Author: Baba
Testers: virus_1010 born2rule
Expected complexity: 
Main idea: Maintain counts of required characters.
Since we are allowed to permute the string in any order to find the maximum occurences of the string "Bulbasaur", we simply keep the count of the letters 'B', 'u', 'l', 'b', 'a', 's', 'r'. Now the string "Bulbasaur" contains 1 'B', 2'u', 1 'l', 2'a', 1 's', 1'r' and 1 'b', thus the answer to the problem is Min(count('B'), count('b'), count('s'), count('r'), count('l'), count('a')/2, count('u')/2). You can maintain the counts using an array.
Corner Cases:
1. Neglecting 'B' and while calculating the answer considering count('b')/2.
2. Considering a letter more than once ( 'a' and 'u' ).
Tester's code:#include <bits/stdc++.h>
using namespace std;
int main()
{
map<char, int> m;
string s;
cin>>s;
for(auto x : s)
m[x]++;
int ans = m['B'];
ans = min(ans, m['u']/2);
ans = min(ans, m['a']/2);
ans = min(ans, m['b']);
ans = min(ans, m['s']);
ans = min(ans, m['r']);
ans = min(ans, m['l']);
cout << ans << endl;
return 0;
}
Author: architrai
Testers: mprocks, deepanshugarg
Complexity : 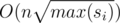 using square-root factorization and
using square-root factorization and 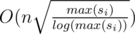 using a pre-computed sieve.
using a pre-computed sieve.
The problem can be simplified to finding a group of Pokemons such that their strengths have a common factor other that 1. We can do this by marking just the prime factors, and the answer will be the maximum count of a prime factor occurring some number of times. The prime numbers of each number can be found out using pre-computed sieve or square-root factorization.
Corner Cases : Since a Pokemon cannot fight with itself (as mentioned in the note), the minimum answer is 1. Thus, even in cases where every subset of the input has gcd equal to 1, the answer will be 1.
Tester's code:
#include<bits/stdc++.h>
using namespace std;
int N;
unordered_map<int, int> factors;
int main()
{
ios_base::sync_with_stdio(false);
cin >> N;
while(N--)
{
int strength;
cin >> strength;
int root = sqrt(strength);
for(int i = 2; i <= root; i++)
{
if(strength%i == 0)
factors[i]++;
while(strength%i ==
0) strength
/= i;
}
if(strength > 1) factors[strength]++;
}
int ans = 1;
for(auto it = factors.begin(); it != factors.end(); it++)
{
ans = max(ans, (*it).second);
}
cout << ans << endl;
return 0;
}
Author: shivamkakkar
Testers: codelegend
Expected complexity: 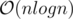
Main idea: Divide pokemon types into equivalent classes based on their counts in each list.
Consider a valid evolution plan f. Let c[p, g] be the number of times Pokemon p appears in gym g. If f(p) = q then 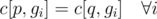 .
.
Now consider a group of Pokemon P such that all of them occur equal number of times in each gym (i.e. for each 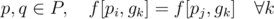 ). Any permutation of this group would be a valid bijection.
). Any permutation of this group would be a valid bijection.
Say we have groups s1, s2, s3, ..., then the answer would be |s1|! |s2|! |s3|! ... mod 109 + 7.
For implementing groups, we can use vector < vector < int > > and for i-th pokemon, add the index of the gym to i-th vector.
Now we need to find which of these vectors are equal. If we have the sorted vector < vector < int > > , we can find equal elements by iterating over it and comparing adjacent elements.
Consider the merge step of merge sort. For a comparison between 2 vectors v1 and v2, we cover at least min(v1.size(), v2.size()) elements. Hence work is done at each level. There are 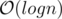 levels.
levels.
Bonus : Try proving the time complexity for quicksort as well.
Authors's code:#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
#define PB push_back
#define ALL(X) X.begin(), X.end()
#define fast_io ios_base::sync_with_stdio(false);cin.tie(NULL)
const int N = 1e6;
const LL MOD = 1e9 + 7;
LL fact[N+1];
int main()
{
fast_io;
fact[0] = fact[1] = 1;
for(LL i=2;i<=N;i++)
fact[i] = (fact[i-1]*i)%MOD;
int n,m;
cin >> n >> m;
vector< vector<int> > x(m);
for(int i=0;i<n;i++) {
int s;
cin >> s;
for(int j=0;j<s;j++) {
int t;
cin >> t;
x[t-1].PB(i);
}
}
for(int i=0;i<m;i++)
sort(ALL(x[i]));
sort(ALL(x));
LL ans = 1;
LL sm = 1;
for(int i=1;i<m;i++) {
if(x[i]==x[i-1])
sm++;
else
ans = (ans*fact[sm])%MOD, sm = 1;
}
ans = (ans*fact[sm])%MOD;
cout << ans << endl;
return 0;
}
Author: saatwik27
Testers: imamit,abhinavaggarwal,Chipe1
This problem can be solved using Dynamic Programming with bitmask.
The important thing to note here is that the set of distinct numbers formed will be a maximum of 20 numbers, i.e. from 1 to 20, else it won't fit 75 bits(1*(1 bits) + 2*(2 bits) + 4*(3 bits) + 8*(4 bits) + 5*(5 bits) = 74 bits). So, we can use a bitmask to denote a set of numbers that are included in a set of cuts.
Let's see a Top-Down approach to solve it :
Lets define the function f(i, mask) as : f(i, mask) denotes the number of sets of valid cuts that can be obtained from the state i, mask. The state formation is defined below.
Let M be the maximum number among the numbers in mask. mask denotes a set of numbers that have been generated using some number of cuts, all of them before bi. Out of these cuts, the last cut has been placed just before bi. Now, first we check if the set of cuts obtained from mask is valid or not(in order for a mask to be valid, mask == 2X - 1 where X denotes number of set bits in the mask) and increment the answer accordingly if the mask is valid. And then we also have the option of adding another cut. We can add the next cut just before bx provided the number formed by "bi bi + 1...bx - 1" <= 20. Set the corresponding bit for this number formed to 1 in the mask to obtain newMask and recursively find f(x, newMask).
Author's code:
// Saatwik Singh Nagpal
#include <bits/stdc++.h>
using namespace std;
#define TRACE
#ifdef TRACE
#define TR(...) __f(#__VA_ARGS__, __VA_ARGS__)
template <typename Arg1>
void __f(const char* name, Arg1&& arg1){
cerr << name << " : " << arg1 << std::endl;
}
template <typename Arg1, typename... Args>
void __f(const char* names, Arg1&& arg1, Args&&... args){
const char* comma = strchr(names + 1, ',');cerr.write(names, comma - names) << " : " << arg1<<" | ";__f(comma+1, args...);
}
#else
#define TR(...)
#endif
typedef long long LL;
typedef vector < int > VI;
typedef pair < int,int > II;
typedef vector < II > VII;
#define MOD 1000000007
#define EPS 1e-12
#define N 200100
#define PB push_back
#define MP make_pair
#define F first
#define S second
#define ALL(v) v.begin(),v.end()
#define SZ(a) (int)a.size()
#define FILL(a,b) memset(a,b,sizeof(a))
#define SI(n) scanf("%d",&n)
#define SLL(n) scanf("%lld",&n)
#define PLLN(n) printf("%lld\n",n)
#define PIN(n) printf("%d\n",n)
#define REP(i,j,n) for(LL i=j;i<n;i++)
#define PER(i,j,n) for(LL i=n-1;i>=j;i--)
#define endl '\n'
#define fast_io ios_base::sync_with_stdio(false);cin.tie(NULL)
#define FILEIO(name) \
freopen(name".in", "r", stdin); \
freopen(name".out", "w", stdout);
inline int mult(int a , int b) { LL x = a; x *= LL(b); if(x >= MOD) x %= MOD; return x; }
inline int add(int a , int b) { return a + b >= MOD ? a + b - MOD : a + b; }
inline int sub(int a , int b) { return a - b < 0 ? MOD - b + a : a - b; }
LL powmod(LL a,LL b) { if(b==0)return 1; LL x=powmod(a,b/2); LL y=(x*x)%MOD; if(b%2) return (a*y)%MOD; return y%MOD; }
int dp[1<<20][77];
int b[77] , n;
int go(int mask , int i) {
int cnt = __builtin_popcount(mask);
if(i == n) {
if(cnt != 0 && (1<<cnt)-1 == mask)
return 1;
return 0;
}
if(dp[mask][i] != -1) return dp[mask][i];
int ret = 0;
if(b[i] == 0)
ret = go(mask , i+1);
else {
int num = 0;
int j = i;
while(1) {
num *= 2;
num += b[j];
if(num > 20) break;
//if(!(mask & (1<<(num-1))))
ret = add(ret , go(mask | (1<<(num-1)) , j+1));
j ++;
if(j == n) break;
}
if(cnt != 0 && mask == (1<<cnt)-1)
ret ++;
}
return dp[mask][i] = ret;
}
int main() {
FILL(dp,-1);
cin >> n;
string s; cin >> s;
REP(i,0,n)
b[i] = s[i] - '0';
int ans = 0;
REP(i,0,n)
ans = add(ans , go(0,i));
PIN(ans);
return 0;
}
Author: satyam.pandey
Testers: Superty,vmrajas
We can easily see that f0 = 2(number of distinct prime factors of n). We can also see that it is a multiplicative function.
We can also simplify the definition of fr + 1 as:
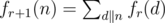
Since f0 is a multiplicative function, fr + 1 is also a multiplicative function. (by property of multiplicative functions)
For each query, factorize n.
Now, since fr is a multiplicative function, if n can be written as:
n = p1e1p2e2 ... pqeqThen fr(n) can be computed as:
fr(n) = fr(p1e1) * fr(p2e2) * ... * fr(pqeq)Now observe that the value of fr(pn) is independent of p, as f0(pn) = 2. It is dependent only on n. So we calculate fr(2x) for all r and x using a simple R * 20 DP as follows:
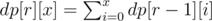
And now we can quickly compute fr(n) for each query as:
fr(n) = dp[r][e1] * dp[r][e2] * ... * dp[r][eq] Author's code:
//Kyokai no Kanata //
//Written by Satyam Pandey//
#include<bits/stdc++.h>
using namespace std;
typedef pair<int,int> II;
typedef vector<II> VII;
typedef vector<int> VI;
typedef vector< VI > VVI;
typedef long long int LL;
#define PB push_back
#define MP make_pair
#define F first
#define S second
#define SZ(a) (int)(a.size())
#define ALL(a) a.begin(),a.end()
#define SET(a,b) memset(a,b,sizeof(a))
#define si(n) scanf("%d",&n)
#define dout(n) printf("%d\n",n)
#define sll(n) scanf("%lld",&n)
#define lldout(n) printf("%lld\n",n)
#define fast_io ios_base::sync_with_stdio(false);cin.tie(NULL)
#define TRACE
#ifdef TRACE
#define trace(...) __f(#__VA_ARGS__, __VA_ARGS__)
template <typename Arg1>
void __f(const char* name, Arg1&& arg1){
cerr<<name<<" : "<<arg1<<endl;
}
template <typename Arg1, typename... Args>
void __f(const char* names,Arg1&& arg1,Args&&... args){
const char* comma=strchr(names+1,',');
cerr.write(names,comma-names)<<" : "<<arg1<<" | ";__f(comma+1,args...);
}
#else
#define trace(...)
#endif
float inf=std::numeric_limits<double>::infinity();
LL INF=std::numeric_limits<LL>::max();
//FILE *fin = freopen("in","r",stdin);
//FILE *fout = freopen("out","w",stdout);
const int R=int(1e6)+5,P=25,N=R,mod = int(1e9)+7;
int F[R][P],LP[N];
inline void seive(){
LP[1]=1;
for(int i=2;i<N;i++){
if(!LP[i])
for(int j=i;j<N;j+=i)
LP[j]=i;
}
}
inline void precalc()
{
for(int i=0;i<R;i++) F[i][0] = 1;
for(int i=1;i<P;i++) F[0][i] = 2;
for(int i=1;i<R;i++)
for(int j=1;j<P;j++)
F[i][j] = (F[i][j-1] + F[i-1][j])%mod;
}
inline LL solve(int r,int n)
{
LL ans=1;
while(n!=1)
{
int cnt=0,p=LP[n];
while(n%p==0) n/=p,cnt++;
ans=(ans*F[r][cnt])%mod;
}
return ans;
}
int main()
{
seive();precalc();
int q;si(q);
int r,n;
while(q--)
{
si(r);si(n);
lldout(solve(r,n));
}
return 0;
}
Author: Baba
Testers: shubhamvijay, tanmayc25, vmrajas
Expected complexity: 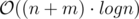
Main idea: Building Dominator tree on shortest path DAG.
First of all, we run Dijkstra's shortest path algorithm from s as the source vertex and construct the shortest path DAG of the given graph. Note that in the shortest path DAG, the length of any path from s to any other node x is equal to the length of the shortest path from s to x in the given graph.
Now, let us analyze what the function f(s, x) means. It will be equal to the number of nodes u such that every path from s to u passes through node x in the shortest path DAG, such that on removing node x from the DAG, there will be no path from s to u.
In other words, we want to find the number of nodes u that are dominated by node x considering s as the sources vertex in the shortest path DAG. This can be calculated by building dominator tree of the shortest path DAG considering s as the source vertex.
A node u is said to dominate a node w wrt source vertex s if all the paths from s to w in the graph must pass through node u.
You can read more about dominator tree here.
Once the dominator tree is formed, the answer for any node x is equal to the number of nodes in the subtree of x in the tree formed.
Author's code://Tanuj Khattar
#include<bits/stdc++.h>
using namespace std;
typedef pair<int,int> II;
typedef vector< II > VII;
typedef vector<int> VI;
typedef vector< VI > VVI;
typedef long long int LL;
#define PB push_back
#define MP make_pair
#define F first
#define S second
#define SZ(a) (int)(a.size())
#define ALL(a) a.begin(),a.end()
#define SET(a,b) memset(a,b,sizeof(a))
#define si(n) scanf("%d",&n)
#define dout(n) printf("%d\n",n)
#define sll(n) scanf("%lld",&n)
#define lldout(n) printf("%lld\n",n)
#define fast_io ios_base::sync_with_stdio(false);cin.tie(NULL)
#define TRACE
#ifdef TRACE
#define trace(...) __f(#__VA_ARGS__, __VA_ARGS__)
template <typename Arg1>
void __f(const char* name, Arg1&& arg1){
cerr << name << " : " << arg1 << std::endl;
}
template <typename Arg1, typename... Args>
void __f(const char* names, Arg1&& arg1, Args&&... args){
const char* comma = strchr(names + 1, ',');cerr.write(names, comma - names) << " : " << arg1<<" | ";__f(comma+1, args...);
}
#else
#define trace(...)
#endif
//FILE *fin = freopen("in","r",stdin);
//FILE *fout = freopen("out","w",stdout);
const int N = int(1e5)+10;
const int M = int(2e5)+10;
const LL INF = LL(1e16);
namespace Dominator{
VI g[N],tree[N],rg[N],bucket[N];
int sdom[N],par[N],dom[N],dsu[N],label[N];
int arr[N],rev[N],T;//1-Based directed graph input
inline int Find(int u,int x=0){
if(u==dsu[u])return x?-1:u;
int v = Find(dsu[u],x+1);
if(v<0)return u;
if(sdom[label[dsu[u]]]<sdom[label[u]])
label[u] = label[dsu[u]];
dsu[u] = v;
return x?v:label[u];
}
inline void Union(int u,int v){ //Add an edge u-->v
dsu[v]=u; //yup,its correct :)
}
inline void dfs0(int u){
T++;arr[u]=T;rev[T]=u;
label[T]=T;sdom[T]=T;dsu[T]=T;
for(int i=0;i<SZ(g[u]);i++){
int w = g[u][i];
if(!arr[w])dfs0(w),par[arr[w]]=arr[u];
rg[arr[w]].PB(arr[u]);
}
}
inline void dfs1(int u,int p,int sub[]){
sub[u]=1;
for(auto w:tree[u])
if(w!=p)
dfs1(w,u,sub),sub[u]+=sub[w];
}
inline void reset(int n){
for(int i=1;i<=n;i++){
g[i].clear();rg[i].clear();tree[i].clear();arr[i]=0;
}
T=0;
}
void addEdge(int u,int v){
g[u].PB(v);
}
//Build Dominator tree(in main)
void get(int n,int root,int sub[]){
dfs0(root);n=T;
for(int i=n;i>=1;i--){
for(int j=0;j<SZ(rg[i]);j++)
sdom[i] = min(sdom[i],sdom[Find(rg[i][j])]);
if(i>1)bucket[sdom[i]].PB(i);
for(int j=0;j<SZ(bucket[i]);j++){
int w = bucket[i][j],v = Find(w);
if(sdom[v]==sdom[w])dom[w]=sdom[w];
else dom[w] = v;
}if(i>1)Union(par[i],i);
}
for(int i=2;i<=n;i++){
if(dom[i]!=sdom[i])dom[i]=dom[dom[i]];
tree[rev[i]].PB(rev[dom[i]]);
tree[rev[dom[i]]].PB(rev[i]);
}
dfs1(rev[1],rev[1],sub);
}//done :)
}
int n,m,s,vis[N],sub[N];
VII g[N];VI P[N];
LL d[N];
int dijkstra(int root){
for(int i=1;i<=n;i++)d[i]=INF,P[i].clear();
Dominator::reset(n);d[root]=0;SET(vis,0);
set<pair<LL,int>> S;S.insert({d[root],root});
while(!S.empty()){
int u = S.begin()->S;
S.erase(S.begin());
if(vis[u])continue;
vis[u]=1;
for(auto w:g[u])
if(d[u] + w.S < d[w.F]){
d[w.F] = d[u] + w.S;
P[w.F].clear();P[w.F].PB(u);
S.insert({d[w.F],w.F});
}
else if(d[u]+w.S==d[w.F])
P[w.F].PB(u);
}
for(int i=1;i<=n;i++)
for(auto j : P[i])
Dominator::addEdge(j,i);
Dominator::get(n,root,sub);
int mx = 0;
for(int i=1;i<=n;i++)
if(i!=root)
mx = max(mx,sub[i]);
return mx;
}
int main()
{
si(n);si(m);si(s);
for(int i=1;i<=m;i++){
int u,v,w;
si(u);si(v);si(w);
g[u].PB({v,w});
g[v].PB({u,w});
}
dout(dijkstra(s));
return 0;
}
Another approach for forming dominator tree is by observing that the shortest path directed graph formed is a DAG i.e. acyclic. So suppose we process the nodes of the shortest path dag in topological order and have a dominator tree of all nodes from which we can reach x already formed. Now, for the node x, we look at all the parents p of x in the DAG, and compute their LCA in the dominator tree built till now. We can now attach the node x as a child of the LCA in the tree.
For more details on this approach you can look at jqdai0815's solution here.





