


The 25th Central European Olympiad in Informatics will take place in Warsaw, Poland, during August 12th-18th 2018. The most gifted high school students from 14 countries will have the opportunity to prove their knowledge and skills in informatics.
The CS Academy team will organise the online mirror for this year's competition. The online mirrors will take place after the finish of each of the 2 competition days, having the same scoring format.
The online mirror schedules are the following:
Contest format
- The contest will be rated for all users.
- You will have to solve 3 tasks in 5 hours.
- There will be full feedback throughout the entire contest.
- The tasks will have partial scoring. The maximum score for each problem will be 100 points.
- There will be a time tie breaker, so two users having the same total score at the end of the contest will be further sorted by the penalty.
- The penalty will be equal to the first time they achieved the final score. Only submissions that increase the total score are taken into account. This means that after getting 50 points on a problem you will still have 50 points even after submitting a solution that gets 0 points and that the penalty will remain the same.
Facebook event
We created a new Facebook event. If you choose "Interested" here, you will be notified before each round we organise from now on.







You can find the online rankings here.
I must say that the problems are very interesting and unusual. Maybe some can say based on the results that they are pretty easy, but if you want to see some good problems everyone is welcomed to the online mirror :)
When I've reserved 5 hours from the life specially for the contest and closed it after just an hour
Is this olympiad for guys from high school or from primary school? I am disappointed that Poland prepared the easiest CEOI's day ever.
On the other hand, I'm happy I didn't spend too much time on it... but yeah, they're too easy. The organisers must be stuck in the last Polish CEOI. If day 2 is also this easy, there are going to be a lot more gold medals.
I know who we can bash for this though: Kamil Dębowski (Scientific Chair).
It's too early to say that one person is singlehandedly the reason. I would want a response from Kamil first until we start pointing fingers.
I said it as a joke, Kamil Debowski is Errichto
I did not perceive it as a joke xd. Actually I know almost nothing about CEOI organization, but I am really negatively surprised by these tasks (I woke up at 5:45 AM!!!). Some people have to be responsible for this poor selection and I suppose Kamil had some significant power here. Errichto care to explain after this prejudiced ostracism :P?
The contest was easier than I has expected it to be, and you are right to blame me. We expected a few 300's in the main contest, we got 12. Misjudging the difficulty happens, especially in problems that aren't complicated but instead require some "aha!" moment. I'm sorry for that, but for sure I can't say it will never happen again in a contest I'm responsible for.
How to solve Lottery 100% ?
Lottery was perhaps the easiest task as it requires almost no algorithmic knowledge. Here's the solution:
Lottery
Let Bi, j = δ(ai ≠ aj). Now, the distance between some two intervals starting at i and j is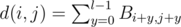 , this can be quickly computed in n2 memory using diagonal partial sums on B. The answer to a query kj is the array cj where, for each i = 1... n, ci = g(i, kj) - 1, where g(i, kj) is the number of values less than or equal to kj in the i-th row of the matrix d. We will read all the queries in advance and compute the matrix d row by row. Not surprisingly, the values in the rows are related. From d(i, j) we can compute d(i + 1, j + 1) as follows: d(i + 1, j + 1) = d(i, j) - Bi, j + Bi + l, j + l. Here, there's no need to actually store the matrix B, as we can compute its values easily. So, from the previous row of d we can compute all the elements of the current row, except the first element, in O(n). We can compute the first element directly by summing:
, this can be quickly computed in n2 memory using diagonal partial sums on B. The answer to a query kj is the array cj where, for each i = 1... n, ci = g(i, kj) - 1, where g(i, kj) is the number of values less than or equal to kj in the i-th row of the matrix d. We will read all the queries in advance and compute the matrix d row by row. Not surprisingly, the values in the rows are related. From d(i, j) we can compute d(i + 1, j + 1) as follows: d(i + 1, j + 1) = d(i, j) - Bi, j + Bi + l, j + l. Here, there's no need to actually store the matrix B, as we can compute its values easily. So, from the previous row of d we can compute all the elements of the current row, except the first element, in O(n). We can compute the first element directly by summing: 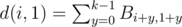 , also in O(n). We now "count" the elements of the current row by incrementing udi for all i, then we compute the partial sum of u, let that be v, and, for each query kj, add vkj to the i-th element of cj. Time complexity: O(n2 + nq), memory complexity: O(nq).
, also in O(n). We now "count" the elements of the current row by incrementing udi for all i, then we compute the partial sum of u, let that be v, and, for each query kj, add vkj to the i-th element of cj. Time complexity: O(n2 + nq), memory complexity: O(nq).
xD
Can anyone share the solution to Global Warming?
Key observation is that we can restrict our moves to taking prefix and moving it down by x. Once spelled out, both proving this and getting entire algorithm from this point is easy.
Can you share how did you get that observation?
My chain of thought was like: choose i and j, both i and j should be in the final LIS. then the result will be LIS[0, i[ + LIS[i , j] + LIS] j,n[.
The task now is to find x so that (LIS[0, i[ with end value <= V[i] + x) + (LIS] j,n[ with start value >= v[j] + x) is maximal.
I got stuck at that point and couldn't find a way to make my solution faster.
Thank you!
To be frank I did not quite get your way of thinking, but let me put it my way. Let's say we modify some subsegment [i, j] (we do not say anything about whether some points in it will belong to our final LIS or whatever). Let's say we move it down by y. We can note that we in fact can move down [1, i-1] segment as well, because moving down some prefix never decreases LIS. So it turns out that we can in fact restrict to moving prefix [1, j] down under the assumption that we moved our subsegment down. Moreover we can move it down as far as we can and it will not worsen our answer, so we can restrict our move here to x what almost proves my claim. There is second case to consider of subsegment being moved up, in which case we see that we can move suffix [i, n] by x up, but that is the same as moving prefix [1, i-1] down by x.
I was increasing a suffix. I think that decreasing a prefix is sign of being a sociopath. I bet you hang your toilet paper under!
Here is a rough explanation:
Let's use an observation: Every optimal solution can be described by either decreasing a prefix of the whole array, or increasing a suffix of the whole array.
Informal proof by induction: If we decrease a subarray i...j and we use one at least one element from that subarray, by decreasing element i - 1 as well, we never worsen the LIS. Thus, we can always extend the subarray to 0...j.
An analogous argument also proves that when we increase, we can increase the whole suffix as well without losing solutions.
Another observation lets us combine the two operations of decreasing a prefix and increasing a suffix. If we reverse the array, negate every element ti and negate x, we can use one function instead of typing two nearly identical functions.
In the solution, for every i s.t. 0 ≤ i < n, we find the LIS of prefix t0, t1, ..., ti that includes ti, and we find the LIS in ti + 1, ti + 2... such that the smallest element in the LIS is larger than ti - x.
The above can be found in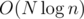 using an extension of this algorithm.
using an extension of this algorithm.
How to solve problem Cloud Computing?
Let's sort all computers and orders by Fi in a global array. Now we can satisfy an order only with computers which are later in the array. So let's go from the right to the left of the array, buy some computers and then sell it for orders.
We can do it maintaining dpij, what means maximal profit which we can receive processed the first i objects (computers or orders) from the right and we have exactly j cores. For the full task it's too large memory; so we can easily maintain only one layer dpj, recalculating it object by object.
Complexity is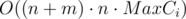 , memory is
, memory is 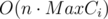
Here is a really short solution.
We combine the list of customers and computers, and sort them according to decreasing clockrate. If there's a tie, we place computers before customers. This ensures that if we have bought any cores, we can use them for any following customer. We use a DP with state UnusedCores with a transition very similar to coin-change DP, and after iterating over every item in reverse order, the answer is dp[0].
In task Lottery, my solution gave MLE. It was pretty weird since the memory is only O(n.q), so I decided to re-submit the same solution and it gave me an AC.
It would be nice if someone tell me if it was a problem with my code or with the server. Here are my code:
MLE: https://csacademy.com/submission/1713633/
AC: https://csacademy.com/submission/1715224/
Thank you very much.
P.s: sorry for the cancerous code. It was because I just switched to Java.
day 2 update:
You can participate in the online mirror for the second day. It will start in 4 hours. (1 hour after the onsite contest ends)
Has someone got a full solution to 'Fibonacci Representations Big' that is under 200 lines? (Excluding obvious loopholes.)
My solution (over 600 lines) maintains the sum pk in the Fibonacci base in canonical representation (no two adjacent ones). I compress adjacent blocks of
10and of zeros and maintain the compressed blocks in a BST. This way, a Fibonacci number can be added in logarithmic time (The blocks of10mostly shift to the left or right when carries occur and blocks of zeros only change near their border.), but I had to distinguish15cases here. The DP over the digits can then be written as a product of 3 × 3 matrices and precomputing powers of the transition matrix of10and0gets rid of the log from fastpow (when a long block changes and you have to recompute its transition matrix).Mine is 250 lines, I store differences between indices of consecutive 1s in a balanced BST. There's also no matrix exponentiation, only multiplication.
190 lines, including comments: link. There are some slides describing a solution, but they were meant to help in explaining, not to give the full explanation. I hope they will be uploaded to the website in a day.
A linear solution for each prefix would be:
dp[0] — the number of ways to handle 1's on the right so that they would "touch" the next 1 on the left (so, that next 1 must be changed to some smaller 1's).
dp[1] — the number of ways such that the next 1 on the left can stay in its place.
Quite short implementation of that: link.
Now, we can maintain intervals of type 000001010101, each represented by a matrix 2x2. We can either use BST or we can simulate everything once and gather all the intervals (or indices) that ever appeared, and then build a segment tree over that. I chose the latter approach because I don't like BST's and the tree is much easier this way. The BST solution is also posssible and allowed.
EDIT: and the alternative thing to store is what ksun48 described: distances between consecutive ones.
Done: https://ceoi2018.pl/tasks/