


Доброго времени суток, codeforces)
Приглашаем вас на очередной раунд Codeforces #246 для участников Div. 2. Как всегда, участники Div. 1 могут поучаствовать в этом соревновании вне конкурса.
Задачи для вас готовили авторы Павел Холкин (HolkinPV) и Геральд Агапов (Gerald). Уже не первый и, определенно, не последний раз мы стараемся для вас. Традиционно мы говорим слова благодарности Михаилу Мирзаянову (MikeMirzayanov) за прекрасные системы Codeforces и Polygon, а также Марии Беловой (Delinur) за перевод условий задач.
UPD: Распределение баллов по задачам будет стандартным — 500-1000-1500-2000-2500.
Желаем всем участникам удачи и удовольствия от решения задач)
UPD2: Соревнование завершилось, надеемся оно вам понравилось)
UPD3: А вот и ссылка на разбор задач
Поздравляем победителей!:
1) PopovkinAndrey
2) FTD2009
3) Gulan14no
4) Kozakai_Aya
5) Mikael








А почему вы даете только Див. 2? Я видел, что вы давали довольно много контестов, и народу они нравились. Почему бы не попробовать дать и первый див? Думаю задачи выйдут хорошие.
Спасибо за доверие) див.1 тоже бывали несколько раз совместно с другими авторами, однако див.2 раундов действительно больше и их несколько проще подготовить)
Вы не можете голосовать за текст дважды.
Друзья, позволю себе пару правок:
И спасибо за раунд!
спасибо, в след раз в личку)
Have a good match again today. Applause.
I will be in for my first match!
hah, good luck and have fun!
Too bad you did not show up :D
nice picture!
Недавно была информация и про div.1 раунд, но потом ее убрали
Could you change the match time?In China ,the match time is not suitable for all china players.
I'd also like to raise similar question. This is third CodeForces round for me. Each time it was 19:30 Moscow time. Apparently when people from all around the world participate it is impossible to always choose time which is convenient for everybody. Some other platforms try to rotate timings so that different rounds are more or less convenient in different time zones.
So the question is — Does Codeforces always conduct rounds at 19:30 Moscow time? If so — will it change at some point in the future? or is it conscious decision because the platform is Russia-based? Still, even for Russian cities — like Vladivostok — 19:30 is hardly convenient.
i'm not very sure, but i think some rounds are also held at 12:00 or 13:00 MSK.
Waiting for score distribution
The contest should be presumed to take place at 7:40pm?
And ohh please, you guys can inform the informers for your dinner schedule?
Sorry but constructuve criticism.
We see everytime the contests are post-poned by several minutes.:) We request you to look into the matter.
Good luck and have fun all.
Agree!
I eat banana 3 minutes before the contest. So have to eat two bananas if it is postponed by 10 minutes :) If they ever do postpone it several times, I might not be able to participate.
is it just me, or was there a countdown for CF Round #246 (Div. 1) as well about 2 days ago (a few hours after Round #245 ended)?
yes. there was one, but later removed. :(
Please, do not get upset, it will be scheduled very soon =)
when is the next contest? the contest menu is weird isn't it? :S
kursatba324.c:2:55 Error: expected ";"
GOOD LUCK
TO everyone
Только мне кажется, что "Before contest" ("До соревнования" в английской версии сайта, справа на информационной панели) звучит не очень по-английски? Может быть, если будет возможность, поменять на "Next contest:"? Или "Time to next contest:"? или "Contest XXX starts in:"?
Работаем по старой схеме (D — C — B — A — E — взломы)
Я буду по своей обычной (A -> B -> C -> D -> E -> ой, поломали CDE -> ой, AB не прошли системное тестирование). Удачи!
По факту:
A — Done, B — Done, C — "ой, разницы должны быть простые? блин" skip, D — "вроде получилось, но правильно ли я прикрутил автомат?" E — "неужели жадность заработает?" и в результате — MIC, Missed in Coding.
А я как и обещал, Д решил...
Это мой третий раз.
Я в принципе собой доволен — впервые решил три задачи (до этого решал одну в первый раз и две во второй), впервые всё, что прошло претесты прошло и финальные тесты и это был первый раз, когда я писал контест на C++ (до этого был Python).
i'll just be there being pupil :'(
No Problem, ratings are not important What you will achieve is important ;)
like what ? :D
contest experience ans skill ;)
Спасибо за интересную задачу Е!
Увы, так и не успел решить её правильно...
Интересную? Ух ну и вкусы у людей)
Я вообще люблю динамику.
А что с ней не так?
Мне тоже буквально двух минут не хватило!
I love problem E and especially pretest 6 of it!
Задача D. Пробовал раскрутиться от z-функции строки, но либо идея фуфло, либо не успел написать нормально. Застрял на 10м претесте.
Нужен суффиксный автомат с учётом количества вхождений. Ну и z-функция для проверки. Прогоняем всю строку по автомату, на каждом шаге проверяя с помощью z-функции, подходит ли нам этот префикс.
можно проще. http://e-maxx.ru/algo/prefix_function. Раздел "Подсчёт числа вхождений каждого префикса"
Можно обойтись префикс-функцией + z-функцией.
upd. Опередили. Ну а алгоритм такой же, как и там, собственно, да.
upd2. Можно и одной префикс-функцией, что-то я конкретно протупил.
Можно и одной Z-функцией
Ага. Добил своё решение с контеста. 6637149 Торопился сдать задачу и написал нелепые условия.
У меня прошло по тестам следующее:
Пройтись по автомату с использованием стринга — т.е. по "основному" стволу, если его так можно назвать. Любое терминальное состояние, встреченное по пути — ответ.
Прошла z-функция + бин. поиск.
IMO TL For D was too strict. O(n log^2n) Suffix array solution was getting TLEd :(
Problem D is about suffix structure? I never code a suffix structure before. I just know KMP:(
Yes, I got the idea of solution after you told that it can be done by KMP. But still I was expecting that authors will keep in mind that somebody might try more complicated suffix array solutions.
But how can KMP solve this? How to get the substring which is both a prefix and a suffix?
suffix array is OK.I use it and it's just 77ms.6632223
I think it was simple dp. But maybe i am mistaken an nlogn one.
Suffix machine gives O(n) solution.
Is this the same as suffix automaton?
My O(n log^2n) Suffix array solution got AC 6626473
What does "submit already challenged" mean when I am trying to hack somebody? I am only one in room to lock problem C, so nobody else could have challenged it, but it rejected my hack attempt 5 times with this message...
What was wrong with the E problem. Isn't it just greedy. Try to put every letter (A,B,C,D,...X,Y,Z) until you can. I don't know what else could be. I have wrong answer on 7th test.
The answer should only consist of A,B and C. If your anwser has letter D or others your solution is 100% wrong.Oops I found my presumption was wrong
The main idea of the problem is greedy, while you have to check for three sides(up,left,right) when enlarging the square
The problem was one if. Just one if more and the program is running perfectly. :(
Hi, Could you please explain your solution of E?
Thanks in advance. :)
This is what I did:
1) Start on position (0,0) of the table. (You will move in this order: (0,0),(0,1),...,(0,m-1),(1,0),(1,2), ...,(n-1,m-1) ).
2) Check for neighbors and put the minimum possible letter.
3) -If this letter is "greater" than the last one, go back and make the biggest square possible with the previous letter. Then move to the next empty position, put the minimum letter and go to the next position.
-Otherwise, just move to the next position.
4) Go to step 2)
My solution 6634518.
Объясните, пожалуйста, почему это решение получает TL? Вроде бы, все за линию...
За квадрат
OK
Жесть... Спасибо, теперь буду знать. UPD: Нет, это еще не жесть была. Эту строку вообще можно было убрать.
Aww.. Really hate it when someone hacks my code with the time is almost at the end.. No more time to think the code again!!! T.T
Philosophically thinking this is almost exactly the same situation as if you just left your solution to be crashed by pretest. So take it easy.
Что за шестой претест? Чем неправильно решение "пихать квадрат наименьшего возможного цвета и максимального возможного размера и переходить к меньшей задаче"?
Или даже так:
Тьфу, точно.
upd. Кстати, сначала написал решение, которое на этот тест выдаст такой же ответ, но потом оказалось, что оно не совсем правильно работает, и переписал уже на то, что озвучил выше.
upd2. Ещё пять минут подумал и, вроде как, придумал правильное решение. Эх, вот почему нельзя на контесте побольше думать.
Вот тест вроде ломает. 30 31.
мой алгоритм такой же (и тоже падает на шестом тесте) и падает на тесте: 6 4. Выдает: AAAA AAAA AAAA AAAA BBCC BBCC , хотя две последние строки должны быть по идее BBCB BBAC
Я правильно понимаю, что нужно заполнять A наибольший возможный квадрат, ставить рядом с ним цепочку BCBC...BCB и переходить к меньшей задаче?
Why this solution is Accepted for problem C ? link
Really enjoyed this round.
Problem C is Goldbach Theory? I got WA on test 10:(
Not really Goldbach conjecture i think. It's just construct minimum prime partition of a swap-range
Yes, with this theory we can achieve at most 3n operations.
I think constraint of 3n operations is better version of this problem.
Why not 2n operations?
If you go from beginning to end, every item can be moved just once. So you need to do n operations to sort array (because this is not "real" n*log(n) sorting — this is ideal sorting, when you know all your elements beforehand).
Each move can be achieved at most in 2 operations, if difference is not prime.
Which should give 2n
EDIT: Ah, see problem when you need to move by just 1 items, you have to do two operations 3 forward and 2 backward. And you can do it only if you are not at the end of array. So there might be problem in the end.
My rating updated so fast! Thank you!
It always took more than an hour!
All Submission for Problem A fail in Final test who use sort and check 3 element in a row ,where there occurs a overflow of given data !! :P Really shocked about my bad Code :(
http://codeforces.net/contest/432/submission/6630167 What does skipped mean? I want my point... It must be accepted
Most likely this submission was not your final solution. Meaning later into the round you resent submission for this problem. When you resend submission for you problem, all previous submissions are "skipped". Seems that your new solution was wrong, while previous one was correct. Bad luck.
If this is not the case, then you probably should contact admins.
please explain how to solve problem D.
I calculated Z-function for the string s (but z[0] = n). Then I found all the prefixes coinciding with suffixes ("necessary" prefixes), i.e. stored all their lengths in set V (I mean all values of z[i] which were equal to n-i). Besides, I stored the number of occurences of each value of z[i] in a map C. Then I calculated the number of occurences for each prefix. Here is an example: let C['ab'] = x1, C['abc'] = x2, C['abcd'] = x3 ... => # of occurences of 'ab' is equal to the sum of occurences of bigger prefixes (x2 + x3 + ...) + C['ab']. We can calculate this with O(n) complexity. I also created a map M, where I stored the number of occurences of "necessary" prefixes, and outputted all its contents.
In Problem C will shell-sort with prime shuffling work? I tried but it was giving tle
problem c was simple , for each number i= 1 to n , swap the number to greatest left position such that length of swap is prime , start from (pos-i+1) search nearest prime , repeat down till its sorted position is obtained
Сразу после окончания началось тестирование, стали доступны чужие коды, разбор, и через небольшое время обновился рейтинг! Почему на других раундах нет такого?
Please someone explain idea of problem C ?? Not getting it through codes and if possible proof of complexity :( :( Please
Simply, you can follow an optimal strategy which is :
for every i from 1 to nswap the element which has the valueiwithindex j;index jis the closest element toiwhose distance to the element with valueiis a prime numberin other words you have to find the maximum prime number which is not larger than distance between the index of the element which has a value of
iandindex ibinary search is the best way in my point of view
according to Goldbach's_conjecture complexity will be at most
O(5 n log(n))here is my AC code 6629271
So basically, we're moving
ito a prime distance from it's intended position,index i, so that we can swap it in the next move. Then we do this for eachiinn?Did I get you right RetiredAmrMahmoud?
yes, you keep moving
iuntil it reachesindex iand then do the same for every
inote that you have to choose maximum prime distance possible in order to minimize number of movements
OFFTOP
Three contests number 247 are coming?! :)
someone explain the idea behind solving problem D...
I know two solutions for problem D.
The first one is based on Z-Algorithm. If you compute Z[i] — largest substring starting at the i-th position, which matches with the prefix of the same length, when you have a prefix which matches with the associated suffix, you have to count how many values of Z[] are >= the length of the current prefix.
The second one, a bit harder than the first one, is based on KMP (Prefix function) and hashing. First of all, you have to compute for each prefix and each suffix their hashcodes. If you compute Prefix[i] (from KMP) and consider a tree where edges are from Prefix[i] to i (nodes are labeled from 1 to N), you can find Nr[i] — how many times does the prefix [1..i] match with the entire string by counting how many nodes are in the subtree rooted at node i.
Here is the code which computes this:
Now, if you find a prefix which matches with the associated suffix (by comparing their hashcodes), you know the answer for that prefix :)
I used KMP. We can easily calculate, for each prefix of length i, the second longest prefix which matches it (is its suffix); its length is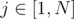 and increment each
and increment each
prev[i]. Then, we can calculate the number of timesP[i]the prefix of length i appears in the string: a bruteforce would iteratej=prev[j]starting from eachP[i]encountered, but it can be simplified by iterating i from N to 1 and addingP[i]toP[prev[i]](it basically processes all iterationsj=prev[j]at once). Counting prefixes which match a suffix is even easier: these are the ones which are iterated byj=prev[j]starting from j = N.Can you elaborate these two lines a little more? I have seen these in almost every code but cant get it how it gives me the required result. - vector P(N+1,1); - for(int i =N; i > 0; i--) P[prev[i]] +=P[i];
We know that if a prefix i ended somewhere, then so did prefix prev[i]. Mathematical induction: suppose P[j] (j > i) have been fully calculated and tell the number of times prefix j appeared in the string. Then anytime prefix i occurs as a substring string (except as that prefix itself), it'll be a suffix of some other prefix. We could iterate over all prefixes that can contain it (and no larger prefix, so that we wouldn't count occurences multiple times) as a suffix — each time such prefix occurs in the string as a substring, prefix i must also occur in it, so it's the sum of P[j]-s for which prev[j] = i. We're just calculating that in the opposite direction (imagine it as counting subtree sizes of a tree, we're not doing a DFS but cutting off leaves).
I got timeLimit in pretest9, i don't understand why, my solution is a simple Z algorithm For every string's position accumulate the largest valid prefix who is a suffix in a frecuency array then you easily know how to get all valid prefix's frecuencies, accumulate from the largest to the smallest for get all answers. If someone don't understand I can explain it better.
http://codeforces.net/contest/432/submission/6632244
Because of trivial approach in Z-function. It goes in O(n^2). Here is AC verdict for your solution with modified Z-function.
Your simple Z algorithm really runs in O (N^2), which is not fast enough to pass the time limit under the given problem constraints.
Please give editorial!
Very good problems, but unfortunately i fell down :(
Round Stats
What i want to Say is it's too unbelievable to find the System test#29 of Problem D it make the Hash which Mod 2^64(using unsigned long long) wrong..... so, my D's solution which use SuffixArray failed the system tests...:(
Here is a simple editorial for problem D.
Now we need to compute the frequency of each substring of length 'l' in the original string. Of course it needs to be both a suffix and a prefix. PS: Given The Z array it is easy to know if a substring of length 'l' is also a suffix. You need just to check is Z[N-l] >= l, with N the length of the original string.
The problem now, is how to efficiently count these frequencies. The trivial way, is to iterate over the Z array and is Z[i] >= l then we increment. Unfortunately, it is too slow.
A better way, is to sort the Z array and perform a modified binary search ( one that gives the most left occurrence of the target key ). Now some little arithmetic will give us the number Zs greater than or equal than length 'l'.
Complexity of the algorithm is O(n*logn). Since we can construct the Z array in O(n) time, and for each length 'l' we run a binary search O(logn), and finally compute the frequency in O(1) time.
Let's take the string: ABACABA. Z algorithm will give us: 7 0 1 0 3 0 1 After copying and sorting: 0 0 0 1 1 3 7
Now for length l = 1, we first check if Z[N-1] >= 1 ( which is true ), then we perform the binary search which will return index = 3 ( 0 based ). Now the magic comes, freq[1] = N-3 = 7-3 = 4. Which is the correct number.
Here's my code: 6636526
I'll be glad to explain more and sorry for any mistake.
Special thanks to Totktonada for his Z algorithm function.
We don't need binsearch actually: 6637149 And no magic, small observation: if we have substring with L length X times, we also have additional X substrings with [1; L-1] len. Too bad that i didn't write solution correctly on contest.
P.S. Sorry for my bad english.
Nice explanation. You can consider the prefix sum instead of binsearch to make it O(N)
6637312
It actually is a suffix sum. You don't need the
prefarray (if you want to optimize for space); usez[N - len] == lenas a test for "suffix that is also prefix".