


Hello.
After getting prize on ICPC 2020 Seoul Regional and writing Round #633, I almost stopped solving CP problems and entered quant industry. Now I have no job so I am not busy until I get next job, so I often describe my thoughts on online websites. This article is one of those. In this post, I am going to write about some common CP code practices which I think would be better changed. Before enumerating practices, I want to specify that this post is mostly focused to:
- Who wants to get dev jobs
- Who wants to create their practices from CP to productions without switching code style too much (i.e. Not having too different mindset for coding styles in CP and real applications)
If you just don't care, it's ok. I am not saying writing CP-style codes is bad, unless you believe you can use same practices on productions. Now let's dive in.
using namespace std;
What happens if you include big header files like bits/stdc++.h and do this? Bunch of functions, classes, constant variables will be loaded to the global namespace.
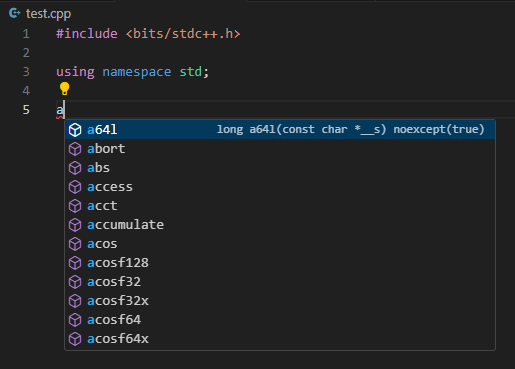
You never do this in production. How about CP? Does it boost runtime performance that makes you get AC without writing optimized algorithms? The only benefit of this code is you can access specific function or classes in std namespace with slightly less typing. You cannot define the variable or function with same signature, and there are way too many pre-defined signatures(and probably macros, but I don't know much) in std namespace. If you really want to make a shortcut for some frequently accessed types or functions, just use typedef or make a function pointer for that.
Abusing macros
Let's consider following code contains some macros;
#include <utility>
#define f1 first
#define f2 second
#define N 100005
int main(void)
{
std::pair<int, double> x;
auto x1 = x.f1;
auto x2 = x.f2;
int array[N];
return 0;
}
There are two points. The first one is I don't really understand why shorthand for methods like first is needed. Nowadays many modern IDEs provide good intellisense that helps you to auto-complete the methods, types, variables, macros, and more. The second one is it's just better to use constexpr var_type var_name = var_value; for constants. The biggest reason for two points is, macro is basically a inplace string(code) conversion that happens before main compliation process. For more information about pre-processing, please refer here. Because of how macro works, sometimes the unexpected bug will happen by misuse of macros. I've even seen stupid macros like #define int long long, which overrides the primitive type name. Following code is the minimal example;
#include <iostream>
#define triple(x) x * 3
int main(void)
{
std::cout << triple(5 + 1) << std::endl;
}
Above code outputs $$$8$$$ ($$$5 + 1 \times 3 = 8$$$), not $$$18$$$. But what if you still wants to make your own shortcut or constant variables? I suggest following examples using pointers to members and constexpr (Refer here for Microsoft tutorial about pointer to members and constexpr);
#include <utility>
constexpr int N = 100005;
const auto f1 = &std::pair<int, double>::first;
const auto f2 = &std::pair<int, double>::second;
int main(void)
{
std::pair<int, double> x;
auto x1 = x.*f1;
auto x2 = x.*f2;
int array[N];
return 0;
}
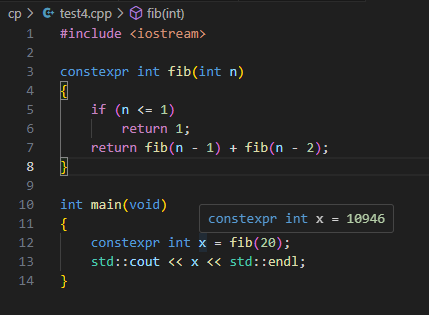
Especially constexpr is very powerful, that directs your compiler to do "compile-time calculation" for possible cases.
Using library internal functions or compiler-specific extension features
Since gcc is one of the mostly used C++ compilers in many CP platforms, you can easily see the code using features that only works under gcc. Example builtins here. Of course, even in productions, sometimes you need exceptional performance so the company uses the same version of OS, languages, compilers and other 3rd party softwares. But if you depends on too specific version of external stuffs that is not guaranteed to work but subject to change, it's dangerous, because sometimes the software will yield different values on same codes, just by using different compilers(even just different minor versions). Some internal functions are guaranteed to work on specific major version, and maybe that's ok. But not all functions or macros are like that.
If I notice any more cases, will add here. Thanks for reading this, and happy coding.






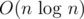 and
and 