


After getting rank 15 in Codeforces Round 844 (Div. 1 + Div. 2, based on VK Cup 2022 - Elimination Round), arvindf232 has reached Legendary Grandmaster rank with rating 3027. Congratulations!
→ Pay attention
→ Streams
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3857 |
| 2 | jiangly | 3747 |
| 3 | orzdevinwang | 3706 |
| 4 | jqdai0815 | 3682 |
| 5 | ksun48 | 3591 |
| 6 | gamegame | 3477 |
| 7 | Benq | 3468 |
| 8 | Radewoosh | 3463 |
| 9 | ecnerwala | 3451 |
| 10 | heuristica | 3431 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 165 |
| 2 | -is-this-fft- | 161 |
| 3 | Qingyu | 160 |
| 4 | Dominater069 | 158 |
| 5 | atcoder_official | 157 |
| 6 | adamant | 155 |
| 7 | Um_nik | 151 |
| 8 | djm03178 | 150 |
| 8 | luogu_official | 150 |
| 10 | awoo | 148 |
→ Find user
→ Recent actions






As we all know, Codeforces has a feature that allows users to hide problem tags for unsolved problems. However, when I create a mashup contest, it shows the tags even for unsolved problems.
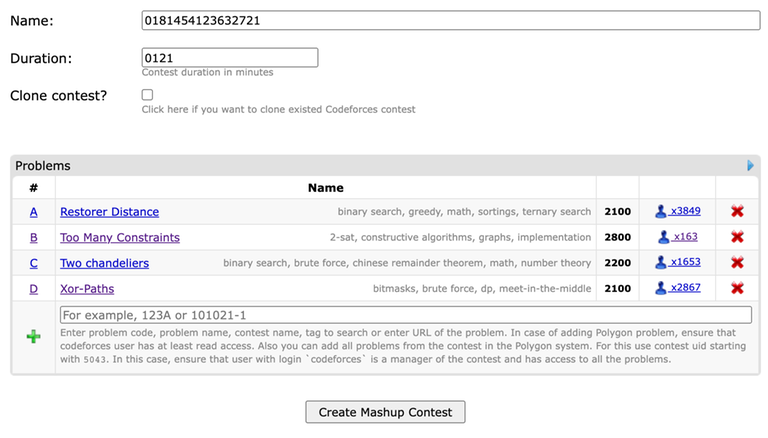
It is a very minor issue, but it would be better if the "hide tags for unsolved problems" also includes hiding tags when adding problems to mashup contests. Just imagine being spoiled by the "ternary search", "2-sat", "meet-in-the-middle" tags right away before reading the problems.
Hello, Codeforces!
I am happy to invite you to Codeforces Round 761 (Div. 2), which will take place on Dec/16/2021 16:35 (Moscow time). The round will be rated for participants with rating lower than 2100. Notice the unusual starting time.
All the problems were authored and prepared by me. The round wouldn’t be possible without these people:
- Artyom123 for excellent coordination and translation of statements.
- KAN for help with round preparation.
- arvindf232, physics0523, SecondThread, Igorbunov, kevinxiehk, generic_placeholder_name, Kotehok3, minhcool, anthony123, Elison, shishyando, SlavicG, Absyarka, erniepsycholone, dbsbs, lomienyeet for testing and valuable feedback.
- Again, arvindf232 and generic_placeholder_name for providing solutions to a problem that are better than the author’s solution.
- Again, kevinxiehk for submitting many different solutions to a problem.
- MikeMirzayanov for great Codeforces and Polygon platforms.
- You, for participating!
You will have 2 hours to solve 5 problems, one of which is divided into two subtasks. One of the problems is interactive, please see the guide of interactive problems if you are not familiar with it.
Wish you good luck and high ratings!
Here is the score distribution: $$$750-1000-1500-(2000-1000)-3000$$$.
The editorial is here: click.
UPD: Sorry but there is a checker bug in problem E. All submissions of problem E will be rejudged soon.
UPD2: Rejudge done, the round remains rated.
Congratulations to the winners (will be updated after system tests):
Congrats!
Thanks for participating, hope you enjoyed the problems! Implementations for the problems are chosen randomly among testers, and I made some changes to their codes (for example, deleted meaningless comment lines). Please do not hesitate to provide feedback in the comments, so I can improve in setting problems next time.
UPD: Sorry but there is a checker bug in problem E. All submissions of problem E will be rejudged soon.
UPD2: Rejudge done, the round remains rated.
Statistics
1617A - Запрещённая подпоследовательность
Hint
Solution
Implementation (C++, I_Love_YrNameCouldBeHere)
Fun fact
Hint
Solution
Implementation (Solution 1, Java, SecondThread)
Implementation (Solution 2, C++, dbsic211)
Implementation (Solution 3, C++, anthony123)
1617C - Паприка и перестановка
Hint 1
Hint 2
Solution
Implementation (C++, physics0523)
1617D1 - Слишком много предателей (простая версия)
Hint 1
Hint 2
Hint 3
Solution
Implementation (C++, dbsic211)
1617D2 - Слишком много предателей (сложная версия)
Thanks must be given to arvindf232 and generic_placeholder_name for the solution.
Hint 1
Hint 2
Solution (Step 1)
Hint 3
Hint 4
Solution (Step 2)
Implementation (C++, dbsic211)
Hint 1
Hint 2
Hint 3
Solution (Step 1)
Hint 4
Solution (Step 2)
Implementation (C++, physics0523)
In some recent CF problems such as 1503B - 3-Coloring, it was mentioned that the interactor is adaptive. Are there any general methods to write adaptive interactors, or does it depend on the problem? Can anyone who has experience writing adaptive interactors share some of your thoughts? Thanks!
Recently, my friends and I wrote a mashup contest. We gave the link to others to register, however I encountered two problems.
Firstly, registration is only open within six hours of contest time. So, when a user gets invited to a mashup, they are not able to register until six hours before contest starts. 
Is there any way to set a custom registration time (e.g. 3 days before the contest)? If there isn't, I think this would be a cool feature to add to mashup contests.
Secondly, after a user is successfully registered, they would receive the pop-up "You have been successfully registered", and they would get redirected to this page. This means that they have to paste the contest link / invitation link again in order to view the contest page (in the format of https://codeforces.net/contests/[6-digit number]). This can be confusing and inconvenient to mashup participants, especially those who encountered this problem the first time. Perhaps they can stay on the page instead of being redirected?
This is not my first time writing a mashup contest (and encountering these problems); I have written a few before.
I have seen this blog talking about a similar issue. However, the registration time problem hasn't been solved, so I would like to hear from your thoughts.
Hello!
I would like to conduct a survey about competitive programming in general, including when you started, how you practice and more.
There are ten questions, and it should not take more than three minutes to finish it. You can click this link to complete the survey.
Thanks for helping!
Update 1: One of the questions, "How confident are you on being a red coder?" now allows decimals (from 1.0 to 5.0) as responses! Also you can submit more than once now.
Update 2: A new question is added: "Which category do you belong to on Codeforces?" (sorry for not adding it previously)
Update 3: The survey will be accepting responses until Thursday, October 22, 2020 at 00:55 (UTC). Results will be out in a few days.
Update 4: The survey is no longer accepting responses. Thank you CF community for helping me fill in the survey! By the way, there are a total of 793 responses.
Update 5: Results are out!
Q1: What is your current age? (Responses: 793)
0-9 (1.1%)
10-19 (42.2%)
20-29 (54.2%)
30-39 (1.1%)
40-49 (0.4%)
50-59 (0.0%)
60 or above (0.9%)
Q2: At what age did you start CP? (Responses: 793)
Most popular responses are from around 12 to 21 years old, in particular 21.8% of the respondents started at age 18, and 20.4% of the respondents started at age 19.
Q3: Which category do you belong to on Codeforces? (Responses: 661)
Newbie or Pupil: 29.3%
Specialist: 17.5%
Expert: 24.4%
Candidate Master: 11%
Master or above: 11.5%
Grandmaster or above: 6.2%
Q4: Which programming language do you use mainly? (Responses: 793)
Most popular responses are C++, Python and Java. 89.8% of the respondents chose C++, 4% and 3.8% chose Python and Java respectively.
Q5: How much time do you spend on CP per week? (Responses: 793)
<1 hour: 4.3%
1-2 hours: 6.8%
3-5 hours: 18.7%
6-10 hours: 26.7%
11-20 hours: 22.8%
21-30 hours: 10.8%
31-40 hours: 4.7%
More than 40 hours: 5.2%
Q6: How do you learn algorithms or data structures in general? (Responses: 793)
Online judges: 60.9%
Books: 40.2%
Tutorial sites: 59%
Reading editorials of problems: 22.1% (I added this at a later time so the actual percentage may be larger)
Other popular responses: YouTube, CF blogs, College courses, CP algorithms, Mentors, Friends, Codeforces EDU
Q7: Which online judges / contest sites / coding platforms do you use? (Responses: 793)
Codeforces: 97%
AtCoder: 62.5%
CodeChef: 56.9%
LeetCode: 27.4%
HackerRank: 24.1%
HackerEarth: 20.3%
UVa: 12.1%
TopCoder: 6.9%
CodinGame: 3%
Other popular responses: USACO, Local judges, CSES, SPOJ, LightOJ, oj.uz, CS Academy, DMOJ, Timus
Q8: What is your attitude towards getting top 100 in a Codeforces Round? (Responses: 792)
My hard work paid off: 53.4%
Oh I just got lucky: 43.7%
I'm so pro: 6.6%
I always get top 100, so it's nothing special to me: 3.3%
Q9: How confident are you on being a red coder/LGM? (Responses: 793)
Most popular responses: around 3.8 to 5
Least popular responses: 1
Q10: If you are a student, is schoolwork or CP more important? (Responses: 703)
1 — Schoolwork is more important
5 — CP is more important
1: 5%
2: 8.4%
3: 18.3%
4: 31.3%
5: 37%
I have found out that two contestants of the round aditi_gupta07 and aviban99 had almost identical codes. Here are their submissions:
Problem A: (89928617, 89935523)
Problem B: (89944498, 89950768)
MikeMirzayanov please look into this incident and take necessary actions against them.
Codeforces (c) Copyright 2010-2025 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Mar/04/2025 13:36:22 (l1).
Desktop version, switch to mobile version.
Supported by
