


Предлагаю здесь обсудить задачи. Как правильно решать I?
→ Обратите внимание
До соревнования
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
4 дня
Зарегистрироваться »
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
4 дня
Зарегистрироваться »
*есть доп. регистрация
→ Трансляции
→ Лидеры (рейтинг)
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
→ Лидеры (вклад)
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | maomao90 | 163 |
| 2 | Um_nik | 163 |
| 4 | atcoder_official | 161 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 157 |
| 8 | TheScrasse | 154 |
| 9 | nor | 153 |
| 9 | Dominater069 | 153 |
→ Найти пользователя
→ Прямой эфир






Codeforces (c) Copyright 2010-2024 Михаил Мирзаянов
Соревнования по программированию 2.0
Время на сервере: 19.11.2024 06:47:53 (l1).
Десктопная версия, переключиться на мобильную.
При поддержке

I решается жадно. На каждом шаге пробуем посмотреть очередной фильм. Тогда складываем в вектор все уже посмотренные фильмы, сортируем его по времени и жадно смотрим.
Жадно смотрим — можно подробнее?
для каждого студента поддерживаем время, когда он закончит смотреть какой-то фильм — endi и предыщую красоту фильма ci, для очередного фильма пытаемя из всех свободных студентов выбрать студента с максимальным ci, но меньшим, чем красота текущего фильма.
Я вроде такое и писал, только у меня WA3. Так и не понял в чем подвох.
upd. кажется понял, неверно выбирал
А почему не студента с максимальным временем окончания фильма? Для вашего алгоритма, как я его понял, есть простой тест:
4 2
1 2 3
3 4 1
5 6 4
2 3 4
Пусть 1й студент посмотрит 1й фильм, а 2й студент 2й фильм. Тогда для 3 фильма мы выберем 1го студента, т.к. красота его фильма больше чем у 2-го, и для 4-го фильма уже не сможем выбрать никого. Или я что-то не так понял?
ключевое слово — сортируем, так этот алгоритм валится тестом еще проще
100 200 5
1 2 4
300 400 3
А куда именно жадно смотрим? Я ниасилил придумать жадность в этом месте, и решил с помощью наименьшего покрытия графа путями %)
Авторское именно такое — покрытие графа путями. Но на контесте в УрФУ все сдавали жадину.
А как именно? я делал двудольный граф. Ребро из i-ой вершины левой в j-ую правой если можно посмотреть фильм j после i-ого. Находим паросочетание максимальное, строим новый граф неориентированный, в котором есть ребро (i,j) если (i,j) или (j,i) есть в паросочетании. Далее помечаем все компоненты связности в этом графе пока есть студенты.
Еще пробовал искать по очереди паросочетания минимального веса мощностью 1,2,.. n, и лучшее выбирать.
А можно узнать суть 19 теста?
У меня почему-то такое ВА27 получало упорно.
У меня тоже :( Из-за этого зафейлил контест. Так бы выиграл.
Мне бы так контесты фейлить :)
Я решал I другим способом.
Предположим, что у каждого фильма есть вес и нам надо найти ответ наибольшего веса. Тогда если i-тому фильму присвоить вес 2n - i - 1, то мы сведем исходную задачу к этой.
Как решать задачу с взвешенными фильмами. Построим взвешенную сеть, где у каждого ребра пропускная способность равна 1. Каждому фильму поставим в соответствие две вершины: входную и выходную. Между входной и выходной вершинами одного фильма проведем ребро веса, равного весу фильма. Между выходной вершиной фильма i проведем ребра веса 0 ко входным вершинам всех фильмов, которые можно посмотреть после просмотра фильма i. Так же из истока добавим ребра веса 0 во все входные вершины, а из всех выходных — в сток.
Пропустим k единиц потока. Каждая единица потока — это один студент.
Так как 299 — это много, то пришлось писать на Java с BigInteger. Прошло с первой попытки.
пичаль((( у меня абсолютно то же самое не прошло(
Как решать F? OEIS подсказал только 21 число:(
Критерий того, что набор (A1, A2, ..., An) с A1 ≤ A2 ≤ ... An подходит это A1 + ... + Ak ≥ 3k(k - 1) / 2 для 1 ≤ k ≤ n, причем при k = n должно достигатся равенство. Необходимость очевидна, так как любые k команд разыгрывают между собой ровно 3k(k - 1) / 2 голов. В достаточность я поверил, и после того как увидел, что ее уже сдали, без сомнения закодил ДП, которое теперь уже без труда угадывается, но из-за дурацкого ML — 64MB пришлось сдать массив ответов в коде.
UPD. Исправил ≤ на ≥
При n = 3 возможен результат (0, 4, 5). Это не вписывается в предложенную схему, так как 0 + 4 > 3. То же самое с (1, 3, 5). Тут 1 > 0. Что я понимаю неверно?
должно быть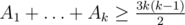
Есть идеи, почему этого достаточно?
Если коротко, то можно свести задачу проверки возможности данной таблицы результатов к поиску полного паросочетания в двудольном графе, а потом применить теорему Холла. Унылое доказательство в первой правке :)
Еще OEIS говорит:
FORMULA Nonnegative integer points (p_1, p_2, ..., p_n) in polytope p_0=p_{n+1}=0, 2p_i -(p_{i+1}+p_{i-1}) <= 3, p_i >= 0, i=1, ..., n.
по этому условию можно написать динамику
Как решать E и H?
Можно получить такое решение H. Если дискриминант меньше нуля, ответ 1. Иначе ответ:
sqrt(1 + 3 * b^2 / a^2 — 12 * c / a), округленный вверх. Е — самому интересно)
еще можно бинпоиск)
А откуда бинпоиск?
перебираем ответ задачи код
Тоже писал бинпоиском, но во время контеста не сдал изза тупой ошибки с приведением типов: ф-ия проверки дискриминанта:
А надо было:
А как такая формула получилась?
Составляем уравнение a * x^2 + b * x + c + ... + a * (x + k — 1) ^ 2 + b * (x + k — 1) + c = 0. Если у него нет корней, то дискриминант меньше 0. Из этого составляется квадратное неравенство на k. Получится (k — 1)^2 + 2 * (k — 1) + 12 * c / a — 3 * b^2 / a^2 > 0. Получим два случая — или ответ 1 (подставляя вместо k, получим условие на дискриминант), или ответ — больший корень уравнения, округленный вверх (это сама формула).
Сначала сворачиваем сумму f(x) + f(x + 1) + ... + f(x + k - 1). Получаем
Это квадратное уравнение на x. Так что считаем дискриминант. Он чудесным образом окаывается очень простым:
Откуда уже все и получаем. Не знаю как все делали, но у меня, чтобы не писать длинку, были какие-то извращения со знаковым и беззнаковым 64-битным целым типом.
А можно считать в даблах — для того, чтобы сравнить число с нулем, точности хватает.
А корень тоже как-то в целых числах вычисляли?
У меня зашло в даблах, но я не понимаю почему, ведь под корнем число порядка 10^18, а в мантиссе дабла всего 15 десятичных знаков (16-й как повезет), и кажется, что при преобразовании
unsigned long longвdoubleимеет место большая погрешность.Я обычно корень вот так вычисляю:
Вроде бы это не несет за собой проблем. Может красные подскажут, если проблемы все же есть.
У меня в E решение короче, чем в любой из остальных задач :)
Там ответ всегда да, причём номер кинозала для уранца с X руками можно найти только по числам n2, n3, n5, где X = 2^n2 * 3^n3 * 5^n5 * Y, (gcd(Y,30)=1).
а можно поподробней?
Не хочется раскрывать всю задачу. То есть код выглядит так:
Функции f2,f3,f4,f5 занимают не более 10-15 символов каждая. Например, f2(n2) = n2 % 2 + 1. Остальные могу раскрыть, если кому-то сильно надо. Но, мне кажется, интересней самому их найти.
Как долго займет процесс добавления задач в основной архив?
Добавили
Ну и ради интереса: как решать C кроме рандом шафла?
Перебор показывает, что для n=5 всегда можно выиграть. Поэтому просто перебираем все перестановки суффикса длины min(n,5), а префикс не трогаем (за первые max(n-5,0) шагов он съестся поэтому мы работаем только с суффиксом)
Зделал так как Вы написали, но ВА12 не знаю в чем может быть проблема.. может ктото может помочь? вот код:
http://pastebin.com/a0uDPHcj
UPD: Туплю должго быть:
var basic = new[] { arr[arr.Length - 5], arr[arr.Length - 4], arr[arr.Length - 3], arr[arr.Length - 2], arr[arr.Length - 1] };вместо:var basic = new[] { arr[arr.Length - 1], arr[arr.Length - 2], arr[arr.Length - 3], arr[arr.Length - 4], arr[arr.Length - 5] };Если у нас есть хотя бы 5 карт, то всегда можем выиграть. Теперь если карт много, то N-5 положим в том же порядке, что у противника, а остальные 5 — переберем все перестановки. Если карт меньше 5 — тоже втупую переберем все перестановки, но в этом случае мы можем и проиграть.
Как решать B? Пробовал переводить координаты в I координатную четверть, домножать их на 1000, брать по модулю 1000, потом искать точку, в которую отобразилось наибольшее количество установок, среди всех таких выбирать наиболее близкую к началу координат — WA 32.
Близость до начала координат меряется как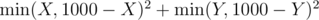 . То есть иногда ближе переехать в точку с отрицательной координатой. Возможно в этом ошибка.
. То есть иногда ближе переехать в точку с отрицательной координатой. Возможно в этом ошибка.
Это я тоже учёл. Вот код: http://pastebin.com/1YGxjeSU
Может проблема в точности? (int)(a * 1000) не всегда дает верный ответ.
А как тогда делать?
Перед приведением к инту прибавлять чуть-чуть, если положительно, отнимать чуть-чуть, если отрицательно. Или как-нибудь хитро сразу читать целочисленно.
Добавить EPS в случае когда a ≥ 0 и вычесть его в противном случае
Например, для чисел с тремя знаками после запятой можно (int)(a * 1000 + 0.5), если a неотрицательно, и (int)(a * 1000 — 0.5), если отрицательно.
Да, действительно, проблема была в этом. Спасибо!
А как предполагалось решать J? Я сдал все полностью в целых числах, используя некоторые дикие хаки с НОДом, чтоб избежать переполнения long long. В принципе, если б не ошибка в ДНК :), мог бы даже с плюса сдать.
Аккуратное моделирование в даблах заходит
Навсегда теперь запомню, как может отрезок пересекаться с треугольником.
Интересно, как работал чекер задачи С? Если простой эмуляцией игры, то возникает вопрос — могло ли быть так, что игра зацикливается или длится очень долго? Ну и вообще интересная задача — насколько долго игра может затянуться в принципе...
Я конечно тупой, но как решать А?
Например хешами.
А по-другому можно?
можно поддерживать баланс каждой буквы в дереве отрезков, и каждый раз смотреть если минимум и максимум балансов равен = 0, то ans++
Необязательно дерево отрезков, можно просто в каждый момент времени смотреть у скольки букв из алфавита количество совпадает с нужным.
а как это быстро находить?
Для первого отрезка посчитаем втупую, потом пересчитываем за O(1).
зачем! давайте заведем дерево отрезков!
храним длину найболшей подходящей подстроки, на каждом шагу меняем баланс(можно map в с++ или dictionary в с#):
если подходящих плохих символов после отбрасивания
book[i - worst.Length]в даной подстроке стает меньше чем нужно уменьшаем длину, если добавляяbook[i], он плохой, и таких меньше или ровно сколько нам нужно — увеличиваем длину. Если длина нашей подстроки равна длине плохого слова —count++.O (n * m) проходит за 0, 159 с :D