

Hi!
I'm glad to invite you to take part in Avito Code Challenge 2018 which starts on May/27/2018 17:50 (Moscow time). Any participant can join the round and it will be rated for each participant. Hope to see you among the participants!
Problems are prepared by me — Ildar Gainullin.
This round is conducted on the initiative and support of Avito. Avito.ru is a Russian classified advertisements website with sections devoted to general good for sale, jobs, real estate, personals, cars for sale, and services. Avito.ru is the most popular classifieds site in Russia and is the third biggest classifieds site in the world after Craigslist and the Chinese website 58.com.
Many thanks to Vladislav winger Isenbaev, Grigory vintage_Vlad_Makeev Reznikov, Ivan isaf27 Safonov,Alexander AlexFetisov Fetisov and Shiqing cyand1317 Lyu for the round testing, Nikolay KAN Kalinin for helping me to prepare the contest, and also to Mike MikeMirzayanov Mirzayanov for systems Codeforces and Polygon.
Participants will be offered eight problems and three hours to solve them. Scoring will be announced a bit later.
Avito presents nice gifts for participants. Top 30 participants and also 10 random participants with places 31-130 will be awarded with a special T-shirt.
I hope everyone will find interesting problem for themselves. Wish everyone a successful round and high ratings!
Good luck!
UPD,Scoring: 500 750 1250 1750 2250 2750 3250 3750
UPD,Editorial is ready: Editorial!
The winners of random t-shirts are:
| List place | Contest | Rank | Name |
|---|---|---|---|
| 6 | 981 | 36 | snuke |
| 31 | 981 | 61 | Swistakk |
| 40 | 981 | 70 | yasugongshang |
| 52 | 981 | 82 | Xellos |
| 62 | 981 | 92 | shadowatyy |
| 76 | 981 | 106 | budalnik |
| 80 | 981 | 110 | kostka |
| 88 | 981 | 118 | pb0207 |
| 95 | 981 | 125 | Noam527 |
| 96 | 981 | 126 | xiaowuc1 |







For a moment there I thought it was "Aviato", you know, Erlich's company.
wtf, I just noticed it's not aviato
You know Aviato? ... My Aviato? (In Erlich's voice)
Yes... Aviato
Will the difficulty of the problems be similar to other Codeforces Div1 & Div2 combined rounds?
Maybe the contest is including both Div.1 and Div.2 because it has 8 problems.
is it rated?
This is a legitimate question because the blog says it's rated but the contest page doesn't say anything
It is given that it will be rated for every participant. See the first paragraph.
And also the writer wished high ratings.
That was exactly my point the blog says it's rated but contest page doesn't say anything.
everybody here is downvoted?
I want t-shirt. But I think i could not have this rank
I think you can get the T-shirt next time as long as you practice coding assiduously. Bless you.
First Div 1+2+3 contest :D
Div 2 includes Div 3 XD
First Div 1+2 Contest :P
Cricket lover's in dilemma..#IPL final
May be miss the first innings of IPL final. But, it doesn't metter. Codeforces contest is more important than IPL final to me. :)
Guess I won't be watching the IPL final then...
when reading the Avito
T-shirts will be awarded for 130 from Div.1 + Div.2?
Give Div.2 a chance :'(
No pain no gain.
Will participants be able to do challenges(hacks)?
I think Yes, as he said that there is a score distribution for the problems (which will be announced a bit later). and he didn't say that it will be held on extented ACM ICPC rules.
so this round will be like the ordinary combined rounds.
Div1+Div2+Div3 contests at one time(8 problems) Yeah!!
Karuis is looser, how it is possible!!!!!!!!!!!!!
?
They do this for all not just for Mike Mirzayanov
How many questions will there be?
Participants will be offered eight problems and three hours to solve them.T-shirts from Avito or from Codeforces?
Asking the real question. ^
Not sure if I should try to reach for the T-shirt or wait for the next div2 round for a bigger rating increase kickstart into div1.
The random t-shirts will be selected as usual with the help of two scripts below and random from testlib.h. Seed is the score of the winner in the upcoming Codeforces Round 485 (Div. 1), the length is the number of participants between the 31-th and the 130-th places inclusive.
This is unfair; Grandmasters have superpowers and may control her/his seed to choose the winners in favor of their preferences
(i'm joking)
Thanks for telling, we didn't notice.
Why using the score of the next round, not this round?
We have to wait for another two days to know whether we are lucky or not.
So who are the winners?
So the winners are:
Interesting, tourist vs Um_nik.
Who'll do it in your opinion?
Can you make 2 buttons for voting? :)
How can I?
There are online voting sites. You can create one and add a link to it.
Done.
Can you make it randomly shuffle these people, so that there is no bias based on position in this list?)
Uh, that option isn't there.
Well, I guess this is ok for the first poll in codeforces ever ;)
Someone is hunting my comments and downvotes them ;)
Easy one for tourist
and the master of 'O' and '0' jqdai0815 :D
Delayed by 15 minutes :v
what's the problem codeforces every round we get delay of 10-15 mins. at the last moment? :v
To increase the participation :)
Everybody now can watch IPL final for 10 minutes :)
Will you travel to Russia this summer?
No, but why??
The world cup will be held in Russia.
I just forgot about IPL Final I was too busy watching tourist or maybe I just intentionally wanted to do that :P
.
That second pic should say "after the contest" tbh fam.
I do not participate in the contest but I discovered that the point decrement speed is not adjusted?
This way a problem will only worth 28% of original score at the end of contest.
Edit: just saw the announcement
That's quite a lot of pretests. I like it (if they aren't mostly trash).
Not like I expect at least my F to pass, though.
In D why is this approach wrong? (Wa on test 5)
I have dp[begin][end][cuts]
and if cut is 0 it is just the sum of begin to end
Else i can cut it at any of the location from begin to end and see the cuts from begin to cut_position and cut_position + 1 to end.
There is no guarantee that when choosing to cut at some point, the optimal AND value is obtained by the maximum possible values for the resulting two subarrays. Consider the pairs [5,5] and [5,2]. [5,2] gives us a better AND value (7), but your solution would choose [5,5].
How to solve D?
I did a bruteforcey solution with recursion every time I switch to a new bookshelf. With a few optimizations it passed in the time limit. (Mainly, don't recurse if the AND so far is less than the best cost you've seen so far) Update: Test case #61 begs to differ, got TLE
Start from the 55th bit, let now be 0. If you can get and value equal to now + 2^i, add 2^i to now. It can be done with easy dp.
Find the answer bit by bit. Start with answer equal to zero. Then for i from 60 to 0, check if you can obtain a solution with answer + 2i. If you can, just add.
Checking if there is a solution with a fixed answer can by done with dp[position][parts]. To compute a state, try to fix a new position and consider dp[newposition][parts + 1] if the sum in the interval [position;newposition] contains the bits of the fixed value as a subset, in other words (sum&FixedValue) = FixedValue.
thanks for writing a neat and clear code. It help me a lot!
What I did:
set<long long> dp[i][j]= The set of possible values obtainable when books are put into first i shelves, where first j books are used.It is trivial to show that in first i shelves, there should be i books in minimum and i+n-k books in maximum, and so the dp array is only valid in such range. A complete
dp[i][j]can be computed by[all values in dp[i-1][i-1~j-1]]&[appropriate range sum of input array].you got 1000 & 0100 < 0111 & 0001, when both 1000 > 0111 and 0100 > 0001
I think G is too easy to be 3250.
I think the hardest part in solving G is debugging your code.
PS: Btw, can anyone share with me how to debug segment tree code efficiently?
That's right, I forgot to mod the value after doing lazy updates. That costs me a lot of time and points.
how did you solve it?
Can someone explain how to solve E?
Sort all queries and go from left to right. dp[i]- what is the last index where you can obtain i. When you encounter begin of any segment just update dp.
Sort the query by left, and if equal, by right?
By left. dp[x] = max(dp[x], min(dp[x-val_for_segment], end_of_seg))
I had a O((N / 64) * Q log(N)) solution with the offline dynamic connectivity strategy ( http://codeforces.net/blog/entry/15296?#comment-203606 ).
Basically you do divide-and-conquer, keeping up a bitset representing the values attainable with currently active segments.
At every step, you first make all segments that cover the current interval active, then recurse to the left half of the segment and to the right half of the segment.
At bottom level, you OR the current bitset with the result bitset.
You can add the points where a interval becomes active to a segment tree. Every interval becomes active at most log(N) times, so a interval becomes active Q log(N) times, so the complexity is O((N / 64) * Q log(N)).
Can someone, please, explain how is updating the current set of active segments done in E? I couldn't reduce the complexity from O(Q2 * N / 64) for the whole second half of the contest. Or is the intended solution completely different?
I did it in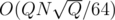 , by dividing queries into blocks and processing offline. Its similar to handling delete queries in graph updating( maintaining connectivity, MST etc on edge updates) problems.
, by dividing queries into blocks and processing offline. Its similar to handling delete queries in graph updating( maintaining connectivity, MST etc on edge updates) problems.
You can get the same complexity by performing a simple sqrt decomposition on the array and keeping bitsets with all possible values for each index.
I did it in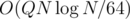 by dividing queries better, like in the RMQ table or an offline segment tree, and going down from there. I tried and tried and couldn't see how to solve it more simply...
by dividing queries better, like in the RMQ table or an offline segment tree, and going down from there. I tried and tried and couldn't see how to solve it more simply...
I have an O(NQ) solution but I'm not sure it's right or not.
But if it is wrong, I would like to know a counter-example/why it doesn't work.
Basically I do DP like how we do it without the ranges.
Then I do sweepline, adding and removing values.
When removing, I sort of undo by reversing the way how the dp is processed.
http://codeforces.net/contest/981/submission/38675426
I basically did the same but with one large modulo instead of two small ones.
Create events "segment starts" and "segment ends", order them by the coordinate, and maintain the knapsack array "
f[x]is the number of ways to getx". Inverting the knapsack update loop is straightforward.If we stored the actual number of ways, this would certainly be a right solution. However, the actual number may be too large, so we store it modulo some number, which makes the solution fast but hackable with only moderate effort. Still, there were only few submissions for this problems per room, so the hacking did not occur.
Edit: And this thread discusses the same solution.
Thanks! Time to actually learn sqrt-decomposition or some data structures, then.
I did it in o(n*n) with a 2d boolean array to check and a 1d integer array to count
How can you do it in O(1) if it takes O(Q) just to scan the input :/
Ops, i meant O(n * n), O(1) was for updating
How did you made the update in O(1)?
f[i][j] = true if you can get a sum equal i using value x[j], and d[i] is number of value x[j] take part in creating sum i. So if you remove a value x[j], set f[i][j] = false and decrease d[i] by 1.
My solution is completely different. For each query I stored the value xi in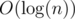 nodes in a Segment tree (each node stores a vector of values), and then took the bitset 10000000000... and pushed it downwards to the leaf nodes. The OR of all leaf nodes then tell us which values are possible and which are not.
nodes in a Segment tree (each node stores a vector of values), and then took the bitset 10000000000... and pushed it downwards to the leaf nodes. The OR of all leaf nodes then tell us which values are possible and which are not.
Complexity should be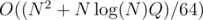 .
.
This is what I did in the actual contest (I didn't wanted to think more, had to code quick) but I think there are much nicer O(qn) solution.
Suppose that all queries have Li = 1. You can do the following : we don't see DP[i] as a boolean array, but an integer array maximizing the minimum endpoint among all queries that it used. For each i, you can take j iff DP[j] ≥ i. This approach can be extended without restriction on L — do the "sweep" over increasing i, inserting query j when Lj = i. Similar problem is here.
I think I did exactly this approach. code
Looked into your solution, seems to be the same as mine, but with minor differences. Could you explain why is that we have such difference in perfomance? Mine got TLE..
Here's my code:code
This part is wrong.
Imagine that all Q queries are of the form (1, N, 1). Then you will push the 1s down, so that each
to_upd[v](withvbeing a leaf node) contain Q elements. And then the runtime will be O(N3) (N elements, each N queries with O(N) work for the bitwise OR).The idea to speed it up is the following: If
to_upd[1](root node) contains multiple elements, then you can immediately apply them to a bitset. This way you only have to do the operationbs |= bs << xonlyto_upd[1].size(), and notto_upd[1].size() * n. And similarly with the other nodes. Then propagate the bitset to the two child nodes, and not all values into_upd.Thanks, I forgot that the updates are duplicating.
can you please explain your solution a little bit more.
Check out my solution: 38674330 I think my code should be easy to understand.
thanks for sharing this :) Btw if possible then can you please explain the second idea also!
I have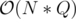 :
:
Keep dp[x] — count of subsets with sum X mod 109 + 7. Then we can easily add and remove numbers in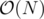 .
.
Here is the code.
PS: It passed so there were no anti-MOD tests.
Why can you delete like that? Couldn't something be added (or deleted) in between that influences dp[i], but not dp[i + x]?
I also had some trouble figuring this out. But now I got it.
You can think of it in this way:
dp[i+x]consists of the ways that include the summandx, and of the ways that don't include the summandx. Let's saydp[i+x] = dp_with[i+x] + dp_without[i+x]. The goal is to computedp_without[i+x], which isdp[i+x] - dp_with[i+x].Now,
dp_with[i+x]is clearly the same asdp_without[i], since we can make a bijection between each combination with the sumiwithout the summandxand each combination with the sumi+xwith the summandx.Now, notice that
dp_without[i] = dp[i]for alli < x, and because radolav11 computes the values with increasingi, he can just ignore the helper arraydp_withoutand store the result directly indp.There were anti-mod tests, though not for 1e9+7. I just let the dp[x] value overflow since it anyways takes mod with 2^31, but it failed on test 75
I passed it with 1e9+9. Is there a way to do something similar with no mods?
How to solve G?
I tried to do it with O(n log(n)^2) segment tree beats but got TLE'd (pretest 15). Is there a better way?
I don't remember what segment tree beats are (other than that the name evokes someone beating a segment tree with a stick), but my solution was keeping sets for all intervals containing x for each x, using it to extract intervals of multisets to multiply by 2 and intervals of multisets to add 1 to; these 2 types of queries (+ get sum) can be handled with a fairly normal lazy segment tree.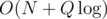 since there are only O(Q) intervals to update.
since there are only O(Q) intervals to update.
Okay, thanks.
I did the same but stored the intervals that have all nodes containing x in the segment tree, not in a separate set -> * log(n) more intervals -> TLE.
Xellos, Could you explain how to deal with the two operations in the lazy segment tree? I don't know how to keep it log(n) per query.
Keep sum, mul and add for each segment.
Thank you! That makes a lot of sense.
How to Solve 3rd Question , Tree Decomposition .
Only the stars are valid for that problem
If it is linked list — the answer is the list itself.
Otherwise there must be only one vertex with degree > 2. This vertex joins all other paths.
Linked list is a pretty extraordinary expression for path :p (some people call it bamboo, though xD)
check the degree of all vertex , if there are more than 1 vertex with degree 2 than No.
You mean more than 1 vertex with degree greater than 2
jtnydv25, name is enough to understand who is he?
one of my most favourite coder...
Why do tasks on Codeforces have to be like this http://codeforces.net/contest/981/problem/G and this http://codeforces.net/contest/981/problem/H instead of like this https://agc024.contest.atcoder.jp/tasks/agc024_e and this https://agc024.contest.atcoder.jp/tasks/agc024_f >_>? Kinda obvious what to do more or less and then codecodecodecodecodecodecodecodecodecodecodecodecodecodecode and carefully work out details
Sometimes I also wonder how problem writers on ATCoder can come up with such creative and original tasks (which is a rare thing on most of other online judge). Can any writers there share your experience?
It's "Code Challenge", you know.
I agree problems were on the easier side, but I don't really agree that they were hard to code.
Love these statements
Simple O(N2) solution to A is pretty cute. I don't know why author gave N <= 50 and ruined the fun :p
And I really liked problem F. thanks to authors!
Isn't the answer either 0, n or n-1? That would lead to trivial O(n). Or am I mistaken?
Now I see that too. Too cute to be true :)
I wrote it after finding a solution in my room, that only check prefixes.
Is it really necessary to have 130+ tests for A?
Maybe most of them are from successfull hacks.
If there is at least one solution that fails from it, then yes they are neccesary =)
What kind of pretests are these XD?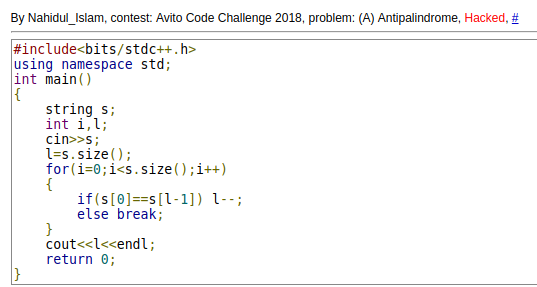
LOL
I hacked 2 such solutions in my room. I was shocked when I saw these and rechecked the question to see if I had read it right.
How to solve F? First binary search, then reduced it to some matching problem with circular segment, then what?
I solved it by using Hall's theorem. Check segment instead of subset is enough!
Here's a more detailed editorial: binary search on the answer. For each bi, expand it to an interval ci = [bi - x, bi + x]. Now we need to see if there's a matching between the ai and these intervals ci where a point and an interval can be matched if the interval contains that point.
If this were a line, it would be easy: sweep through the intervals left to right, pick the first point in the interval. However, we're on a circle, so intervals that cross the origin are tricky. To simplify it, "unroll" the line and double it. If an interval was originally [l, r] with l ≤ r, then add intervals [l, r] and [l + L, r + L]. Otherwise, just add the single interval. Now we have at most 2n points and intervals and run the linear matching algorithm as described above. Hall's theorem tells us that this unrolling is equivalent to a matching on the circle.
Thanks for the details! I don't really get why Hall's theorem says that the unrolling is equivalent. Could you elaborate?
Sure.
Initially, we have two sets of length n, A = {a1, a2, ..., an} and B = {b1, b2, ... bn}. Now when we do this unrolling process, we get two new sets A' = {a'1, a'2, ... a'n, a'n + 1, ... a2n} and C = {c1, c2, ..., cm} where a'i = ai%n and ci = [bi - x, bi + x]. Note that we use m instead of n because bi might map to two ci. n ≤ m ≤ 2n.
We have a perfect matching between A' and C. Let's apply Hall's theorem. Consider some set S', which is a subset of these a'i. Then because we have a matching, |S'| ≤ |N(S')|, where N(S') is the set of ci that are connected to some node in S'.
Now, to prove that there's a perfect matching between A and B, we use Hall's theorem in the other direction. Choose some subset of nodes in A, call it S. Then what is |N(S)|? Let's define S' as a subset of A' having BOTH copies of ai for every ai in A. Then we know by the previous paragraph that |S'| ≤ |N(S')|. Since 2|S| = |S'| and 2|N(S)| ≥ |N(S')|:
|S| ≤ |N(S)|, so there's a matching in the original graph.
I think it's wrong proof.
1) Forget about the case, when |C| = 2 × n, because in this case there are no intervals, that crossing the origin and this case can be easily solved, as mention above.
2) But if you have at least one crossing the origin interval, that it means, that |C| = m < 2 × n. After that you are not able to have perfect matching, because the sizes of components are different.
3) So, I suppose you want to say, that you have the matching, where one part is covered by matching full. But again you told: "Consider some set S', which is a subset of these a'i. Then because we have a matching, |S'| ≤ |N(S')|, where N(S') is the set of ci that are connected to some node in S'.". If you take S' = A', than you have: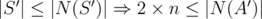 , but
, but 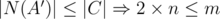 , contradiction.
, contradiction.
For ques B
Is this a valid test case ?
If yes
what is the answer for this test case
The answer should be 31 = 10 + 6 + 7 + 8 = max(10, 1) + max(6, 2) + max(5, 7) + max(2, 8).
But in the statement its given that
"There shouldn't be equal elements in the subsets."
In this case both the subsets have 2 elements.
That's "equal elements", not "equal number of elements" .
Oh, i thought that was stated in first statement of the problem.
I took it for equal number of elements.
Thanks for clarifying.
Well, this means that we should choose some elements from array a[], some elements from array b[], and no one from chosen elements are the same.
I see this line and I feel sick. I see this line in two problems and I want to leave competitive programming for another year.
I guess H is FFT problem so author wants to hidden it by letting that modulo in G :)
On contrary, I always pay respect to problemsetters who put this modulo in their problems. By putting it in problems where any modulo is sufficient we obfuscate which problems need FFT.
I think giving 109 + 7 in every single problem, including FFT ones is better way to obfuscate it. No one should use NTT anyway.
Giving 109 + 7 makes it harder to give larger constraints like 105
Then the model solution just sucks, author should come up with better algorithm.
I don’t understand how can mod 998244353 ever be a good idea. The author requires large constant factor to solve the original problem, and to overcome it they use some peculiar modulos that is known to be useful for a limited number of audiences. For someone to easily solve that problem, they should knew that “magic number” beforehand, and the fact that they have good primitive roots. Sounds pretty bad to me.
This situation is not much different than simply knowing NTT at all.
I doubt that. Splitting numbers in two groups is still faster than making computations modulo some number. And it works for every mod.
Karatsuba works for every mod, doesn't need too many modulo operations, has a nice constant, works exactly (no doubles) and if the use of FFT is complex enough — the problem isn't just reduced to a single FFT or one of garden variety D&C+FFT versions — the constraints are often long enough that Karatsuba can pass. Its only disadvantage is asymptotic complexity. Actually, even D&C+Karatsuba has complexity equal to Karatsuba only.
Well, Karatsuba is nice algorithm indeed :)
I disagree. Modulo is faster than splitting and then doing computations on pairs of doubles.
I don't like problems that require FFT with 109 + 7 modulo. Why is it better? Only because simple fractions like looks nicer? Not a big argument.
looks nicer? Not a big argument.
NTT has much shorter code, which is important in ACM-style contests, where you don't have any prewritten code, and it works absolutely with same speed. When I tested FFT vs NTT, difference in execution time was about 20%, and one of them was faster on G++, and another was faster on mingw, so they are absolutely equal in my opinion (only FFT requires slightly more memory, which can be critical in some cases).
I think I'll continue giving 109 + 7 in my FFT problems though :)
It is better because it forces you write more generic solution and doesn't indicate key idea just from mod (giving NTT mod in every problem is even worse, in my opinion). You can use NTT with two primes + Chinese remainder theorem if you dislike that. It's much slower though...
Good thing is that we usually know the authors before the contest
Yes-yes, you skip every my contest, I know.
I saw a possibly incorrect submission (see 38668742) for 981D - Bookshelves, while I have no idea how to hack it during the contest time.
The solution is simple, for dp[index][count], maintain the top 20 bitwise-and sum that ends at index with count blocks. It seems true to me that there exist cases which fail this solution(cases which you need some smaller and-sum in the middle-way).
So, can anyone suggest a way to generate the hack? Or there are some ways to prove that this solution is indeed correct?
PS. I hope these kind of submissions will fail systest... I mean, I hope the systests are strong :D
http://codeforces.net/blog/entry/59657?#comment-433649
Pls have look at it. I also faced the same issue, with my own solution. I expected it to fail :P
Can someone explane me how I got WA on test 5 in final testing and someone got WA on test 13 during the contest ?
As far as I know the first couple of actual tests aren't always the same as pretests. Your mistake is "dfs(1,0); -> dfs(last, 0)". I know about some people who hacked with a similar test so the test wasn't in pretests.
Thanks !
I saw mistake, but situation with testcases was strange to me :)
What can be the cause of Wrong Answer for this solution of D ? Link:
Same Problem Also wanna know why my code is wrong. My Solution of D
you take the max at each step, but it is not the best choose at this step
why how ?? what's the alternative one. and why this approach is wrong ?
Max(7, 8)&3=0 Min(7, 8)&3=3 in such solutions you need to remember all the answers and update the new answer with them
ohk got it. That's very silly one. thanks
I have no idea about the complexity of my solution for G. Only that is not bigger than O(n * q)
Link
But I got AC))
I have one main segment tree for calculating the answer and also store additional segment trees for each of the values 'x'.
It's not necessary that a range modification had common parts with some modified ranges before, because after the current modification, these ranges would merge together, so the total time complexity is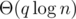
I thought about this, but they will be merged only in this 'x'.
The different 'x' doesn't affect the time complexity. One range modification will only affect at most one range after.
Hi everyone.
For problem D , Initially I read like, we can divide 'K' subsets in any order. (Not necessarily contiguous segments of array) .
Is it really possible to solve it ?
In last 25 minutes I read it again, and figured out Greedy-DP solution. which seems like HACK to me. And still the solution passed. I was hoping this solution to fail. Can someone tell me, is it possible to hack this solution ?
Basically I am picking up best 8000 values for each dp[i][j] , where 'i' is index, and 'j' is number of shelf's being used till index 'i'.
The same problem as you.
I enjoyed the problems, even if I didn't well. Thanks to the author.
Out of curiosity, am I the only one who found problem C easier to understand by translating the Russian version to English with Google Translate?
How to solve problem F?
http://codeforces.net/blog/entry/59657?#comment-433647
No test cases with
1<k<n-1for H? Top two both fail with suchk...Wow, indeed :) My solution fails due to an incorrect
assert(cur == 0);, removing it fixes the trouble. Perhaps I should be more careful with my assertion checks next time...WAAAAAAT XDDDD? Oh my holy Mike...
Lol, nice catch! Also: xD
Oops! Sorry, i thought these testcases are useless :/
Do you know what hour is it? It's rejudge hour!
People might feel like u r crazy , because, u want re-judge.
but they don't know, u would have rank-1 , if there would have been re-judge :P .
can some one suggest whats wrong in this code for D, thanks in advance ~~~~~
include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll dp[55][55];
ll ar[55]; const ll inf=(1LL<<60)-1;
int n,m;
ll foo(int i,int j)
{
if(j>m) return 0; if(i==n) { if(j==m) return inf; else return 0; } if(dp[i][j]!=-1) return dp[i][j]; ll p=0; ll ret=0; for(int k=i;k<n;k++) { p+=ar[k]; ret=max(ret,(p&foo(k+1,j+1))); } return dp[i][j]=ret;}
int main() {
memset(dp,-1,sizeof(dp)); cin>>n>>m; for(int i=0;i<n;i++) { cin>>ar[i]; } cout<<foo(0,0);}
~~~~~
When you have a problem that involves AND operation is a bad idea to use max because not necessarily if you return a max number you guarantee a better answer, for example:
What happened here? 4 is greater than 3 but if we return 4 we get the worst answer.
what about this submission?
Your crafting.oj.uz ratings are updated!
Will there be editorial for this contest?
http://codeforces.net/blog/entry/59713
Thanks a lot! :D
Can anybody please explain their approach for problem D.
A observation first: We will see if we can obtain in the final sum, every bit from 60 to 0. (We must find some configuration such that every shelf contains in the sum of the values that bit)
If we can obtain a bit, then we add it to the answer, and when we try for a new bit, we always respect the bits that are already found.
I have solved it using dynamic programming
dp[i][j][h]-> true or false, if we can put the firstibooks intojshelves such that each shelve has the bithin its sum. (And also respects all the higher bits found previously)I am not clear with this part "And also respects all the higher bits found previously" Can you please explain what do you mean by this line
Let's say for example that you are at bit 5, and you know that you have found good configurations that can have bits 8, 10 and 15. (The answer until now is 28 + 210 + 215). When computing
dp[i][j][5]we have to find some indexi2(smaller than i) such that sum(i2, i) contains 25 + 28 + 210 + 215, anddp[i2][j - 1][5]is also true (which means that the firsti2books can be put inj-1shelves such that their total sum contains 25 + 28 + 210 + 215)My code: 38668315
And what is brilliant about your solution, is that you are storing the already set bits in a number, not an array as I thought. Thanks a lot!
Where is editorial's link ??
http://codeforces.net/blog/entry/59713 Use Google Translate.
Thanks mate !!
Thanks for great contest!
How to solve H? Where's the solution?
Editorial for C problem:
https://letsdocp.wordpress.com/2018/05/28/codeforces-problem-useful-decomposition/
How to solve D ? Cannot understand the approach listed in the comments
How about the Editorial????
Editorial ??
Hello
English editorial will be ready in 2-3 days, sorry for inconvenience, i am busy with some school exams now
Now you can translate russian version with some translator like yandex
When will the editorials be posted?
Editorials are available on http://codeforces.net/blog/entry/59713
Does anyone have an editorial for the problems in this contest :(
See 5th comment above.
Can anyone please help me find a mistake in my solution for D.
Here is what I did:
dp[s][e][j]— stores the maximum possible beauty of j shelves when they contain books from as to aeThe answer to the problem is
dp[1][n][k]Here is my code.
Thanks in Advance
First,
s = (s&a[i]);must bes = (s&a[j]);.Second,This test case:
4 3 11 6 1 3Answer:3.Your output:0
11&(6+1)&3=3.But in your solution,
dp[2][4][2]=4.(6&(1+3)).It means that it not necessary to use the maximum value in
[L,R].ninja'd
Btw, there is also a second error in the
anddcomputation. The for loop needs to startj = i.This problem is not greedy in that way you assume.
dp[s][e][j] = max(sum & dp[i][e][j-1])doesn't always hold.E.g. take a look at the following example. If you want to make two bookshelves using the books
[7, 1, 12], then the best you can do is(7+1) & 12 = 8. However if you add a book[4, 7, 1, 12]and want to make three bookshelves, then the best you can do is4 & 7 & (1 + 13) = 4. Here you have to take a smaller value for the subset[7, 1, 12], namely7 & (1 + 12) = 5, to get a bigger end result. Because otherwise4 & (7 + 1) & 12 = 0.ok, got it, thanks a lot
In China. The contest in provinces is called NOIp. And we have two tests. The first test is printed on papers and one part is to read a program and write what it outputs. And then when I was taking a mock test and doing the part. I see the following four lines of the code: