


Всем привет!
Совсем скоро, 27 апреля в 19:30 MSK состоится Codeforces Round #243, автором которого являюсь я. Это мой одиннадцатый раунд на Codeforces и я надеюсь, что не последний.
Спасибо Геральду Агапову (Gerald) и Ярославу Твердохлебу (KADR) за помощь в подготовке раунда и Марии Беловой (Delinur) за перевод условий на английский.
Настоятельно рекомендую прочитать условия ВСЕХ задач.
Разбалловка в первом дивизионе 500-1000-1500-2000-2000. Во втором стандарт.
Gl & hf ! :)







Thanks for the recommendation. :)
This information might be handy during the competition.
Ого, даже оповещение по почте вовремя пришло Оо
Ты единственный человек, которого не раздражает всякий спам на почте
Эм, у меня нет почты
То чувство, когда этот коммент получил лайков больше, чем анонс перед раундом)
fixed
Ура!!! Наконец-то раунд от Sereja!
Скоро "Ура!!! Автор раунда Sereja" станет таким же баяном как "Желаю всем удачи!"
nice to have the regular rounds back :)
Another Sereja round to enjoy. Thanks and good luck to everyone :D
И снова раунд от любимого автора, будет интересно)
Русский делает тебя успешным:)
Если кто-то занимается изучением теории хаоса — из исследования рейтинга комментариев получилась бы интересная научная работа)
proof
ًWhat's meant by Gl & hf ?
Gl & Hf == "Good Luck and Have Fun!"
Good luck & have fun)
hey sereja ! u r my best consest writer. I think u prepare too smart problems :)
Time for some Sereja and [?] problems ... :-)
Lets hope for math/ad-hoc problems!
yeeeeeeeeeeeeeeeees , another Sereja round
yes , another Sereja round :D
3^5-ый раунд, однако.
3^3-го апреля.
осталось занять 3^1 место и все будет чудесно!:)
Лучше 3^0 :)
I strongly recommend you to read ALL the problems.Not usually written by other authors... :)
Эх, обидно пропускать раунд от любимого автора.
P.s. у меня предложение добавить авторов в список контестов в том числе и в те к которым обратный отсчет.
Thanks for your efforts for preparing problems:)
*standard — not standart ;)
OK :)
And as I remember this mistake has become a standart issue :D
А я уже надеялся что будут взломы...
Они есть :)
Но мало :(
Problem D : I think that you wanted to say : two cells are connected if they are adjacent in sAme row or sAme column of the table NOT : two cells are connected if they are adjacent in sOme row or sOme column of the table
Am I right ? ;)
DELETED
Задачки класса "давай домой во второй див". Чтоб хоть немного самооценку вернуть
Ага) Жди меня и я вернусь! Мой родной див 2! Только влез я в див 1, Но домой пора! Будем вместе мы решать, Все халявки скоро. А пока го раунд ждать!:)
Будем вместе мы решать, Все халявки скоро. А пока го раунд ждать, Выпью
чайкукофе с горя! :)судя по размеру, в слове "чайкУ" ударение должно быть на "чАйку", а это как-то страшно звучит :)
Согласен :)
Можно сказать "чаю" :)
What is the approach to solve Div2 C / Div1 A?
Simple brute force in O(N^3) + Sorting in O(NlogN) should easily pass the time limit.
Bruteforce, more or less. Try all possible ranges [l, r]; for each of them, put the numbers from that range into a multiset and the numbers not from it into another multiset. As long as swapping the largest number out of the range and the smallest number in the range improves the result (and you still have swaps available), swap them. Time: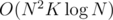 .
.
So we have an O(N^2) for choosing the ends of the interval, but how can we do the rest in O(KlogN)?
Since you are using a set, elements will be searched in O(log n) and you have to choose 'k' such elements.
But inserting N elements with take O(N*logN) in a multiset. I feel the time complexity for this solution will be O(N^3*K*logN)
My solution along the same lines works in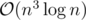 .
.
I'm sorry for the offtopic, but how do you get such O?
Via \mathcal{O} in
Unable to parse markup [type=CF_TEX]
:this looks really cool! :)
looks really cool! :)  looks cooler than
looks cooler than 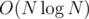 and
and 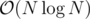 :D
:D
and i think
My solution's complexity is O(N^2*logN + N*K*logN)
There are at most K allowed swaps and each can be done in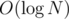 (because multiset).
(because multiset).
Any way to solve it without multiset?
Sort the numbers that you'd put into multisets otherwise and do the swapping the same way.
Can you provide the link to a properly implemented solution? Thanks in advance!
6490192
Bruteforce all l..r on array (for for), and try to calculate the best value on l..r by swapping worst values with best from 1..l-1 & r+1..n. I did it with sorting, but the best approach I saw is to create two piority queues "in, out" and take r-l+1 values from them (don't take more than "k" values from "out" queue)
Its a pity that, Div1 D is same as this ONTAK problem
Div1 D was same as this ONTAK problem
EDIT : Also it exist at stackoverflow
Yes, it seems that it is a very well-known problem.
Is there any detailed analysis of the complexity?
The one on StackOverflow does not requires sides parallel to axis.
Yes, but the algorithms described in the answers are very, very slow.
At the bottom there is a link to a paper.
Btw, I like how the answer on StackOverflow which is clearly the most valuable has -1 votes :)
Because it just contains a link. Link-only answers are only valuable as long as the link is valid, so they are very susceptible to link-rot. One is expected to at least summarize the contents of the linked resource so that the answer does not lose its value if the link goes dead. Note that this particular answer does not even mention the title of the paper, which could be used to locate the resource later.
Also I feel that pointing to a 23-page paper does not cut it for this problem. At the very least I would expect the poster to point to the page where the actual problem of finding squares is addressed. But I would really prefer to see a paraphrased overview over the algorithm, so that I can quickly examine whether it actually addresses the problem without reading through pages of scientific notation. Remember that Stack Overflow is for regular users not necessarily with a background in Computer Science.
Stack Overflow still has the vision to create an archive of programming knowledge for the future, not just to make a single question asker happy for the moment.
what is the idea behind the problem D(div 1) ?
I had an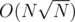 solution. A square is uniquely defined by its 2 top (or 2 bottom etc.) points. Split the horizontal lines into large (at least
solution. A square is uniquely defined by its 2 top (or 2 bottom etc.) points. Split the horizontal lines into large (at least  points on the line) and small (otherwise); then, there are just
points on the line) and small (otherwise); then, there are just 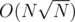 squares whose 2 top points lie on a small line, same for those whose 2 bottom points lie on a small line and 2 top ones on a large one.
squares whose 2 top points lie on a small line, same for those whose 2 bottom points lie on a small line and 2 top ones on a large one.
There are at most large lines. For each point on one of these lines and each line below it, you can also check if there's a square for which these are 2 right points. There are also
large lines. For each point on one of these lines and each line below it, you can also check if there's a square for which these are 2 right points. There are also 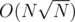 these questions.
these questions.
How to check the existence of many pairs of points (out of which all lie on 1 horizontal line)? Just make a vector saying if there's a point with some x-coordinate. You can do this for many lines with 1 vector, taking just O(1) time per query + O(N) time amortized for filling and cleaning the vector.
Or you could use the fact that unordered_set is extremely fast and write something very short like this: click ^_^
Wow, that looks useful. I don't know more about unordered_set than it erasing a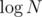 -factor in theoretical complexity (and decreasing the practical one) :D
-factor in theoretical complexity (and decreasing the practical one) :D
I really liked next comparation:
vx[x[i]].size() < vy[y[i]].size()in HellKitsune's solution.I believe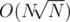 hides behind it, does it? How to prove that? :)
hides behind it, does it? How to prove that? :)
After reading the code again, I think it is O(n^1.5)
To be honest, I have no idea how to prove it formally. :(
But informally, we will most likely achieve the highest number of iterations if for each point we minimize the difference between the number of points lying on the same horizontal and the same vertical line with it. It then only seems logical to assume that the worst case scenario for this algo would be when the points form a square, which would give us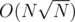 complexity.
complexity.
True.
I got AC on your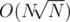 approach using unordered_set and got TL on
approach using unordered_set and got TL on 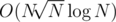 using set.
using set.
Does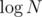 makes such a big difference? Or is it constant behind C++ set implemenation?
makes such a big difference? Or is it constant behind C++ set implemenation?
However, author's approach has no unordered_set tricks. But I could not implement it.
Consider log N a factor of 20. It's a pretty good approximation.
У Вас было, что в задаче С (див 2) на семплы программа дает верные ответы, а система пишет "Неверний ответ на претест 1" или это было только у меня?
Неплохо было бы выложить и код самой программы (http://pastie.org/).
В компиляторе проблема.
Нет. Небыло. Всё ок.
Есть замечательная вкладка "запуск", с помощью которой можно следить за тем, как работает программа на тестирующем сервере.
99% что у тебя неинициализированные переменные есть
Похоже на то:
x.cpp: В функции «int main()»: x.cpp:42:35: предупреждение: «p2» may be used uninitialized in this function [-Wmaybe-uninitialized] for(i=0; i=p1 && i<=p2) { i=p2; continue; } else if(a[i]>a[s1]) s1=i; ^ x.cpp:42:26: предупреждение: «p1» may be used uninitialized in this function [-Wmaybe-uninitialized] for(i=0; i=p1 && i<=p2) { i=p2; continue; } else if(a[i]>a[s1]) s1=i; ^Paper for problem D and harder versions of it!!!
Link
Uhm, this paper is about checking if set of points contains desired figure, not about counting them.
But the algorithm can be easily used to count number of figures.
It's proved in the article that there's at most O(N1.5) squares in the plane and existence of the square is checked using brute force over all possible candidates.
I used this article to solve this problem. Is there faster approach than O(N1.5log(N))? log(N) is for checking if the point is in set and I think we can avoid that logarithm but what about better estimation than O(N1.5)?
How to solve B ? It was awsome. :)) But I did not get the idea.
Deleted.
n, m <= k : bruteforce by any possible first row
otherwise : freese one row and calculate min changes in case of this row is unchanged
6492596
If n>10 or m>10 there must be at least 1 line that does not change. Then iterate all such possible line. We know one line, so we know vertical partition of initial table and can easily find minimum number of changes.
If n<=10 and m<=10 iterate all possible first lines(2^m) and we know one line again.
I observed that if you have a line fixed you can compute the answer, but I didn't noticed that. Now it seems kind of obvious. Thanks. :)
"If n>10 or m>10 there must be at least 1 line that does not change"-why?
because "k <= 10" !
because k <= 10 and you can't change more than k rows/columns.
И, как обычно..

very strong pretests
low chance for hacks
Такое чувство, что С была просто на "заметь, что 103 ≤ e".
when will the ratings be updated?
soon
на Д по-видимому слабые тесты. Моя решение прошло, хотя не должно было. Локально у меня на некоторые тесты рабоатет 10 сек
Проверьте в "запуске". На КФ тестирующие сервера очень мощные.
запустил. На кодфорсе работает 3 сек (ТЛ — 2 сек)
Может быть, задержка из-за медленного интернета?
Надеюсь, это шутка
А было бы прикольно — написал контест с хорошего анлима и n^4 зашел там, где надо было n^3.
Написал за О(1), а из-за медленного интернета получил ТЛ
При чем тут скорость интернета?
Div.1 B What about this case, what's the answer please? 3 4 10 1 0 1 1 0 0 1 1 1 1 1 1
2, it can be turned to 1011 1011 1011
what positions should be inversed ?
Thx...
Think about your number of rows, and try to figure out the answer from that! (Can odd rows be mirrored)
actually they are talking about div1 B not div2 B.
I could not understand the problem C correctly until someone explained to me after the contest. a quote from the problem statement "the element of sequence a with the maximum index among the chosen ones must be equal to the element of sequence b with the maximum index among the chosen ones; remove the chosen elements from the sequences."
If the maximum indices of two chosen values are equal, it means you take same number of elements from the sequence, isn't it? Shouldn't the wording be "the index of sequence a with the maximum value" instead of "the element of sequence a with the maximum index"?
This means that the last deleted elements must be same in both sequences.
Ah... I think I was just wrong. Thank you.
What's wrong with removing the same number of elements from each sequence? It's a perfectly valid move.
But since taking any more elements than the equal ones seems to be a non-optimal strategy, "maximum value" should mean the same as "maximum index".
That's a clear explanation. I now understand the problem statement :) Thanks!
Though I got it correctly during the contest I still don't see why it wasn't smth like: "both prefixes should end with same number", which is shorter and easier to understand. Sometimes formal language is too formal.
Yes, I feel that sometimes problems on CodeForces are about deciphering the problem statement rather than understanding it and then having insights. Some authors also seem to be really into mathematical symbolic notation :)
why is rating update delayed?
Because it's going to be unrated!!!! hahahaha =)))))))
That wasn't very funny, and that you needed to add your laughter at the end didn't help. I guess you're going to be downvoted.
Hey, glad you made it back to red.
What exactly is the special point of test 22 of Problem B(Div 2)? Many got WA.
You should check if
n % 2 == 0before each iteration.Test:
You should output 3, but ouput 3 / 2 = 1.
my code works fine with that case, still don't know why WA on 22 :(
my submission](http://codeforces.net/contest/426/submission/6491099)
gives wa on your code
answer should be 1 right?
No, it should be 3. You cannot get 3 rows by mirroring one.
thank you very much, to correct something I forgot that part xD
I think it's all 0's, shows a portion of 100 * 100 grid in the submissions page.
Good round, thanks.
Мое решение на div1 A слетело на тесте 1 1 -1 . На самом глупом тесте....
WTF? В RCC Warmup я ничего не решил, при этом сильно опустившись в рейтинге. Сегодня решил две задачи, сопоставимые по сложности с Warmup'ом, и опустился еще ниже. Капитан объективность тихо плачет в подушку.
The problems in div1 are pretty good except problem D. Problem D in div1 is so classic that so many people have solved it before (at least I knew several well-known OJs have problems almost the same). And its time limit is so tight I thought. I first used std::set but got TLE at pretest 13 several times. But I changed my code to use lower_bound in a sorted std::vector, I got accepted. That's why I thought its time limit is too tight somehow. Does anyone agree with me?
No, I don't agree with you. Using operations like lower_bound take log N complexity, so you got complexity O(n^3/2 log n) instead of O(n^3/2) so you shouldn't be surprised that you got TLE. Even more — tests weren't in fact maxtests. They could have been more time-demanding.
Besides,
set<>has a large constant factor. Sorting is generally much faster thanset<>operations, and this could serve as a lesson for you to prefer sorting in the future.I got my solution passed after changing from finding a point in O(log (n^2)) (i.e. 2 log n) to O(log n). Simply store a set for each possible x instead for all. However, I think the time limit is fine after all.
Look at my solution 6490475
Although I aware of N^1.5 solution, my solution, which base on two pointer method is O(N^2)
If the test case is strong enough to contains test which is two far away parallel line ( <0,0>, <100000,0>, <0,1>, <100000,1>, ... ) my program would be easily TLE
I realize it after the contest already end. So I'm lucky one to pass the problem D
At least to me, C/Div.2 was much easier to implement than B/Div.2. Any one thinks the same?
Ам, а где разбор или я чего-то не вижу дайте ссылку если есть заранее спасибо;
Round Stats
По поводу качества тестов к задаче D. Зачем сильно себя напрягать, если можно написать решение, работающее за квадрат:6505142? Оно на тесте из двух прямых q=i/2;w=i%2; работает 5 секунд, но это не важно. Авторские проходит.
Я генерил тесты разбивая отдельно на тяжелые и маленькие. Странно, что так вышло :(
My solution for D problem got AC luckily. I have thought that the complexity of my solution is O(n^1.5) but it is really O(n^2). For each point, my solution calculate right points, below points, and right-below points, then use three pointer to count how many square. The complexity become O(n^2) in this kind of input:
Execute the solution with larger input (with the same type of above input), I have the following statistic: - In my computer, Intel Pentium 2.2GHz, n=100000, the time is 22.312s - In my computer, compile with -O2, n=100000, the time is 3.444s I can not try to run the solution in Codeforces because my input is larger than 256KB (my input is 1020KB)