

Hi all!
This weekend, at Dec/23/2018 16:35 (Moscow time) we will hold Codeforces Round 528. It is based on problems of Technocup 2019 Elimination Round 4 that will be held at the same time.
Technocup is a major olympiad for Russian-speaking high-school students, so if you fall into this category, please register at Technocup 2019 website and take part in the Elimination Round.
Div. 1 and Div.2 editions are open and rated for everyone. Register and enjoy the contests!
The round was prepared by Roms, Neon, BledDest, adedalic, awoo, isaf27, Endagorion with coordinator's help from 300iq.
Have fun!







how many problems for each edition?
Still not announced fifteen minutes before the contest begins..
I'll do my best in the competition to get a higher Rating.
So what?
Cheers
What about the duration?
2:00 hrs
Does it include 12 hr open hacking phase?
nope
contest time good ^^
December Cook-Off :(
It's not overlapping at all. 25 minute difference between the two.
Didn't thank anyone in the announcement.
i hope your rating change will be equal to my contribution
number of problems ?
Scoring distribution ?
You will see them when the contest starts. Good luck!
The difficulty of Problem E and F (div.2) seems quite high.
When you have an exam tomorrow and you don't give a damn :p
A/C — think 1 minute, implement 1 hour B — just guess and it works
:/
What's the guess ?
I guessed it only useful to put weights on leaves, and so the answer is 2*s/#leaves, no idea why it's correct though
EDIT: previous didn't work, I'll try again.
EDIT 2: Here's a fixed version of the first one, thanks tfg
Take an optimal solution, with diameter d. Then take any non-leaf-edge with nonzero weight w. Then find the side of it with lesser depth. Let the depth of the deeper side be p. Now you can move the weight of this edge to any leaf edge in the less deep subtree.
Let s be the weight of any path in the less deep subtree. Therefore d ≥ s / 2 + w + p ≥ s + w, and therefore the new weight s + w of the path is still ≤ d. Therefore moving the weight doesn't cause problems. Here we used s / 2 ≤ p, since we moved the weight to the less deep subtree, and the depth of the less deep subtree is at least s / 2.
That proof is almost correct, just change "subtree" to "direction opposite to the center of the tree" and it's correct.
still unable to understand the intution behind 2*S / # of leaves Diameter -path between leaves that are longest apart from root
From question i understood here
diameter refers to length of path between leaves that are farthest apart from each other but why we multiply by 2 and divide by of leaves
Because you divide S for the leaves, so each leaf has S / # of leaves cost and then you add 2 leaves together to get the diameter.
Let me try another proof, which is in quite different manner:
First, we try to minimize sum of length of all n * (n - 1) / 2 simple path. This can be done by placing all weights on leaf-connected edges: any weight w placed on a leaf-connecting edge would increase length of exactly n - 1 paths, by w. No other choice offer lesser affected path. Notice that this would not increase the shortest possible diameter(=longest simple path).
After such "restriction", the longest simple path length is "sum(length of two longest leaf-connected edges)". To minimize it, we place weights evenly on leaf-connected edges, and we are done.
Put weights equally on the edges such that one of its endpoints is a leaf node. 0 for the rest.
It took me more time to think than to code in A. You can just connect all points to the point (mid-x, mid-y) any way you want (with minimum manhattan distance), where mid-x is the middle one of their x-coordinates, and mid-y is the middle one of their y-coordinates. 47401109
Totally agree on C though, what a horrible problem. Also, I feel so dumb for initially trying to find a DP solution to B :P
C also makes me very scared of the systests :O
Is C joining any two points by Manhattan distance and then doing case work for the third point. Any easy implementation?
I haven't submitted it yet since i'm out of contest, but what i thought of was finding some point D that has minimum (manhattan) dist(A,D) + dist(B,D) + dist(C,D), and then rebuild the paths by starting from D.
That will be O((1e5)^2).
The statement says coordinates are 0 <= x, y <= 1000 = 1e3
Yes. Thank you!!
1e3, not 1e5.
Yes! That's an AC
I implemented it by drawing a horizontal line at the coordinate of the point with the median y-coordinate (from the min x to max x). Then, for each point, draw from that line up or down to the coordinate.
You are given with three points, A,B and C . just align them in increasing X-coordinate form by sorting the pair of points. Take a set ANS. Let A be the leftmost point, B the middle one and C be the rightmost one. Now traverse from A to B first in horizontal direction and then in vertical direction while adding the coordinates to set ANS. After this move from point C to B similarly and add the coordinate in set ANS. Duplicate elements would be added once as we are using a set. set ANS is your solution.
Code: https://codeforces.net/contest/1087/submission/47447385
how to solve div2 C ?
If x of all points are same, then draw a horizontal line.
If y of all points are same, then draw a vertical line.
Otherwise,
Find the point whose y is medium among the y of all points. Let it be point M. Then Draw a horizontal line through M.y. Now if any point is upper than that horizontal line, then draw a vertical line from the horizontal line upto to this point. if any point is lower than that horizontal line, then draw a vertical line from the horizontal line down to to this point.
Hi..I bruteforced..:) and it works. i just found one point (x,y) ,which the absoulte difference abs(x-A.x)+abs(y-A.y)+abs(x-B.x)+abs(y-B.y)+abs(x-C.x)+abs(y-C.y) minimum; -Then just made any route from A,B,C to (x,y),seperately;
First, create a Point structure and sort the 3 points by x component. Then, let's name A, B and C the leftmost, the middle and the rightmost elements, respectively. After that, find the minimum and maximum y components of them. Using a boolean array plot[1001][1001], check all the elements from minY to maxY with the middle point x component, which is B. To connect A and C to the vertical line that passes through B, check all elements from A.x to B.x that have A.y component. Repeat that with B and C but using C.y. Finally, iterate over plot[][] counting the number of elements that are checked and print them.
How to solve E?
Traverse through the string s. We will jump on a few cases:
I> If
a[i] == b[i]:s[i]was mapped as exactlya[i], ignore this position and continue.s[i]was not mapped anda[i]was not used in mapping, maps[i]asa[i].NOand terminate.II> Otherwise:
IIa> If
s[i]was mapped:s[i]was mapped outside of the bounds [ai, bi], outputNOand terminate.s[i]was mapped inside of the bounds (ai, bi), the template will already be correct regardless of how the remaining characters are being mapped.IIb> If
s[i]was not mapped:s[i](being inside of the bounds [ai, bi], and not being used to map any other characters).NOand terminate.Regardless of the results, as long as the program wasn't terminated, we'll temporarily stop the traverse if jumping into this case.
III> Cases with s sticking to either a or b:
We will jump into this case when during the last traverse, ai ≠ bi and si was mapped to either ai or bi. From here, you can continue solving like above, only with one difference:
If the program wasn't terminated yet after finishing all these scenarios, search for any unmapped characters and map them (in case there are some), and output the template, finishing the problem.
P/s: I can't believe I could map all these things in my head in 30 last minutes. Yet, still failed pretest for some idiotic mistake hidden beneath the messy code. Heck, the problem is a complete bane.
Div2 E = Div1 C
Find the lexicographically smallest string that is larger than or equal to a and check whether it is smaller than or equal to b.
To do so, write a helper function that checks whether any string exists such that it is larger than or equal to a and conforms to a pattern of letters and jokers. At each step you have a partly determined permutation that corresponds to a partly filled in string
sand you want to choose what the leftmost joker will turn to. Example: let's solve it fors=bbcb,a=aadaas in the sample test. Does a string exist for????? Yes, just greedily fill in the jokers with the highest available symbol:ddcd >= aada. Does the string exist foraa?a? Again, yes,aada >= aada. It means that the first joker will turn into the letteraand we will have to fill in the patternaa?a. There,aabaandaacawill fail butaadawill fit. And we know that something will eventually fit because otherwise we would go forbb?bor even something larger.Time complexity is O(n·k2).
Code: https://codeforces.net/contest/1086/submission/47418603
Can you prove why this is working, in canExtend(), you are filling the '?' with highest possible alphabet you can fill it with, and checking if its >= a .. Why are we filling the '?' with highest available alphabets?!
I cannot completely understand the intuition, If you can elaborate in any way that would be helpful, I just want a general idea as to why you are doing that!
There is a general approach to the problems of finding lexicographically smallest constructions of a known length. Firstly, check whether you can find any solution at all. If you can, build the lexicographically smallest one letter by letter. If you can find any solution that starts with the smallest letter, then the lexmin solution also must start with the smallest letter by definition (or the one you've found would be smaller).
Thus all you need is a function that tells you whether you can complete a partial solution to a full one (omitting the lexmin condition) and then you can incrementally build the lexmin solution from the empty one with the help of this function.
In this problem, to find any string that is larger than the goal string a (without the lexmin condition) I use a simple greedy that assigns the leftmost unassigned letter to the highest possible value.
Thanks a lot for your help, this solution is the most elegant one out there , least amount of casework!
Why is time O(nk) and not O(nk^2)?
It should be O(nk^2) but the break because of building the answer greedily significantly improves runtime. My solution runs in 1528ms : https://codeforces.net/contest/1086/submission/47450262
You are right, it is O(n·k2). Fixed, thank you.
How to find the lexicographically smallest string that is larger than or equal to a:
You can do binary search for the length of the matching prefix after applying the template . Check for fixed length can be done in O(n * k).
After that you can just check that our string less or equal b.
Time complexity is O(n * k * log(n)).
Code: 47481574
How to solve Div2 B
The (X MOD K) part of the formula is between 1 and K-1. So for each of these possibles values you need to calculate the minimum X for the formula to be true. Turns out the original formula can be written as ((X-X%K)/K)*(X%K) = N, making the first term the smallest X possible. Given that you'll set the (X%K) part, you can say:
R = (X%K)
X = (N/R)*K — R
So for every possible R you find X and check. Complexity O(K)
My solution is kinda bruteforce. for (int i=1; i<=sqrt(n);i++) { if (n%i==0) { if (i<x && ((n/i)*x+i)<min)min=(n/i)*x+i); if (n/i<x && (i*x+n/i)<min)min=(i*x+n/i); } } cout<<min;
Complexity sqrt(n)
You want to find the minimal possible value. Note that increasing the first term (X/K) by 1 will cost K, and you can change X%K to any value for a cost less than K, so we want to minimize the X/K term and thus, maximize the X%K term. Both terms should be divisors of N, and X%K can be any number less than K, so we must set it to be the largest divisor of N less than K. To do this we can just check, for each number from K-1 to 1, if it divides N. Once this is found, we can find the solution easily.
https://codeforces.net/contest/1087/submission/47431845
Complexity is O(K)
Nice solution. Learned a thing from you :)
Hello, Can someone explain Mathematically what is the problem with the below solution :
The solution fails on Test Case 5. Herein I have modified the equation by multiplying k to both sides, as a result I am checking if(n*k%"possible mod values starting from k-1") rather than checking if(n%"possible mod values"). I got Accepted solution when I am keeping the original equation and just checking n%mods but not with this code.
ans=Math.min(ans,(p/i)+i);You forgot to multiply k. It should be
ans=Math.min(ans,(p/i)*k+i);.I have stated that I already multiplied k to both sides of equation beforehand. If you see in (p/i) my p = n*k
Ah, I saw it. My apology.
Still, that very act made your answer wrong. There might be some prime numbers which divides k but doesn't divide n, thus you might actually count those primes into account and get an answer lower than the expected one.
Thanks for replying.
How to solve div1 c?
Does E require Bigints?
What is pretest 2 for div1C??
I've learned new life lesson :
don't participate in codeforces round after an exam so you don't lose 100 rate
When will the editorial be published?
Is there something wrong with my implementation of B:
From your code, it is not guaranteed that both c and d can be result of modulo operation. (0 ≤ c, d < k) Think of the case when n is larger than k2. Then, c ≥ k.
DIV. 2 first 4 problems are really good, short code and nice idea, but the last 2 problems are much more harder, most of the users finished in the first hour and kept waiting for the contest to end :(
That's right. I've been through the same thing.
Problem setter of div1C should stop writing problems.
I don't know the meaning for such a boring problem with lots of cases to handle. It's too much harder on coding than thinking.
I was solving it for more than ~1 hour and 10 minutes. After 1 hour I finally managed to get correct answers but received TLE which I didn't know how to fix ( ͡° ͜ʖ ͡°) So, my inability to code such simple problem is one thing, but even when not taking this into account, this is still a terrible problem.
The main idea of the problem is to skip it as soon as possible.
I agree. It seems that a lot of people do not have sufficient time finishing C,D,E (including me).
It's such a boring problem that the most difficult part of the problem is even coding. I don't know what's the problem settet doing
I'd guess the authors had no problem to place as 1C (possibly because the problem that was meant to be there turned out to be a copy of some existing problem), and so they were desperate enough to insert this one instead.
Is it possible that you say so because you have missed a simpler solution? Please read https://codeforces.net/blog/entry/64006?#comment-478340
The problem is on the more standard side, that's true, but I did not find anything especially hard neither in the solution nor in the implementation. There are no special cases, it is just a straightforward "find the lexicographically minimal something" exercise.
It seems my implementation is a little more complex. But I still don't like this problem because it's just a implement problem and lacks of interesting ideas.
Did anyone solve D without Ordered sets. Or did author not know about ordered sets
47417705 Overkill:
Segment tree with
cnt[type][left_mask][right_mask],maskstands for losing and winning move.If my reduction is correct, the amount of winning rocks is just
total amount of rocks — amount of rocks in interval (leftmost paper, leftmost scissors) — amount of rocks in interval (rightmost scissors, rightmost paper)
You can store amount of rocks in interval in a segment tree, and get leftmost paper and scissors from normal sets. Using ordered sets might be easier though.
You can use BIT. With BIT, you can find the first index x with pre(x)>=some number in O(logN). I didn't do this tho.
It's not like using ordered sets instead of most basic interval/Fenwick tree makes this problem trivial.
Nice contest clean description although problem C (div.1) was a little more coding than actually solving:)
Please, anybody know why my code took TLE in problem "Connect Three"? my code. It is linear.
Super fast system testing ! Thanks a lot.
C is stupid implementation problem that took me 1:30 to do and I didn't have time for D which was easy. shitty trashforces contest
There is a better solution. You just need to find a point which minimizes the sum of Manhattan distances from all the points.
It was my 200'th rated contest on codeforces!
I am happy that I could solve the problems A to D, which were solvable for me. I hoped so that I had no contrition for any of my mistake in my 200'th rated contest. And I am happy that my hope became true :)
I hate Div1C/Div2E. Don't ask why.
BTW, SUPERFAST systemtesting!! Thanks
Why we're counting leaves and dividing 2*s by #leaves in div2D?
Define a maximal path as a path that can't be extended any further (equivalently, a path from a leaf to another leaf)
Observation 1: It is always best to put edge weights on leaf-edges. If you put an edge weight in a middle segment of the graph, there will exist a leaf such that any maximal path through that middle segment will also go to that leaf, as well as potentially other paths. So all weights must be assigned to leaf-edges.
Observation 2: All maximal paths will go through exactly 2 leaf-edges (if the graph has more than 2 nodes). Hence, the optimal strategy is to minimize the 2 greatest leaf-edges, which can be done by setting all leaf-edges to the same value. Then, the weight of any path is the sum of the two maximal edges: s/leaves+s/leaves = 2s/leaves. In the case where the graph has 2 nodes, just return s
Got it. Thanks :)
Can someone plz explain Div2 D? I had a head ache after thinking for an hour
You should equalize all diameters (because decreasing one diameter necessarily means increasing another one to maintain the given sum). Each possible diameter contains two leaf nodes. Therefore, all leaf edges should have the same weight so that the maximum diameter is minimized. We can ignore non-leaf edges and set them to 0. Thus, the answer is 2 * (sum / # of leaf nodes).
I don't know how real proofs work, maybe someone else can give a more formal answer.
(That's how I solved the problem.)
Second figure in the problem D was a good hint for solving the problem.
Don't understand why the A and B seems too hard to me at the contest time!
For Div1 F, does something like this work.
Given distance is chebyshev distance convert it to manhattan distance. And now if we take two points x and y and see locus of points closer to x.the locus will be half plane. So now we can divide whole space in n*n regions formed by intersection of half planes. And each region all points are closer to only one point. So we can compute one that region using some math. And add all. Is this correct or what is your solution?
Do you mean taking the voronoi diagram under manhattan distance? The division isn't a simple half plane and these regions aren't convex.
I tried to understand this solution https://codeforces.net/contest/1086/submission/47429292 and here's what I got:
f(i) = squares covered at time i, g(i) = f(i) — f(i-1) = squares covered at exactly time i. g(i) is actually a piecewise linear function with decreasing slope. You can use binary search to find the events where the slope changed and do some math with faulhaber's formulas to calculate i * g(i). In code, f(i) is getNumCovered(i). You might note that an event of changing slope is actually an event where 2 boundaries merge in the chebyshev distance voronoi diagram, so there will be O(N) such events. Edit: other way to see that it has O(N) events is because the slope starts at <= 4 * N
Actually, the number of events of changing slope is O(N2) because, for example, if the boundary of point x has already merged with point y, and the boundary of point y has already merged with point z, we still have to process the merging of boundaries of x and z because this will affect the function.
But the main idea is similar to model solution: find segments where the function f(t) behaves as a polynomial, and either do some pen and paper work to find the coefficients of this polynomial, or interpolate it. Well, the main difference is that model solution doesn't use Voronoi diagram at all.
The solution I described doesn't use the voronoi diagram at all, it does what you said. The diagram is just me trying to explain how it works.
The voronoi diagram is there to prove that the number of events is O(N) since the events are actually creation of edges and vertices in the voronoi diagram. Connect the infinite edges to a new vertex. An event is either a vertex event or edge event in the voronoi diagram. This is a bit different to the usual voronoi diagram because there might be vertices with degree 2. These vertices are created when 2 boundaries meet and the edges of this 2 or 3 edge chain only end when 3 boundaries meet or don't end at all. We can compress these vertices with degree 2 and we find that the number of vertices and edges are O(N) in the same way as the usual voronoi diagram ((V + 1) — E + N = 2 and 2 * E >= 3 * (V + 1)). Since compressing removes at most 2 vertices per 3 edges, the actual number of vertices is a bit higher but it's still O(N). In the usual voronoi diagram V + E <= 5 * N — 11 and here it should be something like <= 9 * N — something. Even better, these vertices of degree 2 are actually created at the same time so they work as 1 event. https://codeforces.net/contest/1086/submission/47456422 this solution also passes with assert(events <= 7 * N). Where's this wrong?
Okay, it seems that I misunderstood you about the usage of Voronoi diagram.
By the way, what's the complexity of your solution? It seems to have better asymptotic than the model solution (which is O(n4)), but still consumes the same 0.5 seconds.
If I understood correctly mnbvmar's solution, GetNumCovered works in O(N^2) and it's called O(N * logT) times (there are O(N) events and the next is found using binary search) so O(N^3 * logT). Since logT is quite big and N is small it makes sense to take the same time as O(N^4) solution. Edit: I'm also pretty sure that GetNumCovered can be modified to O(N * sqrt(N*logN)) (maybe even without that log) using some kind of sqrt decomposition to solve range addition over b[i] and sum of a[i] for positions with b[i] > 0 but that doesn't make a difference for this problem since N is too small.
I realized after the contest that the binary search thing actually doesn't work (I assumed that the function
gyou defined above is concave but sometimes it isn't). It is quite hard to fail this solution, though. Nevertheless, I'm still very happy my code passed the systests. :)BTW I think GetNumCovered can be implemented in time; computing the area covered by the union of rectangles is a well-known problem. I just realized that the implementation will take waaay too much time for me, and the "quicker" algorithm probably won't be much faster for N ≤ 50.
time; computing the area covered by the union of rectangles is a well-known problem. I just realized that the implementation will take waaay too much time for me, and the "quicker" algorithm probably won't be much faster for N ≤ 50.
Yes. My bad. The division isn't a half plane. But I have another idea. Divide the entire grid n*n rectangles. In each rectangle now in Manhattan distance modulus can be removed appropriately. So in each rectangle we have to solve something like for all points in it. We have to take of min of x+y+c and x-y+d and other two signs similarly. c and d will be fixed appropriately. And if that min is less than t we add it. This seems solvable in constant time for a rectangle with some math, but currently not clear how to solve it.
Does this seem any good?
How was your arpoach for Div2B?, A brute force up to 10^8 checking if (I/K)x(I%K)==N didn't worked and I'm pretty newbie in the math stuff :/
You only need to bruteforce all possible modulos and generate minimum possible answer for each. My solution runs in O(k).
Something is wrong with problem difficulties tags. It shows Div 1 D = 2700 and Div 1 E = 2600...
Can we have the editorials?
When will the editorial be published?
Solution of Div2 D was all about finding number of leaves and use formula 2*(sum/leaves). Can anyone provide a proof?
Note that any diameter will have two leaves as ends. Consider a tree full of 0-weight edges. Since the diameter the problem considers will be the worst possible, first observation is that we must distribute the weight equally among all leaves. Second observation is that, if you put some weight into some non-leaf edge, the only thing you're doing is increasing the chance of that there is an even worse diameter.
The solution comes from these two observations, you must distribute the given S among all leaves, that is sum/leaves. Any diameter will have two leaves as ends, so the worst diameter possible will be 2 * (weight of leaves) = 2 * (sum / leaves)
How can I hold a CF Round?Sorry for my inopportune:)
How to solve div1E ?
I'm surprised nobody mentioned this yet, but here's a double counting proof-without-words for DIV 2D/DIV 1B:
Let the minimal possible diameter be D and number of roots be R. The bound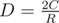 is obtained by putting an weight of
is obtained by putting an weight of 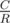 in each of the root-edges.
in each of the root-edges.
To show this is the optimal, imagine the tree as wall and put an ant on the surface of the wall and let it go. Partition the ant's path when it meets a root, something like this
By the definition of D, the sum of edge-cost in each of the green segments is atmax D and it's easy to see by construction there are total R green segments.
A standard double counting gives total sum of cost in each green segment is exactly 2C (since each edge is counted twice). So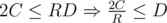 , and we're done.
, and we're done.
nice proof, but the other 'normal' way looks more intuitive to me, I cannot image myself ever thinking about edges as walls, so to me it looks like this is a general technique that comes up in math competitions and that's where you get the idea from,
Can you give me some sources to learn about more applications of these, some examples, very cool way to solve this problem though!
Thank you! To me that's a much better proof.
who is namo_superstar ...
Ham aapke mannaniya pradhan mantri "NaMo The Great" hai. Hamare baare me aur janne ke liye play store se Namo app download kare. Apna vote kamal ko hi de. Jai Hind !
so NaMo is a great coder too ...waoh ...
It seems to me that "E. Vasya and Templates" is not very friendly to slow languages like Java. During practice I submitted a solution that timed out on test #13, when I had a look at the test, it turned out all the strings were length 1, and potentially the program had to output up to 26 million characters.
So even if the overall running time of the algorithm is ok, but there are a number of constant-time calculations (repeated 1 million times since there are 1 million test cases) the program fails.
I looked at the people who solved the problem in the Div. 2 contest, not one submission was in Java — as far as I saw, all of them were in C++ — a fast language when it comes to input/output.
Has any one solved E in Java or is it impossible?
My code: https://codeforces.net/contest/1085/submission/47463189
If you check the status in the Div. 1 version of the contest, you'll find some Java solutions to it
It's just you required better output methods than just standard System.out.
You can see this Quora question for an example of fast I/O in Java.
Please release the editorial.
The Rating of (Div.2) 'Prob D. Minimum Diameter Tree' is 1700, and the rating of 'Prob E. Vasya and Templates' is 2500; the gap is large.
How to solve div2 F/ div1 D?
Problem C Test Case :
0 0
1 2
2 1
I think , the ans should be
5
0 0
1 0
1 1
1 2
2 1
And this ans was accepted by jury at contest time. but now jury give ans:
6
0 0
1 0
1 2
2 0
2 1
2 2
Please explain me, what is going on?
I think you swapped your answer and jury answer.
Where is editorial?
Link to editorial https://codeforces.net/blog/entry/64078
KAN please put a link to the editorial in the post. I would not have known that the editorial has been published if I wouldn't have looked at the comment just above mine.