


Привет, Codeforces community!
Когда я начинал свою олимпиадную карьеру, я постоянно слышал что-то в стиле "некоторые операции выполняются быстрее других, некоторые типы данных медленнее, другие побыстрее". Я это понимал, понимал даже причины, но меня интересовала конкретика (т.е. "насколько быстрее"), которую я не получал. Теперь, когда я на втором курсе, имею некоторое представление о работе компудахтеров вычислительных машин, оптимизационной работе компилятора и возможных проблем при реализации бенчмарка, я могу попытаться всё-таки выяснить конкретные цифры, а заодно и поделиться ими. Думаю, новичкам это будет интересно, как и мне в своё время.
Всех заинтересованных прошу под кат :) Начнём с краткого комментария по поводу флагов компиляции. g++ (как и clang++) поддерживает 4 уровня оптимизации (включаются флагами -O0, -O1, -O2, -O3) + флаги для конкретных видов оптимизаций. Как правило, на онлайн-джаджах используют -O2, но в мой бенчмарк запускается с флагом -O1. Почему? Ответ прост — -O2 слишком хорошо оптимизирует — сворачивает циклы, где (в нашем случае) не нужно, порою выбрасывает условия из циклов (исходя из своих эвристик) и так далее. Мы этого не хотим, поэтому и пользуемся -O1.
Перейдём, пожалуй, к методике замера. Тут я попытаюсь объяснить, почему бы не сделать просто что-то вроде...
begin_t = gettime();
a = b + c;
end_t = gettime();
... и сказать что в end_t - begin_t теперь время, затраченное на одну операцию. Проблемы тут две — во-первых, сам вызов gettime() с большой долей вероятности займёт больше времени, чем выполнение нужной операции. Кроме того, разница времён получится ничтожно мала и при каждом запуске программы будет менятся в огромном (в процентном соотношении) диапазоне. Плохо.
Давайте тогда запустим много раз одно и то же:
begin_t = gettime();
for(int i = 0; i < MAX_ITER_N; i++)
a = b + c;
end_t = gettime();
Где MAX_ITER_N будет достаточно большим (порядка 107 — 109).
Уже получше, но есть несколько проблем. Во-первых, компилятор запросто может решить, что результат выполнения операции a = b + c всегда один и тот же, нечего выполнять это много раз, и вместо цикла выполнить операцию всего один раз. Более того, если после всех манипуляций ничего с переменной a не делать (вывод на экран, возврат из функции, что-либо другое), компилятор (даже при оптимизации -O0) выбросит вовсе строчки из цикла — как ни на что не влияющие операции. Есть еще несколько вариантов, где компилятор из благих побуждений может подсунуть свинью нашим замерам. Во-вторых, даже если всего этого не произойдёт, мы ведь дополнительно замеряем время операций сравнения и инкремента (я про i < MAX_ITER_N; i++). Нехорошо.
Давайте тогда сделаем следующим образом:
int g(){
int x = 0;
for(int i = 0; i < MAX_ITER_N; i++)
x = i;
return x;
}
int f(){
int x = 0;
for(int i = 0; i < MAX_ITER_N; i++)
x = x + i;
return x;
}
...
begin_t = gettime();
res = g();
end_t = gettime();
bad_delta_time = end_t - begin_t;
begin_t = gettime();
res = f();
end_t = gettime();
clean_time = end_t - begin_t - bad_delta_time;
Таким образом, мы вплотную приблизились к тому, чтобы мерять "чистое" время операций. А теперь, чтоб получить количество операций в секунду, мы количество выполненных итераций на затраченное время.
Ну, вроде, основные моменты методики объяснил (если прочитать мой код, там немного иначе), теперь перейдём к результатам.
Важный момент — на Codeforces используется 32-битный компилятор, поэтому бенчмарк был скомпилирован с опцией -m32. Насколько мне известно, на серверах Codeforces используются процессоры Intel, поэтому результаты на своём Intel i5 2430M я считаю более-менее соответствующими тем, что в теории могут быть на Codeforces.
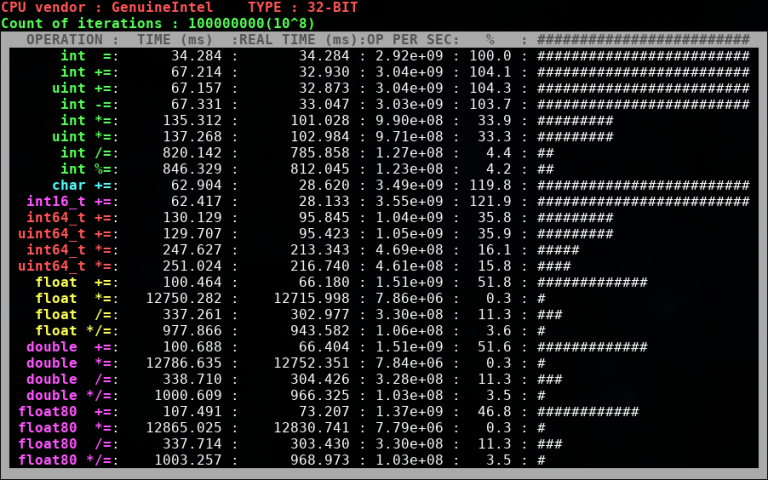
Ну, во-первых, 64-битные типы данных уступают примерно в два раза по производительности 32-битным типам. Во-вторых, операции деления и взятия по модулю намного тяжелее умножения (несмотря на то, что при реализации длинки асимптотика и у деления, и у умножения O(N^2). Ну и для тех, кто сомневался в том, что знаковые и беззнаковые типы одинаковы по производительности — видно, что таки одинаковы.
Возможно, у вас возникнет вопрос по поводу умножения чисел с плавающей запятой (с чего это вдруг "умножение + деление" по времени занимает меньше, чем просто "умножение", причём существенно). Тут объяснение есть. В моём бенчмарке при умножении дробных чисел на i-ой итерации в переменной-результате хранится, по сути, значение i!. Проблема в том, что начиная с некоторого момента это число не помещается в действительный тип и после этого тип хранит особенное значение inf. Понятия не имею, почему работа с этим значением медленнее, чем с "обычными", но факт остаётся фактом.
Надеюсь, эта информация кому-то поможет.
Ссылка на код моего бенчмарка, если кому-то интересно
Буду рад конструктивной критике и комментариям экспертов!
P.S. На самом деле, не будь "написание бенчмарка" лабораторной работой в универе, статьи наверняка бы не было :)
P.P.S. Рано или поздно я переведу эту статью на английский.







Основная беда в том, что нет, не приблизились =). Простейший тест "int +=" представляет из себя цикл из 5 ассемблерных операций: add, and, add, cmp, jne. Меряешь ты время одной итерации цикла, при этом померять хочешь только первую операцию add, которая выполняется пожалуй раз в 5 быстрее, чем одна итерация цикла. Можно попробовать расширить тело цикла, чтоб там было много операций add, и после этого уже мерять.
По поводу теста с умножением даблов, можно попробовать домножать на что-то типа 1.00001, чтоб не получить переполнение. Думаю, что должны получиться более адекватные результаты.
Кстати говоря, современные профайлеры, как минимум у XCode, в некоторых случаях умеют как-то искать ботлнеки, с точностью до времени затраченного на одну ассемблерную операцию.
А вообще, когда опускаются до настолько низкоуровневой замерки времени, то начинают говорить о стоимости операций в тактах центрального процессора. Вот например сходу гуглится: статья на хабре.
Да, я понимаю, что в цикле помимо тестируемой операции осуществляются еще несколько других (правда не знаю, откуда там взялся and, godbolt говорит, что там всего 4 операции). Но я поэтому и отнимаю от времени, затраченного на выполнение тестируемого цикла время выполнения цикла "int =".
По поводу умножения даблов, адекватные результаты я в принципе могу получить и из разницы времени "double */=" и "double /=", в теории. Но акцент был на другом — работа с inf по какой-то причине очень медленная, и что не стоит с использованием этого значения перебарщивать. Для спортивного программиста (а целевая аудитория тут всё-таки они) это, по-моему, важнее, а время "double *=" они в принципе и сами по табличке понять могут :)
Да, в теории можно не париться и прогнать бенчмарк через valgrind (точнее callgrind), но свой велосипед краше и
его можно сдать как лабу.По поводу последнего замечания — да, согласен, в "прикладном мире" это правильнее, более того, надо бы еще попробовать получить разного рода промахи кеша, непредсказуемые/совсем не разворачиваемые конструкции, случайно срабатываемые ветки условий чтоб branch predictor зафейлился и т.д., но опять-таки, повторюсь, ЦА моей "статьи" — всё-таки спортивные программисты, и я почти уверен, что большей части из них будут полезными не столько такты, затраченные на операцию, сколько цифры вида "операций в секунду". Хотя я не исключаю, что кому-то полезнее иное.
В целом, спасибо за отзыв! :)
Ой, прости, а это я и не заметил в первый раз =) Но все-таки цикл "int =" даже с -О1 оптимайзится до просто цикла с пустым телом:
Из твоего же бенчмарка
x &= MOD_MASK;Я понял, просто в скрине с результатами оно все еще подписано как *=, и вводит в заблуждение.
Хм, действительно оптимайзится. Есть идеи, как добавить в цикл присвоение и чтоб оно не оптимайзило?
Да, завтыкал чего-то :)
Окей, в скором времени переделаю
Для того чтобы не оптимизировалось можно добавить volatile, а чтобы уменьшить влияние цикла использовать #pragma GCC unroll 10. Как то так.
Я правильно понимаю, что тогда переменная будет дёргаться каждый раз из памяти при таком подходе, а не из регистра?
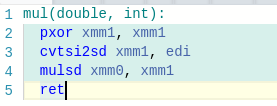
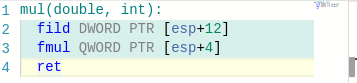
По поводу чисел с плавающей точкой. По умолчанию в -m32 режиме отключено использование sse инструкций что приводит к существенным проблемам с производительностью чисел с плавающей точкой, чтобы от этого избавиться нужно добавлять -mfpmath=sse. В -m64 sse2 включено по умолчанию, поэтому там эта опция не нужна.
Ого, спасибо большое! Но этот флажок на CF выключен, если судить по этому. Вы не в курсе, в MinGW ситуация такая же как и у g++?
Кстати мне так и не удалось получить увеличения производительности (обещанного в статье) в простеньких тестах (возможно нужны случаи посложнее), единственный бонус от fpmath=sse это уменьшение используемой памяти на 20Кб :). Для тестов использовал "Запуск" со следующим кодом.
P.S. Насчет MinGW к сожалению не знаю.