


Writing an Efficient Code in Codeforces is important for a problem to be Accepted. We will compare your different code runtimes by implementing them in simple standard libraries and then implementing the same code using a buffer reader, creating the necessary String Token, and changing the int variables to Long. Then, we will understand why the Buffered one is faster than the other.
Why does Scanner take longer compared to BufferedReader and DataInputStream? The primary reason is that the Scanner reads smaller bits of information from the input stream one at a time without buffering. This means that the process of reading from the input stream, which is inherently slow, must be repeated multiple times. Each read operation involves significant overhead, making the process inefficient. In contrast, BufferedReader and DataInputStream use buffering to enhance performance. Buffered input works by reading large chunks of data from the file into a buffer in one go. The program then reads from this Buffer, significantly reducing the time it needs to access the slow input stream. Also, while directly managing buffers, I can optimize memory access patterns to suit specific needs, which reduces cache misses and memory fragmentation. Standard libraries might not be as finely tuned for the particular use case.
This method minimizes the bottleneck caused by the input stream read operations, making the overall reading process much faster. I have made two sample codes, one without implementing Buffer and token and the other being implemented using Buffer and token. Check the equivalent code, and then I will attach a screenshot of their runtime.
The below Java code iterates an input array through its length and then counts the frequency of each element in the array. For this, it uses Hashmap with keys as the distinct elements of the input array and corresponding values as the frequency of that element in the array. The spoiler below is a test of the code without any use of buffer, token, or long variable.
The time elapsed by both codes in there run time is shown below.
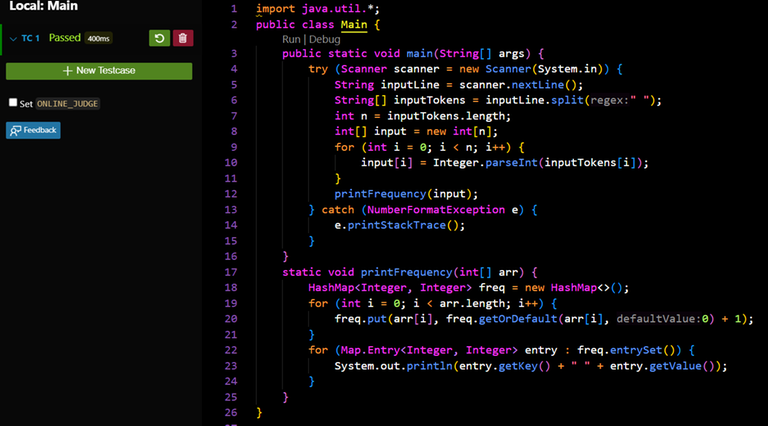
The result for the above case is that buffer was not used.
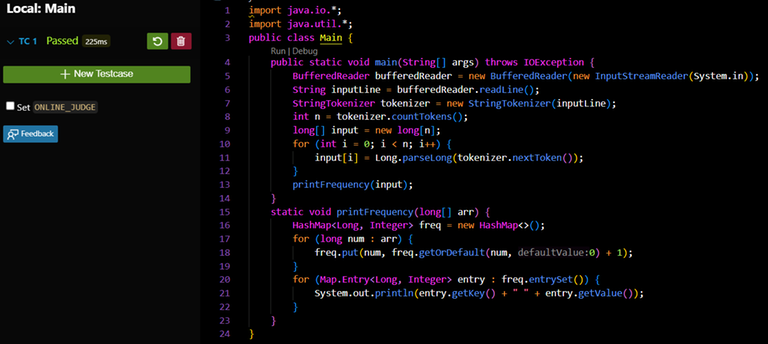
The result for the above case is that buffer was used.
For I/O, Buffer management can reduce the overhead associated with them. One can batch I/O operations using a buffer, reducing the time spent on costly I/O system calls. Higher-level abstractions in standard libraries introduce penalties in terms of performance. Direct manipulation using tokens and specific data types like long avoids these penalties by working closer to the hardware level.
For Big Code, Buffer significantly reduces the time. The reduction can go up to 3x and 4x. The image below represents the time that these two cases elapsed when handling a significantly competitive problem.

Does Using Buffer always Optimal and more comprehensive?
Buffers consume memory to store the data read from the input stream. The additional memory usage might be a concern for applications with stringent memory constraints. The buffering overhead might introduce latency for applications that frequently read small amounts of data or require immediate input processing (like real-time systems). In such cases, unbuffered reads might be more responsive.
While buffers like BufferedReader in Java are often more optimal and comprehensive, it is not a one-size-fits-all solution. The decision to use buffered input should be based on the application's specific requirements, considering factors like data size, memory constraints, latency requirements, and complexity.
References
To understand the input cases between these.
Implementing a More efficient code in Java using Buffer, Token, and Long







Auto comment: topic has been updated by Flick__ (previous revision, new revision, compare).
Interesting!