


Hello denizens of Codeforces once again!
After our last two rounds, Yang Liu (desert97) and I (ksun48) are pleased to announce Codeforces Round #492, which will happen on June 24, 2018 at 19:35 MSK. There will be two versions of the contest, one for users in Division 1 and one for users in Division 2. Both versions will have six problems, with four problems shared between the versions.
The round will feature our friend and superstar member of ACM-ICPC team MIT TWO, Allen Liu (cliu568).
The scoring distribution will be visible once the contest begins. As usual, we'd like to thank our wonderful problem coordinator KAN and Codeforces administrator MikeMirzayanov, as well as the rest of the Codeforces staff for keeping this site an amazing place for competitive programming. Thanks also to our testy testers winger, AlexFetisov, and demon1999.
This round is in honor of uDebug who have supported Codeforces on its anniversary. Thank you, uDebug! uDebug is an enthusiastic community of competitive programmers who help each other out by answering questions on chat, providing hints and solutions to problems from several online judges, furnishing test input and sharing feedback. On uDebug, you can select a problem you’ve coded up a solution for, provide input, and get the "accepted" output. You can visit it by the link.
Good luck! As always, we encourage competitors to read all the problems.
(̶a̶l̶s̶o̶,̶ ̶I̶ ̶s̶e̶e̶m̶ ̶t̶o̶ ̶h̶a̶v̶e̶ ̶h̶e̶a̶r̶d̶ ̶s̶o̶m̶e̶ ̶r̶u̶m̶o̶r̶s̶ ̶f̶l̶o̶a̶t̶i̶n̶g̶ ̶a̶r̶o̶u̶n̶d̶ ̶a̶b̶o̶u̶t̶ ̶a̶ ̶s̶p̶e̶c̶i̶a̶l̶ ̶ ̶s̶u̶r̶p̶r̶i̶s̶e̶ ̶w̶h̶i̶c̶h̶ ̶m̶i̶g̶h̶t̶ ̶b̶e̶ ̶h̶a̶p̶p̶e̶n̶i̶n̶g̶ ̶d̶u̶r̶i̶n̶g̶ ̶s̶y̶s̶t̶e̶m̶ ̶t̶e̶s̶t̶i̶n̶g̶,̶ ̶s̶o̶ ̶k̶e̶e̶p̶ ̶y̶o̶u̶r̶ ̶e̶y̶e̶s̶ ̶p̶e̶e̶l̶e̶d̶!̶)̶
EDIT: And the rumors are confirmed! Go to http://codeforces.net/blog/entry/60176 after the contest is over to discuss the problems or voice your complaints along with scott_wu and ecnerwala!
EDIT: Due to some last minute changes, each version will have six problems, with four shared problems.
EDIT: The Div. 2 score distribution is 500-1000-1500-1750-2500-2750 and the Div. 1 score distribution is 500-750-1500-1750-2250-2500.
EDIT: Congratulations to the winners of the round!
Div. 1:
Div. 2:
Thanks to everyone for participating! The editorial is available at http://codeforces.net/blog/entry/60217.





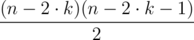 pairs of cows which are ordered correctly.
pairs of cows which are ordered correctly.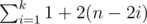 .
.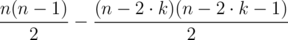 total pairs
total pairs  .
. .
.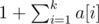 —we can have the single letter
—we can have the single letter 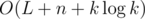 . Of course, we can also find the least recently used letter with less efficient approaches, obtaining solutions with complexity
. Of course, we can also find the least recently used letter with less efficient approaches, obtaining solutions with complexity 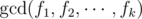 for each choice of
for each choice of 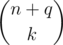 choices of
choices of 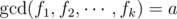 occurs in the sum (let this be
occurs in the sum (let this be 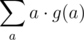 overall all
overall all 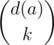
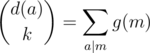 , the number of gcds which are a multiple of
, the number of gcds which are a multiple of 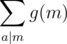 . We’ll take an example, when
. We’ll take an example, when 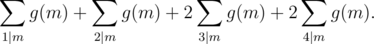
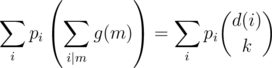 . Equating coefficients of
. Equating coefficients of 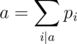 . (The mathematically versed reader will note that
. (The mathematically versed reader will note that 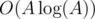 using a recursive formula:
using a recursive formula: 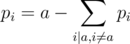 . We can also precalculate
. We can also precalculate 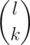 for each
for each 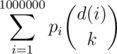 after each query we should keep track of the values of the function
after each query we should keep track of the values of the function 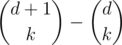 . If we precompute the list of divisors of every integer using a sieve or sqrt checking, each update requires
. If we precompute the list of divisors of every integer using a sieve or sqrt checking, each update requires 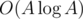 or
or 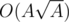 preprocessing, and
preprocessing, and  be the line passing through
be the line passing through 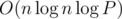 , where
, where 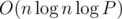 , where
, where 
