагональная система уравнений, выражаем всё через x1; всё выражается с помощью коэффициентов ak, bk, которые преобразуются линейным образом и считаются матрицей в степень (5x5). В итоге получаем x1 и ещё одним возведением в степень считаем xA. Вот тут 700 знаков BigDecimal уже не хватило, как выяснилось :(
У нас примерно то же самое, только матрица 3х3. Если записать уравнение для xi, то легко выразить xi через линейную комбинацию xi - 1, xi - 2 и константы. А это считается матрицей 3х3. Но вообще, можно же не зная формулы заранее, развернуть рекуррентность и вывести эту формулу. Правда, для 5х5 это довольно неприятно.
У нас, кстати, во всех операциях с BigDecimal используется MathContext.DECIMAL128. Я подозреваю, это далеко не 700 знаков.
В каком смысле "только знающие явную формулу загнали"? Мы, например, решали задачу как упражнение на вывод этой самой формулы. Линейная рекуррента выражает решение через корни квадратного уравнения, переход с вероятности на мат. ожидание (та самая плюс единица) — линейная поправка c * i для члена fi.
У нас возведение матрицы 3x3 в степень. Решаем систему di = 1 + p·di - 1 + (1 - p)di + 1 методом прогонки: di - 1 = αi + βi·di.
Дальше записываем αi = ai / ci, βi = bi / ci, строим линейную систему относительно ai, bi, ci и возводим матрицу в степень. После каждой операции умножения проделываем нормировку (делим все элементы матрицы на наибольший по модулю элемент). Прошло с первого раза в long double.
Поздравляю с победой. 9 задач — это очень круто!!!
Тоже поздравляю с победой, я восхищён :)
Ну да, это похоже на то, что у нас, но проще. И видимо точнее, раз у вас в long double'ах зашло, а у нас BigDecimal'ы умерли из-за того, что p на 100 в даблах поделили :)
P.S. Поздравляю с победой, ваша команда в этом сезоне пока адски жжёт.
Илья, матрицу из даблов инициализировал?
О, точно в цель! p / q считал в BigDecimal'ах, а вот p с самого начала на 0.01 в даблах умножил :( Обидная бага, и главное — её было вполне реально найти. Спасибо.
Отлично, что разобрались. А вот сразу в теги писать bugs как-то зло. Правда в итоге баги участников. Как говорит мой сын "бивает..."
Опс, сорри, убрал bugs :)
Да, кстати, если задачу решает формула, состоящая из арифметических действий, то оценка точности всего лишь дело техники, разве нет?
Эм... тест "50 1000000000 1000000000" — ваше решение выводит "-Infinity". Либо у вас написано что-то интересное вне этого else, либо я говолюсь говорить авторам много чего доброго...
Вне этого "else" написано вот что, я просто не хотел загромождать пост
Вроде ваше решение в BigDecimal не заходило из-за неправильной инициализации: BigDecimal.valueOf(P / 100.0) — неправильно; BigDecimal.valueOf(P).divide(BigDecimal.valueOf(100)) — правильно.
Блин, я это отсёк как явно бредовый вариант :)
В задаче H надо было считать С-шки? или там был какой-то другой трюк ?
C-шки считать надо было. Во всяком случае, в нашей динамике они активно использовались.
ВНЕЗАПНО задача В очень известная, например, на википедии:
http://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%B4%D0%B0%D1%87%D0%B0_%D0%BE_%D1%80%D0%B0%D0%B7%D0%BE%D1%80%D0%B5%D0%BD%D0%B8%D0%B8_%D0%B8%D0%B3%D1%80%D0%BE%D0%BA%D0%B0
Примечание: формулы явные, проблемы с точностью не намечаются.
E и F тоже не блещут оригинальностью. Как википедия помогает добиться нужной точности в B?
Написал update. Там просто конструктивная формула, в которой в условиях задачи нет вычитания близких чисел.
Как решать "runs" and "palindroming"?
runs — квадратная динамика, говорящая, с какой вероятностью перестановка из i элементов имеет j серий. Надо заметить, что когда мы вставляем в перестановку длины i с j сериями элемент i+1, то в i-j-1 месте количество серий увеличивается на 2, в двух местах — на 1, а в оставшихся j местах не меняется. Таким образом имеем квадратную динамику с пересчётом значения за константу.
У нас кубическая динамика прошла. Динамика по количеству поставленных элементов, количеству серий и последнему элементу. Каждый раз вставляем элемент в конец и пересчитываем все при помощи частичных сумм.
Хм... писал ровно такую динамику, но у меня WA 42 все время! Не подскажете, в чем ошибка?
http://pastebin.com/gAnzkTRB
Ошибка на тесте 1 1?
Спасибо!
palindroming можно делать так. Понятно, что ответ зависит только от количества вхождений каждой буквы в слово. Посчитаем их в массив a[26]. Теперь, чтобы найти количество перестановок чётной длины, можно поделить каждый элемент из a пополам и решить задачу про количество слов, которые можно составить из этих букв. Это можно сделать динамикой d[i][j]-количество слов из первых i букв длиной j. Пересчёт динамики получается такой: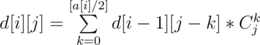
Для нечётной длины всё почти то же самое, только необходимо выбрать какую-то букву на роль центральной и убрать её вхождение из а. Таким образом получаются ещё 26 подсчётов.
А что по E (факториалы) заходило?
Прога на хаскеле мгновенно решает :) Т.к. там длинка хорошо реализована.
А хаскел доступен? В дорешивании его нет, и на opencup.ru в Server Parametrs тоже отсутствует.
Хм, в дорешивании действительно почему-то нет. Но на контесте был.
У нас зашло такое. Пусть мы хотим перемножить набор из N чисел (изначально это {1, 2, ..., N}). Разделим это множество на 2. В первом будут элементы с нечетными индексами, во втором — с четными. Рекурсивно посчитаем ответ для меньших множеств. Теперь при помощи БПФ перемножим получившиеся ответы.
Можно было точно так же, но ответы перемножать за квадрат. Заходило по времени после оптимизации 'не умножать a[i] на b[j], если хотя бы одно из этих чисел равно нулю (a[i] и b[j] — "цифры" длинных чисел)'.
Точнее у нас отрезок из чисел [l, r] разбивался на отрезки [l, m] и [m + 1, r], где m = (l + r) / 2. Но с чётными-нечётными индексами по идее должно ещё быстрее работать.
Выложи код, пожалуйста
http://pastebin.com/jDZ9zF48
Вижу два основных отличия от моего: цвет автора и своя структурка вместо complex<double>. Наверное, все таки первое.
Вообще complex тормозит.
Окей, буду знать. В Петрозаводске мы сдавали две задачи с complex<double>, и все нормально заходило, да и на емаксе про это ничего не написано...
не всегда все что на емаххе хорошо, да и вообще там про это написано
писать FFT на стандартном comlex, тоже самое что бинпоиск по эпсилону — рано или поздно будешь покаран за это, ага
Как представитель авторов прошу плюсовать/минусовать этот комментарий. В ответ прошу высказаться по задачам: оригинальность, сложность, интересность.
Нормальный контест, не то чтобы очень крутой, но и не ужасный (а таких в последнее время очень много). По поводу оригинальности — F и G конечно не стоило давать, E пожалуй тоже, там языки с нормальной встроенной длинкой имеют большое преимущество; с B проблема, что про это есть статья в wiki, но не думаю, что много кто в процессе контеста её там нашёл.
По поводу интересности — D, I и B достаточно интересные; над C и J во время контеста не успел особо подумать, к сожалению.
На этих задачах проводился чемпионат БГУ (1/8 ACM) где без F, G совсем бы было туго, а языки с хорошей длинкой не принимаются.
Спасибо. По поводу F, G и других хочу высказать свое мнение:
1) это была олимпа БГУ, не только кубок
2) это не онсайт для профи, тут нужны и упражнения, и сложные интересные задачи, если убрать A, F, G и H (которые не сказать, что супер задачки), то слишком много команд получает около нуля АС. Это хорошо? Но, конечно, топ не тратил бы время на [:||||:], а решал бы только новые и интересные для них задачи
3) лично мне больше всего нравятся задачи B, C, J и вообще не нравится F, но... см. выше
4) B: про статью в wiki мы не знали, но у нас было два принципиально разных решения
5) Е: мы просто не знали, что можно решить стандартными средствами, но и так она не фантастическая, но довольно оригинальная ИМХО
6) G: лично я уверен, что на примере этой задачи можно показывать, как хорошо повернуть систему координат и сделать задачу много проще
7) I: у нас было решение только за куб... круто, что участники смогли решить за квадрат
Ну ок, с поправкой на чемпионат БГУ претензий нет, хороший контест. (btw, по поводу G — поскольку в кубке теперь разрешён prewritten code, решения с поворотом и без абсолютно одинаковы.)
По поводу I: http://oeis.org/A059427
там рекуррентная формула дана, с которой решается за квадрат
По поводу F — неужели венгерский алгоритм или MCMF в наше время считаются настолько простыми, что задача на них даётся как утешительная?
А задача H, в отличие от F и G, лично мне показалась оригинальной и понравилась.
Я тоже не думаю, что много кто нашел ее во время контеста. Я читал эту статью с год назад, там интересные следствия о корректности рискованных стратегий в худшей позиции.
Очень интересно, есть ли в задаче J решение без миллиона формул. Я честно потратил час, на то чтобы все их вывести, но к сожалению забыл частный случай, на который требовалось еще столько же формул =( поэтому за 40 минут до конца забил на нее.
Можно ли как-то оригинальнее? Если да, расскажите хотя бы в двух словах, пожалуйста.
UPD. Забыл сказать, что хотел. Контест очень понравился, сбалансированный хороший контест. Побольше бы таких OpenCup. Большое спасибо всем авторам.
Числа в прямоугольнике можно разбить на 4 треугольника, для каждого из которых решать будет одну и ту же задачу: найти сумму в пересечении треугольника и прямоугольника.
Как решать такую задачу: треугольник и прямоугольник пересекаются тремя схожими областями, для каждой из которых будет подбирать многочлен.
Легко заметить, что многочлен зависит от количества строк и столбцов в матрице и количества столбцов в сумме. Но количество строк и столбцов у нас константа! Тогда нужно сгенерить несколько первых членов суммы, и потом подобрать многочлен только от количества слагаемых.
Думаю, что, внимательно прочитав, можно уже решение додумать.
Лично у меня около 170 строк на java в BigInt :)
Понравились задачи B и D. Хотя, подозреваю, в D есть более простое решение, чем то что мы сдали. Авторское решение тоже основано на слиянии приоритетных очередей (используя трюк с перебрасыванием из меньшей в большую) и работает за O(Nlog2N)?
По поводу самых простых задач. Если в G можно найти хоть какой-то поучительный смысл, то задачу F вообще не понимаю. Можно было хотя бы матрицу сделать прямоугольной. Для тех кто и так нормально умеет писать венгерский алгоритм или MCMF, это ничего бы не изменило, зато для команд которые писали его впервые после прочтения Кормена или еще чего-то, добавило бы хоть какой-то элемент размышления.
Нет. В авторском дихотомия.
В D? По какому параметру вообще?
По вероятности, к которой "стремимся" — все, которые меньше ставим на r[i], которые больше — l[i], остальные — на эту вероятность. Считаем сумму и соответственно двигаем границу бинпоиска.
Ключевое наблюдение — все вероятности, не стоящие на нижних (верхних) границах должны быть равны одному числу X. Доказывается дифференцированием. Далее, существует единственное X, при котором сумма вероятностей будет равна 1. Ищем его дихотомией.
Лол. У нас вообще другое решение. Ну тоже за n log n.
Поделись :)
Присвоим каждой переменной значение lefti. Отсортируем все переменные по этому значению. Теперь пусть у нас есть сэт активных переменных. Это переменные, значение которых мы будем одновременно увеличивать. Причем текущее значение всех переменных одинаковое. Сэт меняется в двух случаях.
1. Когда какая-то переменная из сэта достигает знаенчия righti. Тогда она удаляется.
2. Когда значение перенных в сэта достигает значения leftj какой-то переменной не из сэта. Тогда она добавляется.
Если мы можем увеличить текущее значения до следующего изменения сэта так, что сумма < 1, то увеличиваем. Иначе увеличиваем на (1 — sum) / (размер сэта) и выходим из цикла.
Как-то так.
Клево. Но по сути вы ищете ту же равновесную точку X, что наше авторское искало дихотомией. Я пытался написать перекрест в духе вашего решения, но когда оказалось, что это сложнее, чем я думал, забил. :)
Задачи хорошие, хотя и правда достаточно много известного и повторов.
Например, задача С была на отборе в Казань года четыре назад, но там реализации больше, чем идеи. Правда, вполне возможно, что я — единственный, кто из нынешних участников opencup решал тот отбор.
Туда эту задачу позаимствовали с каких-то древних сборов школьников.
Да, причем тематических. Там было пять задач вида "нарисовать граф на чем-то". К сожалению, найти те сборы сейчас не получилось.
Расскажите, пожалуйста, как решалась задача M?
Решим в два этапа.
1 этап — отсечем те числа, которые точно нам не подходят. Для этого будем отсекать по одной рамке спирали. С каждой рамкой размеры оставшейся матрицы будут уменьшаться на 2, а координаты нужной клетки — на 1. Видно, что влоб отбрасывать нельзя.
Попробуем отбросить все ненужные рамки сразу. На каждой рамке написано 2 * n + 2 * m — 4 — 8 * (index — 1), index — номер рамки. Тогда полное количество чисел, которые точно можно отбросить, равно 2 * k * (n + m) — (4 + 12 + 20 + ... + (4 + 8 * (k — 1)) = 2 * k * (n + m) — 4 * k * k, k — количество отброшенных рамок.
Заметим, что k = min(i — 1, j — 1, n — i, m — j). Значит мы можем отбросить 2 * k строк, 2 * k столбцов, координаты i, j также уменьшаются на k.
2 этап — просто проверить принадлежность точки (i, j) к четырем сторонам текущей рамки матрицы. Проверять надо в порядке заполнения, то есть левая сторона/нижняя/правая/верхняя. Искомая клетка точно будет на одной из этих сторон, так как все внешние по отношению к ней клетки мы отбросили на 1 этапе.
немного не в тему: кто-нибудь знает, можно ли изменять составы команд и название команды, или первичные регистрационные данные нельзя изменять? если можно, правильно я понимаю, что нужно написать письмо с просьбой snarknews?
Изменить точно можно. Писать думаю должен координатор региона.
Нужно написать координатору, инфа 100%. Мы сделали именно так.
А как же решается задача А о расстоянии между точками на прямоугольниках?
Строим граф из всех интересных точек, пускаем по нему флойда.
Если я правильно понял, то нужно найти точки пересечения прямоугольников. По ним и вершинам прямоугольника построить граф.
Да. Ну еще точки старта и финиша.
Подскажите, пожалуйста, простой способ построения графа к этой задаче. У меня не вышло. Видимо я шел по неверному пути, у меня там вылезало очень много строчек кода, в следствии чего до конца контеста ее дописать не удалось.
ну там он вроде один, по другому не напишешь: добавляем все нужные точки, аккуратно пересекаем в целых числах все стороны прямоугольников, потом перебираем две точки, если они обе лежат на какой-то стороне какого-то прямоугольника (всего 8), кидаем между точками ребро. пускаем флойда. профит.
Спасибо. Я делал оказывается совсем по дурацки, стыдно распространяться :)
Мы словили багу, но steiner писал так: рассмотрим все точки с упоминающимися во вводе координатами (в смысле декартова произведения {упоминается как x} x {упоминается как y}). Две точки соединены отрезком, если отрезок, соединяющий их, целиком лежит на стороне одного из прямоугольников.
крутяк, меньше гемора с пересечением