


Hi everyone!
I would like to invite you to my second Codeforces Round, which I have made with my friend and Snackdown partner Jeel_Vaishnav.
With that said, I bring to your attention our new Codeforces Round 523 (Div. 2) that will take place on Nov/22/2018 18:45 (Moscow time). If your rating is less than 2100, this round will be rated for you; otherwise, you can participate out of competition.
I would really like to thank Jeel_Vaishnav for his help with preparing problems, cdkrot for coordinating our round and Um_nik, vintage_Vlad_Makeev, Aleks5d, KeyurJain & Mahir83 for testing the problems. I would also like to thank MikeMirzayanov for Codeforces and Polygon platforms.
You will be given 6 problems and 2 hours to solve them. Scoring distribution will be announced later.
Link to My Coding Library for those interested :)
Good luck! :D
UPD: Scoring Distribution: 500-1000-1500-2000-2500-2750
UPD2: Editorial






Your previous contest was really a balanced one, hope this one will be the same, Indian setters :D
Another round from Ashishgup. Really excited :)
Please put this post on Home.
vintage_Vlad_Makeev's handle changing color in every post is kind of record lol.
he is chamaleon of codeforces
I think gritukan wants to beat the record of Mhammad1 for the maximum rating change in codeforces history.
I don't trust this emoji :)
I become Div. 1 in your last round, but it would take me a huge effort to do it again this time :)
let me guess, all the problems can be solved using your library :)
Hope we all have a good rank! (I want to become blue :D)
and again I am very excited about the contest by Ashishgup.
Because of this blog on Quora.
Good luck Ashishgup!
I will put my best effort to become green :P
I'll put my best effort to become cyan :P !

My color was changed at previous Ashishgup's contest , hopefully I'll do that again ^^
Finally, I am green again :P
Yeah, Congrats ! Finally, I'm cyan :P !
I hope it will be great contest
For Chinese players, it is necessary to stay up until the early hours of the morning, I hope this contest can be rated normally.^_^
:D
Good Luck
Why we don't have interesting contest theme/character anymore? :(
God keep my rate above water!
Seems like we are going to have another unrated round
Dont you ever say that, Unrated round is not a round, its just problem set with standing!
Well, It's already unrated for you :d
but it is rated for my oth... OOPS
is it just me or 502 bad gateway's coming ?
It takes too long for the site to upload and sometimes i get 503 error. Will the problem be solved?
I saw signals of a DDos attack...
unexpected dos-attack incoming
Its 5 minutes before the contest and the website is already showing 502 Bad Gateway and not loading properly.I dont want this contest to be like the last one please.
Some serious connection problems from here. So slow loading pages and lots of
502 Bad Gateway.I've just checked 'downforeveryoneorjustme', it also points out to that problem too:((((
delay again(
ddos again?
delay...
Please dont start the contest untill the problem is solved
Should we participate? I can only acces codeforces on my phone...
Code on your phone :)
True!!
I can't believe it 10 minutes delay :(
I barley have battery in my laptop for two hours :(
Consider charging it
if youre having problem use these :
http://m1.codeforces.com, http://m2.codeforces.com, http://m3.codeforces.com.
Problem A O(S) solution can't hack, its passed test: n = 1 , s = 10^9 :) 46079712
Tried this hack as well and it passed in 1.2/2 sec lol
Same 46069414 1996ms/2000ms
feelsbadman
Looks like codeforces have very fast processors.
Is this work of a compiler or processor?....
The operations like arithmetic, etc. are performed by the processor. Compilers may optimize the code somehow but eventually it's the processors performing the execution of the program. You'll get to know more about this kind of stuff when you study computer architecture as a part of your curriculum.
Same , I got -50 point since tried to hack this solution with n=1 , s=1e9 :'( 46068920
I think the contest and the difficulty of the questions could've been more balanced although I really enjoyed struggling with the questions it is kind of obvious from the amount of people who solved each problem that the difficulty gap between questions 1 — 3 and 4 — 6 is a bit much Anyway, as I said it was really challenging and I enjoyed thinking about the questions and I hope https://codeforces.net/profile/ashishgup will provide us with more of this
What is the hack for B?
I also want to know :( dont understand whats wrong with my code
i have this one
5 10
2 2 2 2 10
the answer is 6
Really good problemset.
Anyone who solved E/F can share their approach?
E: if a constraint k1 is immediately below (as in there's no other in between and k1 is in the subtree of k2) other k2, the constraint k2 will get subtracted by k1 since you need k1 and it will also appear in the other. Now, group the vertices by "first ancestor that has a constraint" and the problem becomes min-cost max-flow
F: root in any R. You can get the amount of subtrees and the sizes in O(N * K) questions. Now, you can "walk" to the side that has the "heaviest" subtree until you get to the real root. This solves it ok for small K's. For large K's, get random paths and mark the vertices that belong to the path in O(N). There's a very high chance that the most visited vertex is the root.
Is F supposed to be just randomly select 2 points and check to see if they're both leaves, then isolate the root from the path? That's the idea I got, but no time to code.
I too thought so but wasn't sure, though had some time.
I have the same idea, but haven't enough time to debug.
This solution should be good. You have at lest 1/4 chance to find this leafs if you take two random vertices.
For k=2 probability is 1/8. Because it is 1/2 to pick a leaf and 1/4 to pick a leaf from different subtree.
I couldn't solve this in the contest, but I had a similar idea. I'm explaining your comment in a little more detail.
Choose two vertices a and b, arbitrarily. Iterate over all the other vertices x and query if b lies between x and a. If that is true, then assign b = x. At the end of this procedure, you have that b is a leaf with n queries.
You can repeat this process for a, and ensure that it is a leaf as well.
However, You cannot assume that the root would lie on the path between the leaves a and b. This can be checked in O(n) queries by finding the length of the path between a and b.
And this is where I got stuck.
Are you suggesting that we could do a probabilistic approach after this? Because a and b would be in different subtrees with probability =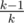 ? Does anybody have a deterministic algorithm for this?
? Does anybody have a deterministic algorithm for this?
Yes (I did it exactly the way you described). The probability that you don't find a path containing the root using this approach is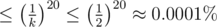 . Then the probability of getting accepted is
. Then the probability of getting accepted is 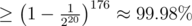 . Sounds good enough for me.
. Sounds good enough for me.
First use n-2 query to find a leaf, and then randomize select another vertex, fail probability is now (1 / k)50 (reserve 10n query for the root finding).
Nice, even better. Also notice that you can find the root with a Quick-select approach, which should be a lot better than 10n.
After the contest I wrote a deterministic solution for problem F: Code.
The idea is to start at a non-leaf node and go up to the root step by step. If we are at node X and X is not the root, we need to figure out which subtree of X is the largest one and what node in this subtree is the closest to X. This could be done by partitioning all the other nodes by subtree using at most KN queries, but it would exceed the allowed number of queries for large values of K. To fix this, observe that we can stop partitioning the nodes after looking at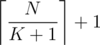 of them. For the remaining nodes, we need just to see if they belong to the largest subtree. With extra N queries, we can figure out the node in the largest subtree that is the closest to X. In total, we would need less than 2N queries at each step.
of them. For the remaining nodes, we need just to see if they belong to the largest subtree. With extra N queries, we can figure out the node in the largest subtree that is the closest to X. In total, we would need less than 2N queries at each step.
B was really good. :)
again a very good contest by Ashishgup.
Why this nlogn approach getting TLE at test case 10 in D problem.
https://codeforces.net/contest/1061/submission/46081755
this works O(N) for set.
How to solve this question D then?
I checked out it on multiple website. It says set and multiset has complexity O(logn)
http://www.cplusplus.com/reference/set/multiset/lower_bound/
But it's s.lower_bound(val)...
You need to call
st.lower_bound(val)instead of what you have written.How this is log(n)?
Because the reference says so
Calling lower bound on the set is log n because it knows it is a set, but if you use regular lower bound on the iterators it just steps through linearly until it reaches the answer.
Okay. That's cool. Thanks. Nice hack btw.
any idea about the 8th pretest for D?
How to solve C?
It's a kind of DP problem.
DP & Divisor Problem = O(N) * O(D^1/2)
So total number of operations is about 100,000,000... (N = 100,000, D = 1,000,000) I think this is correct approach because the time limit is 3 seconds...
Let, dp[i][j] = number of good sequences of size j using elements from 1 to i and dp[i][0] = 1 for i = 1 to n. Now, for every divisor x of a[i], dp[i][x] = dp[i-1][x] + dp[i-1][x-1]. We can reduce the first dimension of dp array by iterating divisors in non increasing order for every element.
Why do we need to iterate the divisors in non-increasing order ? Also can you please show how the solution works for some sample case, thanks.
To reduce the first dimension of dp array. Let x be divisor of a[i]. We need dp[i-1][x-1] and dp[i-1][x] because we need to know how many good sequence of size x-1 and x can be made using elements upto i-1. So current element(ith) can't contribute in this count. If we ignore the first dimension and iterate divisors in non increasing order then for every divisor x, dp[x-1] and dp[x] is guaranteed to be the count of size x-1 and x up to i-1 elements since for each x we didn't make any update on dp[x] or dp[x-1] till now due to current element as a result of iterating them in non-increasing order.
Consider 6 as current element. Divisors are 1,2,3,6. Take them in non increasing order. First comes 6 , dp[6] = dp[6]+d[5] as dp[5] is count of good sequence of size 5 up to previous element. Then 3, dp[3] = dp[3] + dp[2]. dp[2] is count of good sequence of size 2 upto previous element. And so on. If we iterated in increasing order we would have updated dp[2] before dp[3] due to current element and while updating dp[3] we would use this incorrectly updated dp[2].
Taran106 was much faster at typing than me. Consider this to be an expansion to his excellent answer.
Let's iterate the array from left to right. At each position we will update our answer dp[], where dp[5] gives you the number of good subsequences which have 5 elements, dp[6] gives the number of good subsequences with 6 elements, and so forth. The answer for C will be the sum of these dp values.
Let's say we iterate the values and at some point we arrive at value 9. We want to update dp[] to consider all subsequences which can use this particular 9. Can we continue a subsequence which has 5 elements? No, because 9 would be the 6th element and 9 is not divisible by 6, so this would not be a "good" subsequence according to the problem statement. Ha! Let's look at the divisors of 9: {1,3,9}. Clearly we can only continue subsequences where this 9 will become the 1st, 3rd or 9th element. So for each divisor: dp[divisor] += dp[divisor-1] (Example: if we had 81 ways of creating a subsequence with 2 elements, then we will have 81 new ways of creating a subsequence of 3 elements).
You might be wondering: isn't it slow if we iterate all values and then find the divisors for all values? Any number < 1000000 isn't actually divisible by many other numbers, so there aren't that many divisors. The only question is how do we find them efficiently. There's probably some fast way to do this as we go along, but I chose to pre-calculate divisors for all numbers.
Here's the code for pre-calculating divisors:
I'm ready for -100 rating XD . Gratz to all who performs well.
Is E solvable by LP solver?? If can be, can someone give link to their solution using LP solver. Or can you point you some resources for LP solvers explaining their algorithm and rough complexity and also your library code..
Or we need to convert into max flow min cost network somehow?
Intended solution was min-cost max-flow. We don't know about LP solver
Sorry, this is F.
This can be solved using simple randomized algorithm. See my code for ref: 46083309 Right now this WA because I messed up with calculating tree height -_-
Idea is simple — randomly select two nodes. There is more than 50% chance that both of them will be leaf nodes. To check if the selected nodes say
xandyare indeed leaf, queryn-2times and find out how many nodes are between them. Repeat for 50 times or so. It ishighly likelythat you will get two leaves. (As high as probability that quick sort is nlogn).Now you know the path between
xandy. So the root node has to be one of them. Just query for each of them to find who is the actual root.I think you're talking about F, but they're talking about E :)
It's not enough to find 2 leaf nodes (they don't always have a path that goes through root). For example, in the sample picture the probability of finding 2 leaf nodes which have a path through root is 15% (8/15 * 7/14).
I've got an explanation for how I constructed MCMF graph in a comment below, if you're curious.
is D greedy? It passed pretest but it seems suspicious
What greedy do you mean?
Yes. keep assigning the latest TV where show is completed. And also check if that TV should be given and taken or should be kept with you.
Is there any proof that this greedy approach works?
For question A why solutions with O(s) complexity passed. When I tried to hack it with n=1 and s=1000000000 I got an unsuccessful hack and the time was 608ms.
Really cool problem set!
Although, I do wish the contest was 2.5 hours instead!
i agree
Ignore.
What was the pretest 10 for Problem C?
Problem F was really nice, but it needs more time to solve.
Was O(n*sqrt(ai)) complexity in problem C too much or it could get AC?
I used an approach with that complexity and got pretest passed in ~1500ms. Taken implementation into accounts, maybe? ;)
Does anyone solve E using mincost flow?
probably the way I solved B is the worst yikes ..
I can't look at my code so I don't miss more iq
The statements were clean and easy to understand, very nice :D
My approach for E:
First thought when looking at the problem: small n, lots of constraints, choosing vertices to maximize something, sounds like flow (this is CF so I am very skeptical of seeing flow because flow problems are very rare here, but I had a good gut feeling about this).
It's not immediately clear how to solve this problem using flow. For simplicity, let's imagine the problem with only one candidate and one set of demands. It does seem like some kind of choice-making thing, and one's initial thought might be to make a bipartite graph with demands on one side, and cities on the other, with edges from a demand to everything in its subtree of capacity 1, and edges from the source to each demand with capacity equal to the number of nodes required by that demand. The costs of the edges into city i would be - ai. This, unfortunately, runs into some problems because there isn't any way to ensure that all the demands are met, and the flow for each particular city that gets chosen will be overcounted depending on how many demand subtrees that city is a part of.
Here comes what I believe is the key observation: if v is a descendant of u, then v's subtree is entirely contained in u's subtree. So, consider two demands (k1, x1), (k2, x2) where k2 is a descendant of k1. Now, for everything in k1's subtree that is not in k2's subtree, we can create an edge from the demand (k1, x1) to that city, and then we can create an edge from the demand (k1, x1) to the demand (k2, x2) with capacity x2. This way, the constraints from both demands are now taken into account and any compatibility issues will be reflected in the flow. However, one last thing is that we need to make sure that all the demands are met, so the way we do this is by making the cost a pair of ints, where the second number is the - ai when appropriate and the first number is - 1 if the edge is entering a demand node, and 0 otherwise. This way we will force our algorithm to use all the demands, if possible.
It turns out that adding the second candidate in is not bad, we simply create an identical graph but mirrored and add it as a third "layer" to our graph, with the mirror of the source being the target of course.
When we run MCMF, we first check to see if the first value is as negative as possible (this I believe should be the negative sum of all the x's in the demands) and if so, the second value should be the negative of our answer.
EDIT: I realize this explanation is not incredibly clear, but I think my code is pretty clear, so here's the submission: 46121195
Can Anyone explain how to solve B and C?
Problem B:
The order of the columns doesn't matter, so we can safely sort them in non-descending order. We can see that we must keep at least one block in each column.
Let's denote
Highestas the currently highest block kept, initiallyHighest = 0.Let's denote
Maxas the maximum height of all columns,sas the total number of blocks initially.Traverse through the sorted columns, with each column, update
Highestbymin(Highest+1, Height[i]).Let's denote the minimum number of kept blocks as
Min, initiallyMin = n. AddMax - HighestintoMin, thus, the answer would bes - Min.Problem C:
This is a dynamic programming problem. Let's denote
dp[i][j]as the number of valid subsequences that has i elements and the rightmost one is the jth one in the original array.Thus, the recursive function would be: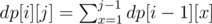 .
.
Obviously, we can't build an entire dp 2D-array (guaranteed TLE/MLE given the problem's constraints). Therefore, we'll only consider (and keep the dp values only in) the cases when a[j] is divisible by i. To do this, vectors and two-pointers techniques are required.
You can see my solution for better understanding: 46075711.
Hope these guides help! :D
Hi iristran911, your explanation for Problem B is really nice but your implementation seems complicated.I followed your explanation and implemented it in a very easy way. see my submission: 46105126
Nice one! :D
I did mess up with things a little bit (kind of frustrated for submitting wrong B thrice previously), so the source code for B didn't look so good ;)
C is dp + number factorization. At first find all the factors of
arr[i]which are not more thani.fbe the array of all those factors. For every number in f, the ans isdp[f[i]-1]. Updatedp[f[i]]todp[f[i]]+=ans[f[i]].It was really annoying that formula for problem D was b — a instead of b — a + 1, which is more intuitive. Still, nice problem, good contest.
Yes, that was nice. This contest was really well written. All tasks have pretty good and short solutions. Thanks to Ashishgup for that contest.
It is just use x=x-y then it will be b-a+1
https://codeforces.net/contest/1061/submission/46079795
How can this code work for n = 1 and S = 10^9? It should give TLE since the loop is running 10^9 times. Can anyone explain this, please? It cost me 1 unsuccessful hack.
Because the constant factor is super low. This isn't something with arrays and mods, this is just straight addition.
And computers become faster and faster nowadays. It's not like 10^6 operations will take 1 second...
The CF servers are really fast. That's it. If you do a for-loop of 1e9 iterations, it runs is less about 1 second. Also TL for A is 2s. You can try in custom-test.
Why is this code: https://codeforces.net/contest/1061/submission/46085323 giving RTE? Please help, thanks.
Deleting elements directly on a set while you're working on that exact set will alter, or worse, mess up the entire iterators of that set completely. You should consider keeping the about-to-be-deleted elements in a dummy vector, and delete those after the traverse of that set is done.
Okay got it! Thanks a lot! :)
You are erasing and iterator from set. So when it do it++, it doesn't belong to the set. You should first move, and then erase. Some like:
Thanks a lot! :)
I never thought that O(N*sqrt(N)) be accepted on problem C. I just.. used all time to find better solution but failed.
Back to the blue ;(
Same. Thought we need O(n*log(n))
Why in Problem A if you use Ceil test 35 gives WA?
It should be ceil(s*1.0/n)
But i used float?So, don't need to use this "*1.0". This is my code 46067360
Daily reminder:
Never use ceil() function. Instead of using ceil(n/k) use (n+k-1)/k
If you want to use ceil() use it like this:
Thanks,but i changed my type o variable to double and the code receive accepted.And I understand your tip I'll use in nexts contests
Use double instead of float ... 46090088
I just realized this 1 min before you replied, but thanks for help.
random solution in F is intended? It seemed some people use random solution get accepted, and some get wrong answer on test 130~.
Since there are at least leaves, the probability of a pair of random vertices being a pair of leaves is
leaves, the probability of a pair of random vertices being a pair of leaves is  , so the probability of fail per test is
, so the probability of fail per test is 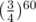 . I doubt this is breakable.
. I doubt this is breakable.
Two leaves must be at different side of root, so probability is 1/8. (7/8)^59=0.037%. Because of many test cases, it is dangerous.
Here is an approach that only fails in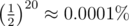 .
.
It is=) I got WA 169 with this strategy. As mentioned above, it's 7/8, not 3/4.
http://codeforces.net/contest/1061/submission/46085722 — WA (in systest) http://codeforces.net/contest/1061/submission/46090449 — AC
The only difference in codes is random seed :(
I used a deterministic approach for small K and random approach for large K. It makes the probability of failing smaller.
nice round realy thanx
In my opinion, the point difference between A and B should have been more than 500.
Really good questions and good contest by Jeel_Vaishnav
Test 43 of D- anyone knows what it is?
Update: I found the mistake.
Could you tell us what is the mistake if we fail in test 43?
I was maintaining a set of available tv's for a current time and this set was sorted in ascending order — the correct is descending as picking tv with latest finish time is optimal.
Strange that it passed 42 tests!
Thanks for your reply!
I am also strange that I can pass 42 tests luckily...
descending order according to the start time or end time? could you elaborate a little
end time. I add a tv to set when it becomes free. It will get free at endtime.
what I am is doing that for every tv i, I find that tv whose start time is greater than the end time of the current tv and continue this process until the set is empty or the cost of adding the tv to the current tv set is greater
Solution link:
https://codeforces.net/contest/1061/submission/46100043
What is wrong in this approach?
I am unable to find what went wrong in B, I tried various tests but all of them are giving correct results. Since the test at which it failed is very large, I could not find the bug. Someone please help. Code
UPD: Got the mistake. :)
Well that was an embarrassing contest for me... I only solved A. But the problems were good!
Okay, so I got his problem while solving Problem C.
My code is NlogN where N is 10^6 (pre-computation). I have used an ArrayList (Java) to store all divisors for all 10^6 numbers initially.
It's getting time-out due to some reasons which I am not able to understand.
My code: my code
Can somebody look into this?
Someone know's why my sol: http://codeforces.net/contest/1061/submission/46083785 gets other answer on gnu and mvc?
WA in test case:43 of problem D
https://codeforces.net/contest/1061/submission/46100043 Couldn't find any error in the code.
嘤嘤嘤
Can anyone tell what is the error in test case 19? Please help me I have spent 1 day searching for the error but still could not figure it. https://codeforces.net/contest/1061/submission/46125841
any help bro, i m also stuck there?
Using multiset instead of set solved my problem.