


Tutorial is loading...
(Idea — Jury of the Olympiad, developing — Andreikkaa)
Tutorial is loading...
(Idea and developing — Kniaz)
Tutorial is loading...
(Idea and developing — Sender)
Tutorial is loading...
(Idea — glebushka98, developing — ch_egor)
Tutorial is loading...
(Idea — GlebsHP, developing — Flyrise)
Tutorial is loading...
(Idea and developing — mingaleg)
Tutorial is loading...
(Idea — Endagorion, developing — kraskevich)
Tutorial is loading...
(Idea and developing — wilwell)






Auto comment: topic has been updated by vintage_Vlad_Makeev (previous revision, new revision, compare).
Auto comment: topic has been updated by vintage_Vlad_Makeev (previous revision, new revision, compare).
Auto comment: topic has been updated by vintage_Vlad_Makeev (previous revision, new revision, compare).
The comment is hidden because of too negative feedback, click here to view it
Optimisation is your forte, bro.
my solution for div1F
1) first let's sort princesses as in editorial
2) then if we take princess i, we make edge from ai to bi
3) then we can add new princess, if and only if graph, which we got, has no component, that has n vericles and > n edges, so you need only check it with dsu
As example of this solution you can see this submit(http://codeforces.net/contest/875/submission/31437228)
Thanks.
My solution for DIV 1 D:
Fixing the left end of subarray, we count the required number of right ends. Now, if we fix one index and start taking prefix or from that index, we see its changed at most O(log(109)) times.
So, we consider each range of interval, where prefix or is constant. In each of these intervals, we can calculate the first index where prefix max is not less than prefix or ( prefix or is constant) by RMQ and binary search, we can add all the subarrays in this interval before this index.
O(nlogn(n)log(109))
A little bit optimisation and I got AC with 982 ms. 31408332
My same solution got AC in less than 500ms. 31403626
The difference must be of scanf and cin.
In DIV 1 B (1 s limit) which required scanning 3e5 elements, I got TLE when I used cin and AC with 139 ms when I used scanf.
In your situation too you need to scan 2e5 elements.
insert the following into your template :-
and you won't have to worry about timeouts with cin/cout :) . My div1B passed with cin/cout in 171ms
Your approach sounds very nice,can you explain it further? I some some difficulties understanding how you will find all right end points where prefix or is constant, and also the binary search part, thanks!
In problem Div2E we also should take in mind that if
s[i]is a prefix ofs[i + 1]andlen(s[i]) != len(s[i + 1])then it is impossible to get the correct capitalization of letters.If len(s[i])<len(s[i+1]),s[i] is lexicographically less than s[i+1].
Yet another approach for Div1D
Create sparse tables for operations or and max. Then calculating the largest segment where i th element is maximum and the number of segments that satisfy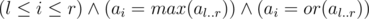 could be done with binsearch.
could be done with binsearch.
That's
http://codeforces.net/contest/875/submission/31414300
DIV 2 D, TLE with cin/cout 31455585 but AC with printf/scanf 31455839 with execution time reduced from 1000ms to 124ms !
You could also use some I/O optimizations for cin/cout:
can anyone please explain me the 876B — Divisiblity of Differences editorial
there is a typo in the editorial, note that in the start it should be "when x — y is divisble by 'm'"
anyways, let's say there are 'k' numbers in the grop,then all the numbers must have the same remainder when divided by 'm'. WHY is that so? --> because let's say that there are some numbers of different remainders, then,let them be x and y,lets say x = a(mod m) and y = b(mod m) clearly x — y = (a — b)(mod m) != 0 (mod m) because a != b
therefore, in a group,all must have same remainder.. now its simple,for all numbers calculate remainder and check if some remainder between 0 to m-1 has count >= k if so,print k of those numbers, hope this helps
I don't get the editorial explanation of 875D — High Cry , can someone clarify that approach...what is "go" and what is it's purspose, Also if someone submitted a solution using the editorial approach, please post your submission.. thanks :)
I think the problem High Cry can O(n) and get AC . Here is my solution http://codeforces.net/contest/876/submission/31447193
I maintain a stack form left to righ, remove the top element if (a[top()] or a[i] )= a[i] ,then push the a[i]. And from right to left is similar . For all element we will ans-=(i-L[i])*(R[i]-i)
Sounds like a great solution, could you plz explain a little bit?
emmmm a[l] or a[l+1] or ...a[i]....or a[r] =a[i], It will invalid . we find all of it and subtract from ans.
Got it. Just a similar approach to calculating the largest rectangle in a histogram. Great insight. Thx.
Can you please explain the reason for
in your code. 31447193
I am not able to understand it completely.
Each invalid slotion of pair (L,R) should be calculated once , if (a[i] = a[top()]) you should make L[i]=top(); , otherwise you may calculate some pairs (L,R) more then once . ( I'm so sorry for my poor English :(
Thank you so much :D
In DIV2-E can anyone please help me to understand that if we add directed edges than how can we update all the nodes connected with curr node(if it is somewhere inside the tree)! and also if we do dfs each time then how it fits the time limit !
You can use dfs after all the edges are added and every node will be visited at most once during the dfs. So it's no problem.
but if we do so after adding all the edges then can we get the desired answer ? As capitalizing a number there may be the case that there are some other nodes which are affected and if we didn't consider them in the further checking , how will it lead to correct answer?
I know i am missing something please help!
Capitalizing a number will often affect some nodes but it's doesn't matter if we check them in the end. It's just like we're building a graph that show the relationships among nodes. Consider three nodes a, b and c, there are directed edges among them like a->b->c. Suppose a is capitalized, then it means that b and c are also have to be capitalized when we consider it in the complete graph. If we consider it as we add each edge, then we will get that b must be capitalized when edge a->b is added and similarly c must be capitalized when edge b->c is added since b is already capitalized.
31392967
Div 1E: Could someone please provide the proof for this implementation?
Binary search on the answer. When you are processing index i, which means one of the guys is at position a[i] currently, keep a list of the possible positions where the other guy can be at that moment. The transitions are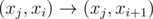 or (xi, xi + 1). When moving from i to i+1 check which of these transitions are invalid and remove them. The answer is negative iff at some point the list becomes empty.
or (xi, xi + 1). When moving from i to i+1 check which of these transitions are invalid and remove them. The answer is negative iff at some point the list becomes empty.
I've got an alternative solution for div1A. Let's represent n like sum (1+1)d[0] + (10+1)d[1] + ... +(10^8+1)d[8].
Now we can see that we can greedily get all d[i] starting from 8. d[i] = n mod (10^i+1) or d[i] = n mod (10^i+1) — 1.
A recursive solution works in O(2^log10(n)).
31428143
my solution to DIV2-F : I first created next and prevs arrays (the next greater element and the prev greater element) as mentioned in editorial. After that i store all the indices which have that particular bit set, then for each index i just iterate over all 29 bits(except those which are set in current number) and do a binary search on each of them to find if there exists a position which has the required bit set and then just taking minimum among all those and after getting the first valid position i just calculate the answer using basic combinatorics!
my implementation : http://codeforces.net/contest/876/submission/31474937
I've got a tiny brute force solution for Div1D High Cry here.(AC with 62ms) http://codeforces.net/contest/876/submission/31465112
Great brute force for random data or data with all height the same. But maybe for data with height like 2 3 2 3 2 3 2 3…… ,it won't perform that well.
Can someone explain their approach (in detail) for Div1 D 875D - High Cry ? I am not able to understand the editorial.
For the pair (L,R) if there has i (L<=i<=R) ans ( a[L] or a[L+1] or a[L+2]... or a[R] )=a[i] it will be invalid ,find all of it .Others are valid .
Okay! Then How to find all the the invalid pairs in a linear time ?
emmmmm O(n)solution works 62ms http://codeforces.net/contest/876/submission/31447193 O(nlog(1e9)) runs 108ms http://codeforces.net/contest/876/submission/31439626 And O(nlogn*log(1e9) ) got AC 530ms use another method http://codeforces.net/contest/876/submission/31437390
Can you tell me what's wrong with my approach? Here's the link to my solution: http://codeforces.net/contest/876/submission/31502254
I find one sample that you code output wrang answer .
4
2 1 2 2
your output is 4.
But answer is 5. (1,2) (1,3) (1,4) (2,3) (2,4)
I'm sorry for I cannot understand you code. (ans should be saved use "long long "
But for the sequence 1,4,2. 1 OR 4 OR 2 = 7. No i satisfies a[1] or a[2] or a[3] = a[i] but 1,4,2 is invalid. (Maybe I misunderstand your solution?)
1|4|2 =7
1<7,4<7,2<7
so the solution is valid
Well, E can also be solved without using graph SOLUTION LINK: http://codeforces.net/contest/876/submission/31502316
Can you please explain your solution?
I have O(n.log(1e9)) solution for 875E - Delivery Club
check my solution here : 31480382
.
875C When we are comparing adjacent strings.
I have doubt for 2nd case : there may be solution for s[i][k] is capitalized and s[i+1][k] is not capitalized.
Another way to solve DIV1 C. First for each consecutive pair of strings, If first string is prefix of first then it's already sorted, else if second is prefix of first then answer does not exists. Now in last case,
first index where first and second string differ is the only pair of character on which order of these two strings depend. For string numberi-1andi, character oni-1should be less thanithone. we can build a directed graph, denoting these pairs as edges, where each edge goes from character which should be smaller than where it goes to. Finally performtopological sortingon the graph, travel in reverse order in topo sort, for each node check each of the outgoing edge should go to the character smaller than current one, if it doesn't then capitalize the current character and check again. if it doesn't satisfy after capitalization then there is no answer. Once you have checked for each node in the sort, perform the changes in the original string you did while iterating and check whether all of the string are sorted or not. If any pair fails print "No" else print the answer. For Capitalization sign can be reversed, if sign is different then character which should come first should be -ve else use absolute. 112439293