


Hi everyone! I was always wondered how cleverly interwoven so-called string algorithms. Six months ago I wrote here article about the possibility of a rapid transition from Z-function to prefix-function and backward. Some experienced users already know that such transitions are possible between the more complex string structures — suffix tree and suffix automaton. This transition is described at e -maxx.ru. Now I would like to tell you about such data structure as a suffix tree, and share the simple enough (theoretically) way of its fast building — obtain a suffix tree from suffix array .
I remind you that a suffix tree is a prefix tree, that contains all suffixes of specified string. In the simplest implementation it will require O(n2) time and memory — we simply add in the trie all suffixes one by one until we get what we want. In most cases it's too large. We will try to do something with it.
At first we will reduce the memory complexity to O(n). In order to do this we need to get the following idea: if we have a group of edges that are connected in series and do not have branches, we can combine them into one, which will be presented with some substring, but not a single character. Thus, we obtain a compact trie (also known as radix tree or patricia tree). But that's not all. Finally, we note that we have no need to store the entire substring on the edge, so we can store only the indices of its beginning and its ending in the source string. That is what will give us the desired linear complexity. Really, vertices in our tree will now appear only in places separating lexicographically consecutive suffixes, and there will be no more than n - 1 of such places.
Finally, let's reduce time complexity to O(n). In order to do this, we will approach the following strategy:
1) Add to the trie lexicographically minimal suffix.
2) For each of the next suffixes we will rise to lcp[i] and continue building trie from here.
Surprisingly, this will be enough. In fact, the actions we will do are identical to the depth-first traversal of tree, which obviously runs in O(n).
Wait a minute, but in the title is written "building in O(nlogn)", and you got O(n), wtf?
Indeed, in fact, if we have a lcp array, suffix tree can already be built in O(n). However, there still remains one problem — we need to get in some way lcp array. And here we come to the aid of suffix array, which can be used in order to get lcp. Relatively simple method for this is described on the site e-maxx.ru. We also can get it in O(n) using Kasai algorithm. Finally, we can combine it with some linear suffix array algo in order to get suffix tree with O(n) complexity.
Advantages of this method:
- Simple to understand.
- Acceptable time and memory complexity.
disadvantages:
- Algorithm only works offline.
- The amount of code. It took me almost 300 lines (100 of which — for a suffix array), and then the whole evening to do something that will work. It was the first time for me building the suffix tree, so I can not say for sure whether it is possible to implement this algorithm easily.
Here, you can also see an example of code that does all these atrocities to create a suffix tree. Good luck to everyone and see you soon, I hope the article will be interesting :)
To check the correctness of the code were used the following tasks:
1393 — validation of building lcp.
1590 — validation of building suffix tree.







@adamant:Very Nice Tutorial.If possible can you write the comments in English so that other users are able to understand
There's also the possibility to build the suffix array in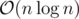 and then construct the suffix tree from that.
and then construct the suffix tree from that.
EDIT Nevermind, I see you are using that same idea already :) Although I don't see why you would need 100 LoC to implement suffix array + LCP in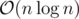 . Our implementation is a mere 24 lines, but it's
. Our implementation is a mere 24 lines, but it's 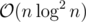 since it does not contain a linear time sort.
since it does not contain a linear time sort.
Your implementation has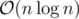 memory complexity in spite of my
memory complexity in spite of my 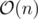 . But anyway, your way to calculate suffix array is kinda interesting, thanks a lot!
. But anyway, your way to calculate suffix array is kinda interesting, thanks a lot!
Ah, I see, yes that's a difference.
Isn't your suffix array build nlog2(n)? log(n) iteration in line 8 and nlog(n) for sorting in line 10. Correct me if i'm wrong.
Yes I changed the code in the meantime. It used to use LSB radix sort, but that seems slower in practice.
If you really need better performance than this, which sometimes becomes necessity, you can use the one that implements bucket sort. Otherwise yours is way better, both to understand and code.
I have a question.
I build Suffix array (SA) and longest common prefix array (LCP) of a string ending in #, now I proceed to create suffix tree.
I can separate SA in buckets for first character, then, for each bucket I can insert first suffix in the tree but when I try to insert second item, can I get the node where I have to put new item in O(1)? I can only think in binary search saving each instance to inserted nodes for each item.
Example:
assume we inserted suffixes 0, 1, 2, 3 now, when I have to insert sa[4], what is the best way for getting node x (see picture)?
I hope my question is clear, thanks.
You're such an artist X_X
I don't know exactly but it looks like you can't. But as I said in the entry, if you will just move up on tree every time, it will be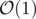 amortized because of its identity to dfs on tree. If you want to get moving to the next node non-amortized, you can keep for each node its ancestors that are pows of 2, i.e. 1, 2, 4, 8, 16, etc. Then you can get to the needed node in
amortized because of its identity to dfs on tree. If you want to get moving to the next node non-amortized, you can keep for each node its ancestors that are pows of 2, i.e. 1, 2, 4, 8, 16, etc. Then you can get to the needed node in 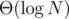 using this information.
using this information.
I'm writing my algorithm but I get struggle in that part.
What did you use in your implementation?
After adding some node to the tree I just move upward to the lcp[i] position and add next node there.
After lots of debugging, I finally get an implementation (java) that seems to work (at least with my tests).
But I can't pass TLE in this
I wonder if is possible to use this trick in java.
My suffix array is O(n log n)
Can you show your code?
link
It have comments.
Well, firstly I see that you always duplicate the node when inserting it. Maybe, you should do it only when you need (i.e. you shouldn't duplicate the node if it will be exact son). Also maybe you should try
map<char,int>to get O(nlogk) instead of O(nk)I just understood that my entry has no useful pictures. Well, if somebody is interested in them, here is picture, showing suffix tree of k790alex's string made via GraphViz. * after the string means that this node can be the last in some suffix.