


Доброго всем времени суток!
Не столь давно во время отборочно-тренировочных занятий команды Украины перед Международной лингвистической олимпиадой был озвучен ряд довольно интересных задач на составление словарей. Что они из себя представляют? В общем случае задача такого плана формулируется следующим образом:
Необходимо составить словарь слов так, чтобы асимптотически минимизировать время поиска слова в нем, которое определенной характеристикой.
Пример: Необходимо составить словарь слов так, чтобы асимптотически минимизировать время поиска строки в нем, полностью совпадающей с строкой на входе. Очевидно, в таком случае неплохим вариантом будет стандартный словарь, в котором слова отсортированы в алфавитном порядке (тогда алгоритмом бинарного поиска мы за логарифмическое время от количества слов найдем нужную статью) (хотя на самом деле это не оптимальный вариант, но об этом чуть позже).
Позже мы решили, что операцию открытия страницы с заданным номером или статьи с заданным номером мы можем выполнять за константное время. В таком случае словарь из примера можно оптимизировать, задав функциональную зависимость между строкой и номером статьи, которая ей соответствует (или, если говорить по-людски, посчитать хеш). Тогда мы сможем искать слово за время, пропорциональное длине слова, что уже несколько круче. В принципе, используя этот подход (хеширование входных данных) может помочь нам составить необходимый словарь для любой такой задачи так, чтобы ответ искался за время, пропорциональное размеру входных данных. Поэтому всплыла еще одна характеристика — размер словаря.
Собственно, задача, которая и спровоцировала небольшой холивар, формулируется так:
Необходимо составить словарь слов так, чтобы асимптотически минимизировать время поиска слова в нем, которое подходит под заданную маску.
П.С. маска — строка из символов алфавита + специального символа (скажем, "?"), который можно заменить на любую одну букву из алфавита. П.П.С. так как задачу оптимизации времени мы вроде как решили, предлагаю вам подумать над тем, как можно ужать размеры словаря так, чтобы особо не терять во времени.







В чем проблема написать бор для поиска слов, подходящих для маски? Сложность, очевидно, KnL, где n — количество неизвестных символов в маске, K — размер алфавита, L — длина строки
Так многовато же. Размер алфавита обычно 20-30, количество неизвестных символом может достигать и 7-8.
Хотя может быть и еще больше.
Если у вас есть слово "?????" то меньше чем за эту сложность вы никак не найдете все подходящие. Или вам нужно хотя бы одно слово, подходящее под маску?
хотя бы одно
Как тогда насчет следующей эвристики: для последовательностей из одной, двух и трех букв записываем слова, в которых они встречаются, и, соответственно, позиции, с которых они начинаются. Если во входном шаблоне "?" мало, то бором, а если много, то выделяем первый определенный участок текста ('abc' для '???abc??de') и ищем в соответствующем для этого отрывка списке слов
"?a?b?c?d?e?f?g?h?i?j?k?"...
Если словарь предназначен для практического использования в реальной жизни, то вероятность такого запроса маловероятна. Хотя эвристику можно немного переделать: довольно-таки ясно, что если мы знаем достаточно большое число букв в начале, то они задают его с не очень большим разбросом(в отличии от окончания, которое может совпадать у большого числа слов, вроде "ый" или "ться"), и если мы из первых пяти букв знаем хотя бы две-три, то стоит запускать бор, иначе — вторым способом. Вообще, результативность того или иного метода сильно зависит от характера словаря и запросов
Кажется, я чего-то не понимаю в этой жизни((
Всё таки я думаю, в худшем случае (шаблон большой, словарь большой, его нет в словаре), это будет
Кстати, есть предположение, что если нам нужно только проверять, есть ли слово в словаре, а не искать его вхождение, то мы можем поделить n надвое, построив из строк автомат и применяя meet-in-the-middle... Заодно и память сэкономим.
нужно находить вхождения. вся суть словаря в том, что нам нужно найти статью, которая соответствует слову.
С хешами можно за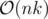 , где n — количество слов в словаре, k — количество символов "?" в шаблоне. Но, по всей видимости, это тоже
, где n — количество слов в словаре, k — количество символов "?" в шаблоне. Но, по всей видимости, это тоже  в худшем случае.
в худшем случае.
А смысл, если можно за линию от количества слов пройтись по словарю?
Именно от количества слов, а не размера словаря в символах? Как? Оо
Словарь — это не строка. Грубо говоря это массив структур с двумя полями: ключом и статьей.
Ну, ключ — строка, не? Если мы хотим сравнить хешем искомую строку и текущий ключ, нам нужно будет отдельно подправить символы, соответствующие "?" в хеше ключа, вроде.
Оу. Да, вы правы. Об этом я не подумал.
А, блин, туплю чёт, можно же восстановить то, какая именно строка подходит шаблону, а потом найти её каким-нибудь другим образом. В префиксном дереве там или по хешу. Тогда как раз должно выйти
Вы N и K случайно не перепутали?
Перепутал :)
Пардон
Что-то никто тут не написал решение, асимптотически оптимальное с точки зрения времени поиска слова в словаре.
Идея решения ровно за длину слова для коротких слов:
С длинными словами будем делать что-нибудь другое.
Я правильно понимаю, это потребует памяти и столько же времени на преподсчёт? (L — макс. допустимая длина, N — количество слов в словаре)
памяти и столько же времени на преподсчёт? (L — макс. допустимая длина, N — количество слов в словаре)
Да, примерно так.