


Seriously, why so serious? And why so mainstream? Competitive programming is all about fun, therefore...
Cutting to the chase
I'll talk about something that goes like that: everyone talks about it, few really know how to do it, everyone thinks everybody else knows how to do it, so everyone claims they know how to do it.Not teenage sex, but understanding data structures. In the sense of the metaphor before, I am close to a virgin but I still can give you some insight as there are some structures that are my type.
Don't get me wrong, I am not talking about mainstream stuff like segment trees, but not so usual data structure that tend to be implemented and modeled exactly the same way each time or even not implemented(cause STL has them). So, we're gonna talk about tries and heaps.
The good ol' dictionary
We'll try to implement a structure that can handle the following queries:
- add(w) — add an apparition of word w in the data structure
- delete(w) — delete an apparition of word w in the data structure
- ask(w) — get the number of apparition of word w in the list
- lcp(w) — get a word from the data structure that has the longest common prefix with string w
Let's ignore the 4th type of query.
Now what's the simplest way to do this? Keep a list an loop through it. Nothing wrong with that, but we need faster stuff. The obvious thing that a programmer would think at is giving the words some order so that the search is faster. This is exactly what STL's unordered_map does. So a map would to the business. Supposing you want to implement it yourself, you should find a nice hashing function the problem might be solved. OK, I'll go home, we're done.
Give it a trie
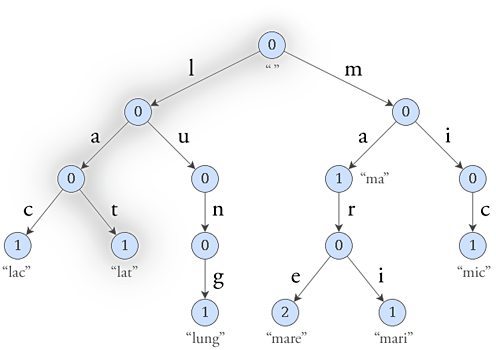
At this moment we have a decent data structure but we did not solved the 4th query. Also, we did not use one information: we are working with strings. Now we need some observation to go on: if some strings have a common prefix, the prefix should be stored only once and we would need to somehow point to more places from that position.
Now the observation, even if pertinent, does not give any simplification because we are talking about prefixes, so chunks of strings. A simple man, like me, would start with baby steps.
For starters, we'll make from each letter a node and we will bound it to the next word in the string. Suppose we introduced words "awesome" and "awful".
[a] -> [w] -> [e] -> [s] -> [o] -> [m] -> [e]
[a] -> [w] -> [f] -> [u] -> [l]
Now put the common prefix together and we have:
[a] -> [w] -> [e] -> [s] -> [o] -> [m] -> [e]
-> [f] -> [u] -> [l]
That tree structure looks quite nice, because if we will have something like that and a nice method of accessing each element we could solve this in something close to O(length * accessing) where O(accessing) is the time of the access method we choose.
Let's choose how we store data and access it. Store a root node that has no character in it — this will be the start point in the tree. Say we have only 26 chars, then we can keep a vector of pointers and the current char in each node. That's how our model looks now:
The complexities are O(length) for each operation due to the, but the memory is quite big as it can go to maximum O(totallength * SIGMA) where SIGMA is the total number of chars.


{kind=link}