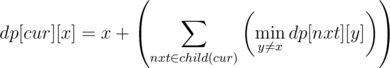Hi guys,
Just a quick question, as I am quite puzzled about the verdict difference.
Those two codes are identical, but it passes in G++17 and fails in G++14.
Locally, those two seem to both produce -2 as an answer for the first test case for both G++14 and G++17.
I am guessing I made a trivial mistake somewhere.
Could you guys enlighten me with why it passes on one but not the other? I am guessing it could be due to using unsupported/undefined behavior in G++14.
Thanks a lot!
Yongwhan