


→ Обратите внимание
До соревнования
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
20:53:37
Зарегистрироваться »
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
20:53:37
Зарегистрироваться »
*есть доп. регистрация
→ Лидеры (рейтинг)
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
→ Лидеры (вклад)
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |
→ Найти пользователя
→ Прямой эфир






Codeforces (c) Copyright 2010-2024 Михаил Мирзаянов
Соревнования по программированию 2.0
Время на сервере: 22.11.2024 20:41:23 (h1).
Десктопная версия, переключиться на мобильную.
При поддержке

I too got suck on this one when I first tried it due to strict TL.
Btw, just don't use anything for max (like function, macro or stl) just write if() else (), and you will be fine(probably).
I am still getting TLE :(
link
Can you please optimise my code ?
you dont need separate lca, it's just taking extra time. You may look at my code it's just of 150 lines
I didn't read your code but when the tree is a line, HLD maybe get TLE
Uhm.. I'm sorry, what? HLD on a line tree is just a segment tree. The complexity of query on that tree is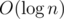 . On random trees HLD query complexity is about
. On random trees HLD query complexity is about 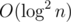
What about TLE on problem. Did you try to debug some edge cases? It seems like your solution is not working when n = 1
Some HLD codes can be RE for special cases
HLD assures O(log^2 n) per query (in this problem).
Especially when tree is a line,( there is only one chain) that is same as querying on sequence. Which is O(log n).
I solved it in another online judge, using HLD. I guess there might be mistake in your code but i couldn't find it.. sorry
Yes i found out the mistake but unable to understand why it's happening :(
My Accepted Soln- link in 0.33sec
I just changed the behaviour of my ancestor 2-d array from anc[i][j] to anc[j][i] and it got accepted but the problem is even in both cases it has samecomplexity of O(15*sz) but anc[i][j] is giving TLE and anc[j][i] is giving the answer within time limit.
Please help me to find out the mistake that i was doing.
Well, IMO, this is just cache localisation. While finding the ancestors, in case of lca we are using anc[j][i] and then immediately anc[j][i+1] which helps cache localisation.
On the other hand, if you are using anc[i][j] and then anc[i+1][j] there is a gap of around 15 between these and it is unable to use the cache efficiently.
Generally this doesn't matter much but this question seems to have a very strict TL.