

MemSQL с радостью сообщает о проведении второго ежегодного соревнования по программированию Start[c]UP 2.0. Start[c]UP 2.0 проводится на платформе Codeforces и состоит из двух раундов.
Раунд 1 состоится онлайн 27 июля в 21:00 мск и будет проведен по стандартным правилам Codeforces. На нем будет представлено пять задач, сложность которых сопоставима со средним раундом на Codeforces, раунд является рейтинговым и длится 2.5 часа. Для участия в первом раунде допускаются все желающие.
Раунд 2 состоится одновременно онлайн и онсайт 10 августа в 21:00 мск и будет проведен по стандартным правилам Codeforces. Будет представлено шесть задач, сложность которых, по нашей оценке, превосходит средний раунд на Codeforces. Раунд является рейтинговым и длится 3 часа. Во втором раунде могут участвовать только участники, занявшие первые 500 мест в первом раунде. Лучшие 100 участников второго раунда получат футболки Start[c]UP 2.0.
Для тех из вас, кто находится географически в Кремниевой Долине, мы пригласим 25 лучших участников по итогам первого раунда на онсайт версию второго раунда. Победитель онсайт раунда получит специальный приз.
UPDATE: в первом раунде будет предложено шесть задач, а не пять, как было объявлено ранее







Note that July 26th is also the date of TCO round 3A — it'd be good to avoid collisions as early as possible.
Yes, thank you for bringing it up. Round one will actually be on Sunday, July 27th. Original post had a wrong date.
Thank you for reminding me, that today will be TCO. If it weren't for you, I would probably forget :P (not that TopCoder should do that...)
Division 1 or 2?
division 1 link
Deleted.
sorry if this seems like a stupid question, but what does the
[c]inStart[c]UPsignify?It would not be a "cUP" had it not been the "[c]".
This is rounded speed of light.
Yes, MemSQL is famous for its fast.
if we remove "[c]", we have StartUP. I don't know if it is right or wrong.
this is actually one of the things i wanted to know when i asked the question. :)
"**The top 100 in round 2 will receive a Start[c]UP 2.0 T-shirt.**" I like it :)
No unofficial participation in round 2 for those who didn't finish in top 500 in round 1?
As far as I know Codeforces allows one to participate unofficially in any round (same as division one contestant can participate in division two rounds). We will not intentionally disable this functionality.
Why do you set such strange top-500 restriction for online version of second round? For example I can't participate in first round, so you force me skip both rounds. It is very easy to reach top-500, so it is only about could you participate in the round or not.
i think this is disrespectful to the people who won't make it to the top 500
Sorry if I offended anyone. And I am sure they want officially participate in the second round too.
P.S. I changed my flight, so I can participate, but still don't understand logic of organizers. It is not gcj with huge amount of participants, and it doesn't affect onsite at all.
maybe u could add this to You know you are a programming competitions addict when ... ;)
Contest wasn't main reason =)
I'm sorry for whoever that stands in 501st place :/
so sad for veecci and poopi. they missed out by just 4 and 6 points respectively. :(
Oh, Thanks. I was very bad today, but really I prefer to be at 600th place or more instead of 502th :) It isn't nice but I'm hopeful that organizers find at least two cheater in places 1 to 501 :)
I hope I will be able to say "It is very easy to reach top-500" in the future.
I agree with the first statement of course. What's the point of the restriction of top 500? If the system can bear the load of 1st round then obviously it could bear the pressure if all are advanced so there is no point of top 500 thing from the point of system.
But according to the 3rd sentence, if It is very easy to reach top-500, so it is only about could you participate in the round or not., then all the (1200 and counting) participants/registrants will reach top 500? Oh, but pigeonhole principle must disagree.
what if 1000 participants all get same score, and all take the 500-th place? :D
maybe two pig on one hole :/
I guess main point of question was about rated participation (not like unofficial participation for div1 contestants in div2 rounds). For example, Croc Champ 2013 — Round 2 was rated event both for guys who qualified from round 1 and for those who did not; moreover, there was also Croc Champ 2013 — Round 2 (Div. 2 Edition) — rated event for div2 users.
What happens to ratings when one participates unofficially though?
I seem to recall that when VK-cup was on CF, unofficial participants still factored into the ratings pool. Will that be the case here?
Last year it was a regular CF round for all participants in terms of rating.
where can i get the competition
July 27th??!! That's the first day of NOI~~!!
Is it rated??
Yes, both rounds will be rated. I updated the post with this information.
It is said that both round will follow regular Codeforces rules, while first will last 2,5h and second 3h, I think you should mention this in an announcement.
Updated the post, thanks for bringing this up.
Note that with last two changes language versions became out of sync.
And with the very last change they are in sync again :o)
When is the final round? I wish if you can announce this as early as possible. I live near to San Francisco, and I was invited to the final last year but I couldn't make it because I was outside the US at the contest's time.
Round 2 is a final. And it's on 10th of August
Thanks! Sorry, I missed that.
So late in such countries as China or Japan... The previous rounds are interesting. What a pity!:(
OMG! It is 1 a.m. Monday in China...:D end at 3:30... rating updated at about 4... then go to bed... And at 7 a.m I should go to the railway station and go to school. The train will cost me 8 hours... Monday is too busy for me to have a rest! Amazing Monday!
Are you kidding? It's summer now — who's studying in July?
But according to my parents' opinion, if I want to grow taller, I should go to bed early... T_T
you can go to bed 2 hours earlier than usual, that means your sleep time of a whole day is the same.
And when I fall asleep the clock will wake me up... Anyway it is an acceptable idea:)
Because I feel boring staying at home in summer holiday. And at home I must cook dinner for myself owing to my parents always not coming back home for dinner. After friends and classmates of middle school meeting, I have nothing to do but training coding skills. Home is not a good place to train. I think I would better go to school.
I don't know about China, but it's not so unusual that we still have class in July in Japan. My friends in Japan are now taking the final exams! (In Japan, school starts in April, and the first semester often ends in July.)
I catched math big god wow!
Oh No~ 10:00AM PST, 1:00AM BEIJING
Yes ~(T.T)~~ and 7 p.m ~ 9 p.m.in Beijing Sunday,is the bestcoder round#2...in hdu
Hey, are you both from China?
Yep... there are a lot of Chinese acmers in Codeforces~
I'm from China, too.
I guess too~, People's Republic of China Jiang Su Wang Tianyi...Nice to meet you~are you a middle school student? Or a university student?
Middle school, Nanjing Foreign Languages School.
aha, so you are a noiper~
Me too~I'll study in Nanjing Foreign Languages School soon~
I am luckier a little.
Всем привет, я начинающий спортивный программист. подскажите пожалуйста в чем ошибка. уже два чиса мучаюсь.
Привет, напиши пожалуйста задание, и залей исходник например на ideone P.S. твоё сообщение не относится к теме статьи
Если бы код нормально выровнял, то увидел бы, что кол-во фигурных скобочек в твоей программе нечетно.
What is the programming language I can use in this competion?
Any language CodeForces supports.
According to codeforces rules the list of supported languages is:
Wow I have always wanted a Start[c]UP 2.0 t-shirt! Very intriguing prize! Good luck to all participants as I am at camp and will not be able to participate.
the complexity of the problems will be comparable to a regular Codeforces roundRegular Div1 or regular Div2?
I tried to register for the MemSQL constest but I got an exception "The contest does not allow self registration". Can anyone register me?
I believe it is fixed now
Registration is running, but it's "Private Registration" !!! What's going on!?!??! :D
When I try to register it says — "The contest does not allow self registrations".
Edit: Thanks, it is fixed.
Пацаны, а как же ДК Ворскла?
думаешь в топ-500 не пройдут?
Что? В смысле? Не понял.
Неужели тут нет поклонников украинского футбола?
Лол, я тут пытался спросить про ситуацию в мире -48:) Это сайт для прогеров а не для любителей футбола:)
Can people in div 2 participate in this contest and be qualified for round 2 if they come in top 500 ??
Yes, division does not matter for this event.
Раунд будет рейтинговым для обоих дивизионов?
Just noticed that logo of memsql is very similar to that of Mumbai Indians, one of the Indian Premier League teams.
Is this for DiV 1 or DiV 2 ?
"There are no eligibility restrictions to participate in the round". It is open to both the divisions.
I meant it difficult hardly for div2. I think.
if you think that it will be hard for you. you can not write it.
We believe that participants from Div2 will still enjoy the round.
Thanks for morale boosting :D
seriously? sir! :(
I believed the same, before the contest.
That means you qualified for the second round. If that's really the case truly- Great spirits and congrats :).
I used the word "before", not "after".
we are muslims we will be having breakfast as it is the last day in holy Ramadan :) 27th
Yeah , this contest will start exactly at our iftar time in Syria. however , I still want to participate.
BTW, happy feast tomorrow to you and all muslims!
The contest will be rated for both div1 and div2 participants?
Yes it would be rated for both .
ВКонтакте недоступен, видимо, его разработчики тоже хотят футболки :)
Нет, просто контакт перестал поддерживать КФ и теперь обречен на нестабильную работу...
КФ покусал ВК?
мог бы и покусать. нечего нас обижать!
Anyone can tell score of problems?
This contest start at the same time of (Iftar)
It will add another 2.5 hour to 16 hour without eating :D :D
I'll do the same :'D this must be added to "You know you are a competitive programmer when .." :D
I don't think will have ocasion to continue with round 2
contest is not simple !
На чем ломали B? И как решать С?
У меня сломали B на не разобранном отдельно случае Y == 0.
С http://pastebin.com/8XiqfxpL прошло претесты, идею могу объяснить, но еще нет вердикта финального тестирования.
Ну еще бывает n=1=m, а так правильно
Эх, первое решение было другое, на нем все это тестил, на втором ощущение протестированности осталось( Спасибо.
А чем плохо решение вида посчитать, сколько комбинаций с K нужными картами, поделить на количество комбинаций с хотя бы одной нужной картой, умножить на K/M и прибавить к ответу? То есть оно выдаёт неправильный ответ на 4 4, например, но я не понимаю, почему.
http://codeforces.net/contest/452/submission/7274849
Решил чем-то схожим с описанием выше.
Ну суть казалось бы очевидна. Пусть выбрана карта X. Вероятность того, что в выбранных n картах, есть i карт, таких что, их тип совпадает с картой X равна .
.
Правда, во время контеста рассуждал несколько иначе, и почему-то тоже выдавался неправильный ответ на тест 4 4. Считал ту же самую вероятность но по иной формуле.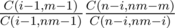
P.S. Буду благодарен, если кто-нибудь объяснит, почему последняя формула неверна. Казалось бы, это обычное выражение вероятности появления двух событий, через условную вероятность (второй множитель).
Горе мне, я неправильно прочитал условие и подумал, что выбирается одна карта из каждой колоды. Что же, спасибо за объяснение!
В В ломали на тесте 2 2
Какой ответ на этот тест?
Конвертик, 2 диагонали и длинная сторона
Ну у меня один взлом — человек думал, что всегда выгодно делать 3 линии около 1 диагонали, а на самом деле иногда (2 1000) нужно сделать "конверт" (2 диагонали + сторона)
Удивительная задача. Ведь не нужно было даже думать, чтобы ее решить. Очевидно предполагаем, что точки должны быть распиханы по углам прямоугольника. Берем несколько точек из окресностей углов. Потом за O(k^4) ищем ответ
How was problem C to be solved?
How to solve problems B, C, D, E, F ?
For B, most probably the zig zag pattern made by (0,1) (n,m) (0,0) and (n,m-1) was the 4th one to be checked. The other 3 were only X-axis, only Y-axis and the 2 diagonal-one maximum side pattern. This passed pretests. Not sure though. System tests would tell us better. --- Nope, failed systests -- The method is right. Mine failed because of a typo :P
На чем ломали А, неужели кто-то читал эти странные длинные переборы?
6 ..p... или 8 ..p..... (в зависимости от решения).
Некоторые не обращали внимания на длину имени.
Pretests were very weak again!
Lots of solutions on B, C, D will fail.........:SS
I see this as good thing. I love to hack! :D
Can somebody please explain D
Contest finished! But personally, I didn't like the idea of putting the arrays of names in problem A in sample test explanation place; because I think many people (including myself) do not check the explanation when they understand the statement. Maybe it was better if they were higher.
Cmon, place your bets! Who thinks this solution will pass the final tests? Hurry up!
7269849
Not allowed to view the submission yet.
I got a kind of stupid solution at B and got hacked. I passed the hack 3 seconds before end of constest. :)) I hope it passed.
Edit: It passed. :)) Thanks to the hacker.
I scared I will get down rating !
Как решать E без суффиксного дерева?
Можно с суффиксным автоматом, например :)
суффиксным автоматом :)
Просто суффиксным автоматом. Строим суффиксный автомат для S1#S2$S3. В каждой вершине будем держать три числа a1, a2 и a3 — количество вхождений данного состояния в каждую из трёх строк. Прогоним S1, S2 и S3 по автомату, инкрементируя соответствующие счётчики.
Но это ещё не всё: мы пока только инкрементировали в состояниях, соответствующих префиксам S1, S2 и S3, а подстрок у этих строк больше. Поэтому надо распихать эти добавки по суффиксным ссылкам. Суффиксные ссылки образуют дерево, обходим его DFS'ом, прибавляем к числам a1, a2, a3 в вершине числа из её сыновей.
Теперь каждая вершина прибавляет к ответам на отрезке длин [suf->len + 1, len] произведение a1 * a2 * a3. Можно в оффлайне поприбавлять все ответы, получится решение за O(N).
У меня была идея использовать суфмасс, но не смог довести до ума, сдал суфавтомат. Потом мб додумаю и расскажу.
Я суфф. массом решал.
Как-то просто совсем получилось:
А я делал наоборот. Итерировался от меньших к большим, разрезал отрезки и поддерживал ответ.
Is there any particularly tricky corner case for problem B?
I see many successful hacks, but I can't come up with any special case.
Running java programs with -Xmx512m and ML 256m is evil. I've spent most of the contest trying to make sure that my E fits in ML regardless of GC behavior :(
Why not use "Off heap" memory? No GC, smaller memory footprint.
I don't know much about off-heap memory, but I actually need GC functionality. The problem is as follows. With an implementation of suffix trees which I use (nice, readable and object-oriented, not the horror from e-maxx), total memory which is really used is pretty close to ML. Since there is Xmx512m option, theoretically nothing prevents java from growing it (by a constant factor) above ML (it thinks that it has 512m available, so it can decide to allocate a bit more in advance).
So I decided to use an optimization: instead of Node[alphabetSize] store list of pairs (char, Node) until it grows to some constant, and then free it and use full-sized array. However, my calculations show that if GC does not reuse the memory which was freed, theoretically it is again possible to go dangerously close to ML (on logarithmic scale).
Anyway experiments show that even my first submission passes all tests with "memory used" 188400 Kb. Maybe I'm overly paranoid, but I want my solution to be guaranteed to pass, not just pass by luck. And IMO setting "Xmx" to match actual ML would be a very good idea.
contest really hard, hard and very hard (with me)
Как D нужно было решать? Написал решение "в лоб", упадёт на тестировании скорее всего.
UPD: Упало на тестировании.
В трёх очередях храним времена освобождения приборов. Перебираем предметы и для каждого предмета извлекаем из очередей три прибора с наименьшим временем освобождения, вычисляем время, когда надо запустить предмет, и заносим в очереди новое время освобождения.
Difficulty of problems, my impression:
A,B — div2 A
C,D — div1 B (I find D easier than C)
E,F — div1 D-E
Yet another situation (after Zepto Code Rush) where the problems are split into easy and hard ones, and time is the main tiebreaker on the easy ones. Although I don't know how many pretests there are, so I can fail on any of B,C,D during the systest.
I can write it in bold caps: MY IMPRESSION. Also, before systest.
What was the approach for problem B ?
I can't believe it -.-
I got AC after contest ended. Two lines of code and it was fixed!
There is a little 'hack' that I like to use. Watch others submissions AC's and how much system resources they use... When I saw some solutions using a lot of memory then I figured out it MIGHT not be an easy one line solution.
My approach: Fix two points (0,0) and (n,m). You can see that it must be included in the optimal solution. Then you have two points to select among 4000. It's not wise to choose a point inside the rectangle... So choose two distinct points that lies in the border (that's up to 4000 points!). So you can run O(4000^2) to pick those points. For each set of 4 points you still have to select the best order, that is, assing p1, p2, p3, and p4 and compute the length. Pick the best, and you are done! (m==0 || n==0 you can solve by hand)
F is far from div1 E and... how to solve B -_-?
I just tried all the possible 4-tuples of what I considered "important points". This passed pretests. I hope also system tests (((
7262613
saw a lot of hacks to B, so doubt it's div2 A level
I find C easier than B.
How did you solve C?
Well, this formula
1/n + (n - 1)/n * (m - 1)/(mn-1)is a solution.I need explanation !
Well, There two possibilities to get the same card. 1) One card was chosen twice. Probability here is 1/n 2) Different cards were choosen. Probability of that is (n — 1)/n. Let's see on all cards that was not chosen first time, All they ahve the same probability to be chosen. There are m — 1 out of mn — 1 cards that equal to first one.
magic..
Found the same formula but didn't check when n=m=1...and got a WA
B = Div2 A? Nice joke :)
First, I wrote this before systest. Second, it's B. Third, there were a LOT of passed pretests, and there are still a lot of passed systests.
Right now, I'd say that B is div(-1) stupidproblemIdontwanttocompete.
Your comment is just as biased as mine.
Did I miss any announcement of some special prize that will be served if this guy (Xellos) gets a certain number of down vote? A man with +122 contribution to this community is getting down vote even without using slang, or native language! Come on, he just shared his feelings with you guys. Anyway I "donate" my +23 contribution to you,down voters . Please take it!
For me, B and C were much harder than E.
I didn't really try to solve them, and this was before systest. As I wrote, "my impression".
Sorry, but stupid bruteforce + obvious combinatorics can't be harder for noone than some fancy algorithm on LCP xd.
Obvious combinatorics is not that obvious for some people(like me =)). And no fancy algorithm on LCP is actually required in E, there is a well-known solution with suffix automaton for these type of string problems which is simple to understand and implement if you have seen it before.
Did you say harder? If it's true I couldn't understand your reply.
Lol, of course :D. Thanks for pointing that out :P.
You're welcome :)
Just take a look at performance of kb.:)
B can not be compared to any div2 A. You can see number of Submitted Solutions and number of Passed Solutions.
You failed div2 A systest :)
Nothing unusual for any problem with weak pretests, a lot of special cases, and considering I'm the one solving. Nearly everyone I see in my Friends tab failed B, even, so the last part can probably be extended.
I can write it in bold caps for you, too: MY IMPRESSION.
Your impression is wrong.
Your head is wrong, see this comment.
You try too hard.
I see nothing wrong with trying to find where I made a mistake, and neither with having opinions.
But I try too hard at anything, it's better than the opposite extreme :D
Как решать F?
Идём по числам слева направо, держим строку
inдлины N, где стоят единички в позициях, соответствующих значениям уже встреченных чисел.Что значит, что текущее число
xявляется(a + b) / 2для каких-тоaиbпо разные стороны от него? Это значит, что есть a и b на одинаковом расстоянии отx, такие, чтоin[a] != in[b]. А это значит, что строка максимальной длины с центром вxне является палиндромом. Значит, осталось идти слева направо и поддерживать, например, в дереве отрезков, хеши для прямой строки и обратной. В каждой позиции делаем запрос, проверяя, палиндром ли строка в текущей позиции.Для примера
5
1 5 2 4 3
Строками in будут являться следующие?
10000
10001
11001
11011
11111
Да.
Соответственно, в момент, когда мы добавили двоечку (строка: 11001), подстрока с центром во второй позиции (110) не является палиндромом. Палиндромность ломается в первой и третьей позиции, это как раз и значит, что троечка и единичка находятся по разные стороны от двоечки, что и нужно.
Для немного неочевидно, почему это работает.
Для примера
6
1 5 2 6 4 3
разве подстроки in не будут такими?
()
(010)
(110)
()
(10111)
(11111)
Вроде получается, что палиндромность ломается, но прогрессии нет.
1 5 2 6 4 3
Спасибо, теперь понял!!! Мне почему-то показалось, что (a + b) / 2 должно лежать ровно посередине...
Yeah ! I accepted only once problems A
why my solution for problem A skipped?
mb you cheated at contest? I you not, you can ask to MikeMirzayanov
I didn't cheat in contest!
If you submit a problem multiple times, only the last one will be judged. The rest will be skipped.
very fast system testing! :)
thank you very much! :)
congratulations sevenkplus !
yeah , he got 7k+ points... :)
Wow very fast systest (considering this is a special round with a lot of participants).
Anyway, why problem C has the same point as B? I think problem C is much harder....
It's just depend on the participant if it's harder or not. For those who likes such problems as me it was easier than B. So equal points is quite a good idea.
Answer to C: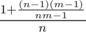 (n = m = 1 is a special case). Doesn't look very hard.
(n = m = 1 is a special case). Doesn't look very hard.
Ah I miss this simple solution. No wonder....
Anyway, this euphoria is over. I think I will back to yellow :'(
Can you explain how you obtained that expression?
I considered two cases. The first case is when Alex chooses exactly the same card as you do. The probability of this is . Otherwise, you and Alex choose two different cards, and any pair of different cards is equiprobable (so, the fact that they are chosen from a random subset of size n is irrelevant). In this case, the total number of choices is
. Otherwise, you and Alex choose two different cards, and any pair of different cards is equiprobable (so, the fact that they are chosen from a random subset of size n is irrelevant). In this case, the total number of choices is 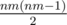 , and the number of choices that result in the cards being of the same type is
, and the number of choices that result in the cards being of the same type is 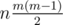 . By properly combining all these numbers, you get the answer.
. By properly combining all these numbers, you get the answer.
nvm, got it.
how do you reach this formula ?
here it's explained by another guy
Will you be providing the editorial?
Sorry, I didn't like any of problems from A to D at all, can't say anythig about E and F though. And seriously, how is D being D? It is much much easier than B and C!
Agree that any of problems A-D was interesting at all...
My answer is correct for problem B, pretest 1, submission #7269214
But verdict is
A possible reason is that you output newline as
'\n'rather thanendl. Remember that test machines are running Windows, which uses"\r\n"as line separator.I have always used '\n', never had this error before.
I don't think that's a problem. When you print '\n' it automatically converted to '#13#10'
Your output is empty. And you've shown the right answer
Ah, yes. How stupid of me! But the reason I got confused is because my compiler was producing correct output. I found the problem to be compiler specific, in my machine the code outputs different but correct answer:
My compiler info:
I used direct comparison between doubles (a == b), which failed in judge compiler.
I changed double in your solution to long double and it got AC
First of all , problems were awsome. B was harder than expected and D and E were interesting. C was maths , but I liked it.
On the other side , I think the pretests at C were weak. I put m instead of n in one place ( in a for ) and because of that it didn't passed. I think that pretests are made for this kind of situations.
Thank you for tasks E and F. Looking forward to reading the solutions to those.
I didn't like the rest of the tasks though. A and B were "let's see who forgets to code one if". Disliking C is my personal opinion — but I heavily dislike N <= 1000 when there is O(1) solution. As for D, I only have to say that I haven't even read the part "Moreover, after a piece of laundry is washed, it needs to be immediately moved into a drying machine, and after it is dried, it needs to be immediately moved into a folding machine", and my "solution" still was accepted.
A: A is to guarantee that most contestants get at least one AC.
B: Apparently B has a better solution than a bunch of if's.
D: Perhaps the two problems have exactly the same answer. Who knows? Can you construct a counterexample?
about D: I think he meant that it was not reasonable to include it to the statement at all.
D: No, I can't. If there is an easier approach, which can be written by accident or in wrong belief that it's the correct one; then it's authors' job to differentiate two approaches. If they haven't foreseen this approach, well, it happens sometimes. Still doesn't make it a good task. If they have known about this solution (but just couldn't find a counter-example), then this task shouldn't even be given, or that extra text should have been removed and the task should be given with less points.
The problems are equivalent I think. There is no difference between having a piece of laundry wait before it goes into the first dryer or having it wait in between consecutive dryers.
In my honest opinion, not having the restrictions hint to the complexity of the solution adds to the difficulty of the problem. I couldn't figure out problem C for some reason. But I bet I would have had better chances if the author had written N <= 10^9. Then, my brain would have been focused on finding a formula, not all over the place thinking about DPs and such.
I did it with DP in O(N^2), so I think it whould have been harder with a formula. ( maybe worth more points )
Well, If you code ifs in A or B they solved their task to diferrentiate people who will write and debug tons of ifs and those who will write 5-lines solutions where one can't have bug.
Самотроллинг=)
Похоже, что синдром задачи D снова разразился с новой силой. Абсолютно дебильная задача безо всякой идеи получает баллов больше, чем тервер и геома с частными случаями. Можно только порадоваться за тех, кто начинает читать с задачи D. Авторам рекомендую проверять как-нибудь, стоит ли задача своих баллов. Вот такой код 7267906 для задачи D — это просто смешно. Поймал багу в B — и пошел глубоко вниз, потому что задачу D даже собака сдать может.
А так, если расставить баллы за задачи по-другому, то вполне себе хороший набор задач. Спасибо авторам.
Еще более простой код: 7271703 P.S. Я сам еще не умею писать динамики, но посмотрев твоё решение, разобрался, как тут можно было поступить =)
Problems were very interesting...!! Thanks to authors... Nice contest...!!!
Мало кто знает, но боль выглядит именно так sqrt((double)n*n+(m-1)*m-1)
How to create a good test for problem F?
I accepted the following flawed solution consisting of two steps.
A naive approach would be: for each number
xin the permutation, for all possible deltasy, check whetherx - yandx + yare on different sides of thex. A partial solution is to check only theMAXfirst andMAXlast values ofyin this approach. In my solution,MAX = 60.Another naive approach reduced to a partial solution is: for each position
tin the permutation, look at values at positionssfromt - MAXtot + MAX, check ifp[t]is betweenp[s]and2*p[t] - p[s]. Again,MAX = 60.Looks like random test with only one valid pair
(a, b)as an answer would make this solution fail with a good probability. So, is it possible to create such a test? If it is possible, how to do it?Test with only one valid pair can be constructed in this way. If you know a permutation p1...pn which has no valid pair then 2*p1-1,...,2*pn-1, 2*p1,...,2*pn will also have no valid pair for example 1 9 5 13 3 11 7 15 2 10 6 14 4 12 8 16 . Now if you will move for example leftmost even number to the left of the rightmost odd less than n/2 then you will have one valid pair in the example 1 9 5 13 3 11 2 7 15 10 6 14 4 12 8 16
In general, if you take a permutation without valid pairs and swap two adjacent elements, you would get at most two such pairs. And with a good probability, you get only one.
Thank you, this construction seems to do the trick.
By the way, the problem's test set catches me if I try using only the first part of the solution above, but lets me pass if I use only the second one.
While the test you provided is what I literally asked, it does not break the second partial solution. In your example, 2 and 7 end up being too close. If we move 2 further to the left, more valid pairs will appear, such as 2 4 with 3 between them. Similarly, moving 7 further to the right soon produces the pair 13 7 with 10 between them. The problem seems to persist if we build a larger example following the same procedure.
So, how to break that partial solution, too? It would help to insert some "garbage" between 2 and 7 in the example, but we don't have any "garbage" left if we follow the procedure.
Look at this permutation a = { 1 5 2 6 3 8 7 4 }. For each pair (i,j) index of (a[i]+a[j])/2 is not i+1 and is not j-1. This means that in each valid triple no two are adjacent. Valid triples are 1 2 3 , 5 6 7, 2 3 4. Now consider we have the permutation [1 9][5 13][3 11][7 15][2 10][6 14][4 12][8 16] in each bracket the numbers give the same remainder when divided by 8. Now replace in permutation a[] whith this brackets according to their remainder. You will get [1 9][5 13][2 10][6 14][3 11][8 16][7 15][4 12] in this permutation the valid pairs can be only with the same remainders as in permutation a[]. i.e. from group [1 9]-[2 10]-[3 11] can be choosen respectively triples and each member of the triple can be from its respective group for example 9 10 11 are choosen from the first second and third brackets. Now imagine you have constructed a big permutation as before and replaced all brackets according to their place in a[] then in each valid triple members will be far from each other because in a[] in each triple the distance of each two is at least 2.
I enjoyed problem C very much as it has a very small and smart solution. And I am really eager to know how B can be solved without the use of more than 6 or 7 if. I can't solve B but any solution i see use more than 10 if !
7271199 — here, i solved it (in practice) using eight
if.My solution:
n/m = 0 how to handle is given in the test case n,m>0:
looks like only four cases
sol: http://codeforces.net/contest/452/submission/7267559 7 ifs with two from predefined functions
i think when
(n>0)and(m>0)we only need to compare 2 of them.if
n>m, the first way is obviously longer than the second, and the fourth is longer than the third. so we only need to consider the 1st and the 4th.if
n<=m, we only need to compare the 2nd and the 3rd.my code:7273175
Like this.
This version of my solution is a bit messy! I'll rewrite it to be a bit easier to read.
--ignore--
what about this one? :D
How about using brute forces, we can search (0,0) (0,1) (1,0) (1,1) (0,m) (n,0) (n-1,m) (n,m-1) (n-1,m-1) by dfs.
In problem A I failed this test case 6 ......
but I assumed that there must be at least one letter in the input from the problem's statement "you already know some letters" and "fits the length and the letters given"
I had thought accepted problems F with randomize (YES or NO)
You should really improve on your English, I cannot understand most of your comment!
Thanks you note me
You should really improve on your English, you cannot understand most of my comment!
comments*
you're so predictable
I now see why I failed B. One line that I forgot to remove from an older solution:
if(N > M) swap(N,M);. I got AC after removing it. (submission during the contest: 7262088, after the contest: 7271312)Therefore, my opinion that it's div2 A level holds.
My solution was: we either use the strategy from sample 1 (diagonal, vertical/horizontal line, diagonal) or the first obvious greedy (longest non-diagonal starting in a corner, diagonal, longest non-diagonal starting in the other corner). Special cases N = 0 or M = 0.
Pretests on B were very weak.
I failed B because I mistyped the points for one "case", yet I still passed the pretests.
When will the contest be rated usually in codeforces?
Why is rating update taking so long?
I always wonder why system test is faster than rating update!
Generally the rating the updated with in half an hour of the system testing, but today i don't know what is it that they are taking so much time.
Country wise rankings for this contest has been updated. (link)
thanks! feels so good to see myself topping my country, Alhamdulillah! :D
Alhamdulillah :)
I think you deserve it sister. Your performance in CodeChef is also same as far I noticed! Congratulations! :)
A: "кроме того, вам уже известны некоторые буквы"; "...строчная латинская буква (если соответствующая буква известна),". Правалиал на Теcте 9: "6 ......". Можно ли считать такой тест коректным......
слово состоящее из шести букв есть только одно — espeon.
Я про то, что тест противоречит написаному в описании задачи.
Он ничему не противоречит. Некоторые можно понимать, как "некоторое множество". Множество может быть пустым.
"для некоторого" — http://ru.wikipedia.org/wiki/%D0%9A%D0%B2%D0%B0%D0%BD%D1%82%D0%BE%D1%80_%D1%81%D1%83%D1%89%D0%B5%D1%81%D1%82%D0%B2%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F
Из того же источника "некоторый"="какой-то, точно не определённый". Если брать вторую трактовку, то все верно. А про квантор. То, что квантор читается, как эти слова, не означает, что эти слова читаются, как этот квантор. Стоит учитывать, что у слов может быть несколько значений.
вот ссылка. http://ru.wiktionary.org/wiki/%D0%BD%D0%B5%D0%BA%D0%BE%D1%82%D0%BE%D1%80%D1%8B%D0%B9 Я не совсем понял вопрос "а где "некоторый" употребляеться другим, т.е. N\0 значением?". Можете перефразировать?
Имел в виду множество {0,1,2,...}
Тогда вы неверно выразились, сказав N \ {0}, потому что ваша запись обозначает разность множеств, а не их объединение
Согласен. Имел в виду символ \ , как субскрипт знака 0. эмм..
А пример я сейчас, с ходу привести не могу, но, в любом случае, трактовка "некоторый"="точно не определенный" корректна для данной задачи. А в случае двоякого понимания условий стоит задавать вопрос.
"не определенный" говорит о том, что неизвесно какой именно элемент (1-ый?, 4-ый?, ...) множества, а "какой-то, " — квантифицирует. Если кванифицирует иначе, чем написано в статейке "Квантор существования", было бы интересно посмотреть источник.
В кросворде неможет быть неразгадонного одного слова, у которого неизвесна ни одна буква. И кроссворд — это минимум одно пересечение, т.е. минимум два слова.
Вот представьте. Вы разгадываете кроссворд, в котором еще ни одно слово не разгадано. Вот там имеются слова, в котором нету ни одной буквы.
(условие)
Из википедии: "Кроссворд, как и многие игры, не имеет строгих правил и жёстких ограничений". Что мешает тому, что весь кроссворд состоит из одного слова?. Или тому, что наше слово не имеет пересечений с остальными. Но да, прошлый комментарий я написал, не прочитав условие :)
Ну то, что кросворды из хотябы 1 пересечения, это минимум, а жестких ограничений нету по тому как они распологаються, иначе библия тоже кросворд.
"не имеет строгих правил и жёстких ограничений". Еще раз цитирую. А Вы пытаетесь их навязать. Библия не является кроссвордом, потому что она не является головоломкой, которую следует заполнять словами.
"... не является кроссвордом, потому что ..." — С чего бы это? Прочитайте свою цитату: "не имеет строгих правил и жёстких ограничений"
Потому что то, что я написал выше -- это правила составления кроссворда, а не лексическое значение слова. В лексическом значении этого слова присутствует слово "головоломка"
Может ли считатся, что я взял кросворд из 1 слова и почти его решил — неразгодал ни одного слова?
Ну тут надо переписовать понятие слова "слово". А позже я согласен с тем, что кросворд может быть из 1 слова, если оно пересекаеться само с собой, например "espeon".
When will Ratings be updated ?
waiting for the editorial :)
Ratings are updated!
Oh! At last having the test of being purple for the first time! Alhamdulillah. :)
Still Div1!
I'm surprised that I added rating. I decided two tasks are not particularly slowly. (Google Translate).
В задаче F проходил квадрат с отсечением по времени. Это из-за того, что нельзя создать анти-тест или это недочет авторов?
Let's go to next round!
I solved F using pretty weird observation:
If answer is NO, then parities of elements in our sequence look sth like:
0000000000010001111111111111 / 1111111111100110000000000.
I mean, almost all odd numbers are before almost all even numbers or the other way around. Some inversion are possible, but only a small amount of them. Does anyone can provide appropriate bound for numer of those inversions? I bruteforced small cases and for n=10, there were at most 4 inversion, for n=13 at most 6, so I assumed that n + 10 is a safe bound and it passed. I checked manually whether those inversions are a part of a bad triple and later call recursively for odd and for even numbers which resulted in a O(n log n) solution. But I still don't know why it is correct :P.
Unfortunately I got one integer overflow in my solution and it wasn't accepted :(. After adding "1ll * " it passed ;/.
During contest I found a paper that said that if n>11 then the parity of the first floor(n/2)-6 was the same and the parity of the last floor(n/2)-6 was also the same. However, I didn't come up with your solution; nice one!
Edit: paper
Why those papers are always so long :(? How have you managed to prove that observation? I don't feel like reading those 15 pages xd.
I actually just skimmed the paper to see if I could find ideas for a probabilistic algorithm. Without having read it in detail it seemed to me that a great part of those 15 pages were devoted to prove this, so I think it mustn't be easy to prove. One think that bothers me though is that if I understand the theorem correctly the correct structure would be more similar to: 00000000000/11111111111 or 1111111111/00000000000 since we can't have 0s at both sides (we would have 2*(n/2-6)>n/2) though this is not true for n<24
Would your algorithm still work with this 'structure'?
Um, sorry, I somehow understood that you proved that observation, but you wrote that you found it on a paper :P.
And that sign "/" was meant to be "or". Those were 2 separate sequences :P.
We both read each other's comment wrong then!
It all makes sense now :)
Round Stats
please anyone explain how to solve D?
Straight forward implementation.
We will simulate the process second by second.
For each machine, keep a list of pieces inside the machine right now and for each piece save its entrance time.
Every second, remove from
machine(3)the pieces whoseentrance_time + t3==current_time. Do the same formachine(2)moving pieces tomachine(3). Same formachine(1)Now at the end of each second, try to put as much new pieces in
machine(1)as possible.You need to check that there is an empty place in
machine(1)right now and that there will be an empty place inmachine(2)aftercurrent_time+t1and inmachine(3)aftercurrent_time+t1+t2.Need to find a time when every thing is finished.
Thing can start washing (drying or ironing) if the machine is free.
That is if
i - n[j] >= 0thenT[i](beginning the process) =max( T[i - n[j]], T[i] )elseT[i],jis number process,iis number thing.End process is
T[i] = max( T[i - n[j]], T[i] ) + t[j]orT[i] += t[j].Necessary to calculate the time after completion of each process. Answer is
T[k].Source code: 7271703.
I'm waiting for the editorial,it's so sad that I couldn't solve any problem last night TAT
I'm sorry to ask this, but when the editorial will be published? Since i'm a newbie in competitive programming i can't understand most of the problems. It would be very helpful for people like me if you publish an editorial on the contest. Thanks in advance :)
А разборы где?
Это официальные соревнования и, по-видимому, на них разбор задач появляется не сразу. Или же авторы просто забыли.
Contestant thank you for good contest.
Can we expect an editorial here?
In problem C, Some of the tops I see have used something like a log table. Can someone explain what log array has to do with this?
I had logs in my solution, just to prevent floating-point overflow. I was handling probabilities by counting the number of ways of choosing cards under certain conditions, and dividing at the end by ALL the possible ways. But these numbers (1000000! / 999000!) are far too large for doubles. So I worked with their logs instead. You don't lose too much precision.
Since every binomial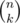 in the solution has k ≤ 1000, another trick is to multiply and divide at the same time at most k times:
in the solution has k ≤ 1000, another trick is to multiply and divide at the same time at most k times:
I used the formula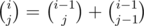 , and it worked in this task as well:
, and it worked in this task as well:
I'll take a look at your solution, it is something interesting) You need just C(n,n) — while naive combinatorical one uses C(n*m,n) (number of ways to generate deck and other stuff like that), which is too much for Pascal's triangle.
Or could you please explain it by yourself? :)
I calculate for k = 1, 2, ..., n the probability that the first chosen card appears exactly k times in the final deck and the first chosen card matches the second chosen card. The sum of these probabilities is the answer for the problem.
Thanks for asking this, I didn't notice the other method that uses larger binomial coefficients. :)
@Mike Mirzayanov i have submitted my code for Problem A : Eevee during contest and it was accepted after the contest i saw in the Verdict tab writes skipped and my submisson have no score then i send again the same code after contest and it was accepted :( why this happens?
Maybe you cheated :P
can I expect editorials!
http://main.edu.pl/pl/archive/ilocamp/2011/art — here you can submit F in a version when you have to count number of those pairs, not just state whether it's 0 or more :P.
It is also said that you can assume that the result will never exceed 1,000,000. I think it is quite important.
I was thinking about counting number of the pairs faster than in O(number number of them * log^2), but didn't manage to find a solution. Not sure if it is possible.
Hmm, I believe my solution can be extended to count them in O((N + #pairs) * log(N)), but it's quite tricky, I'm kind of "cheating" using polynomial hashing, and that's not much of an improvement. :)
Yes, my solution is also tricking around polynomial hashing (using binary search and information about previous differing characters positions to determine next one), but it has log^2 factor due to segment tree using.
It's an interesting question how to avoid quadratic #pairs factor.
It sounds like we have the same algorithm. But it looks like I was mistaken. I thought I could avoid a log factor using amortized constant-time segment tree queries, but that requires making O(N) queries, whereas we're only doing O(log N) queries. So the log^2 factor won't go away. D'oh!
My solution ( http://codeforces.net/blog/entry/13095#comment-180008 ) clearly can be extended to counting by generating all inversion and checking them all, but I don't know how to properly estimate complexity. For F mentioned paper states sth which implies that if there are >36 inversions, then there is at least one good pair (a, b). Maybe there is a constant such that if there are > M * k inversion then there are at least k good pairs (a, b)? If this will be the case, then overall complexity will be O(n log n + result), but there's a large constant next to result. There also a possibility that such constant doesn't exist :D. But maybe it can be at least proven that we can replace M by something growing slower than log^2 k :D. That means that following statement will be true:
if there are > M * f(k) * k inversion then there are at least k good pairs (a, b) (where f(k) / log^2 k -> 0)
If so, we will get better solution : p. But until something here will be proven this is some kind of meaningless considerations :P. But on a contest I will give it a try :P.
If not full editorial, please at least put the editorial for problem E and F. Editorials of other problems can be posted as comments of discussion in the blog.
I think best solition for problem B is this . best means that code is easy to read
And what do you think?
Copy-paste shouldn't be your friend (though it was mine in this problem xd)
there is a lot of DUPAs in your code, which sounds funny if I've understood it correctly :-)
As I said, my code for this problem is one of the worst codes I have ever written :P.
Does this mean from now to 8.10 ,there won't be any other CF round ?
Can anybody explain the solution of problem E ?
Problem is easily solvable with suffix automaton. We can use modification of algorithm from e-maxx for finding largest common substring of many strings. Firstly we concatenate strings like
a#b&c%. Then we build automaton. For each state we should calculate number of paths from it ending with character '#', '$', '%' in variables f,s,t. It can be done with dfs. It will be amount of rightmost positions of current state in first, second and third string. Then we can simply iterate over the states and increase the answer by f[i]*s[i]*t[i] where i is a number of state for all different lengths of substrings that are compressed in the state. I.e. for the segment(len(link(i));len(i)]You can check my solution for better understanding: 7265940
Who's in?
yarrr, Igor_Kudryashov and Goofy57 definitely are.
Me.
-XraY-, I think.
ACRush?
+ Anarivu, AnnKats93
I was invited as well. Also, I believe Alex_2oo8 will be able to participate onsite.
I will participate.
+Me :)
-Me
EXCUSE ME! Can i take part in this contest and will i be rated?
Yes. Even if you were not top 500 on round 1, you can still participate unofficially. It will be rated for both official and unofficial participants.
"MemSql round 2(online) нет возможности зарегистрироваться самостоятельно". Кто-нибудь зарегистрируйте меня!) И научите регистрировать других.
I can't register to contest. When I click "Register now" I receive notification "The contest does not allow self registration"
Did you choose the correct contest (online round)?
guy, do i can be rated in contest(online round)? :D
Um, sorry, you're right, thanks :P.
I already took a place in top 500 (such a great achievement xd) and I don't have time to come up with creative answers, so simply shut up retard.
sorry! maybe error system, :d
> rude post
I hope they give editorials this time.
will people who not finished in the top 500 in Round 1 be rated ?
It's been 2 months now since the contest...and the promised editorial has not come out. Are there still plans to release this?
If not, maybe we can compile all the relevant comments together to form what we already have.