


Всем привет!
Codeforces Round #259 (Div. 1 and Div. 2) начнется 1-го августа, в 19:30 по московскому времени.
Авторы задач: sevenkplus, xlk и я.
Тестеры: vfleaking, GuyUpLion, ztxz16 , CMHJT и Trinitrophenol.
Спасибо Gerald за его советы в процессе подготовки задач. А также огромная благодарность MikeMirzayanov и его команде за отличную платформу для проведения соревнований по программированию!
Сегодня вам придется посетить Equestria и помочь очень дружелюбной принцессе, Twilight Sparkle, решить несколько задачек.
Twilight Sparkle является главным действующим героем сериала <<My Little Pony: Friendship Is Magic>>.
Twilight Sparkle — единорог женского пола. В третьем сезоне сериала она превратится в единорога с крыльями и станет принцессой. У нее есть красивая пометка в виде 6-конечной пурпурной звезды, под которой находится белая звезда. Около вершин пурпурной звезды находятся еще 5 маленьких белых звездочек.

Конечно, я гарантирую, что знание сюжетной линии сериала не требуется для решения задач.
UPD
Разбалловка для первого дивизиона: 500-1000-1500-2500-2500.
Разбалловка для второго дивизиона: 500-1000-1500-2000-2500.






Of course, we guarantee knowing those background storyline and setting won't help you to solve any of our problems.
A pedantic note: I think you should instead guarantee that not knowing the setting won't hold you back from solving these problems. The reason is knowing this particular background might bring to your life some friendship which -- as we all know -- is magic. And noone should doubt that magic can help them solve tough problems.
Exactly! Thank you for remind me this! ~
oh. another chinese round ~
Codeforces Round 254 (Div. 1)
Codeforces Round #FF (Div. 1)
Codeforces Round 257 (Div. 1)
Codeforces Round 259 (Div. 1)
Chinese Div1 got a Ultra kill!! Someone stop it :D
Maybe they're going to do a rampage.
haha but , I DON'T WANT TO LOSE RATING :((((
But the next step is Monster Kill...
why it's not first blood
GIFF EZ CONTEST
I don't know whether it is also that popular in other countries, but in Poland it is very common to name function returning least significant bit a "MAGIC".
So, are you suggesting that this function will help? Maybe some Fenwick trees :P?
Why not
n&-n?I hate this n&-n thing xd. That is very strongly depending on system of representing it in a computer. Everyone who knows what is a binary system can agree with my version but to get your version work we need some kind of weird arrangement how to represent negative numbers and fact that it's working is rather a funny coincidence. n&-n is easier to remember, but n — (n & (n — 1)); is easier to come up with on your own and much more reasonable in my opinion.
(never mind, I messed up)
Your argument is true but almost all softwares&&hardwares use the same way to represent negative. So using
n&-nis OK i think. And more importantn&-nworks faster and because it's a very basic operation, say in Fenwick trees this trick proved to be helpful.In China, It's called the lowbit.
One my friend names functions MAGIC, MAGICMAGIC, variables — temp, temptemp :)
Deducing from that style of coding — is his rating greater than 1500? I wouldn't expect that :P.
How about this style of coding? ;)
I just wonder why he doesn't use a
swap()function... Even<algorithm>gives one easy-to-use templateIn many cases, the background is related with incredible and strange story. Thus, I always drop into puzzled condition.
I hope it will help me :3
Awesome 0.0
God bless you.
Floppy disks o_O?
Are those collector's items? Or diy things?
уи..поняши!:3
Wait, just one pwny? You guys haven't figured out how to stack pwnies like how you stack cows yet?
Maybe they want to create more contests like that :P.
they have already stacked up 4 contests. this is the fourth consecutive Div-1 round organized by a Chinese coder. :)
let us see how long they can keep it going!
I won't solve these tasks if Rarity doesn't appear.
Python will help me.
it looks like a horse — -?lol
Python haven't helped me. Maybe, these problems are better to solve with FiM++. Or with better brains.
comft.
The tambourine with ponies hasn't helped me too. Maybe, my place is in Div2.
why not 21:00 start?
For the glory of satan of course !
Oh yes!! There seems to be MLP FiM problem set!
I'm looking forward to compete this round as Equestrian (see my profile).
I'm waiting for The Wonderbolt characters' problem...
What is "MLP FiM" short for?
Seems to be My Little Pony: friendship is Magic.
THX for explanation~!
Most recent Div.1 CF Round authors are from China. Chinese people seem to have many ideas to write problems :)
That's because we can finally have a
long longholiday AND MORE IMPORTANT some people think setting a CF round is a lot of fun XDА Твайлайт умеет программировать? И если да, то на каком языке? :)
FiM++ же.
I believe this round will be very wonderful. I can't wait to join the round. MinakoKojima, you are my idol..(^ω^)
...
orzzz! Have got ready to become green again...
Why don't you try to look on the bright side?
It would be so great if start time of this Chinese-author round were to changed earlier to usual Chinese round time 21:00.
Firstly — next Chinese contest, secondly — brony contest. Gotta get outta from here xD. I won't be surprised if I see 5x3000 pts :D.
It might be with dynamic scoring :D
And then, Div 2 gets 3x3000pts problems, which will frighten off the news to Codeforces. ~
OK, show them some mercy. Problem A may be 2500 pts (Div1) only.
My daughter loves Twilight Sparkle. Every night I have to watch My Little Pony with her. I hope to get a good result in this round. I would like to show to my little daughter that my name has the same color of her Twilight Sparkle.
My best wish to you. Also give my regards to your lovely daughter~
Good luck & AC for fun!
Going to participate in the Div. 1 contest for the first time! Want to have a good experience! May the Almighty help me and all thanks goes to him!
Good luck!
Thanks and hope will see you in Div 1 in the next contest after today. Though I might be in Div 2 that time. :)
thx 4 ur wish, let's fight 4 the goal of div 1 together! good luck again! :)
WOWOWOWOWOWOWOWOW Its unbelievable that i m purple now!~ thx 4 ur hope ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ :)
Feeling happy to see that! Congratulations! I should be in Div 2 from next contest, but I could not even get a chance to submit a solution! Had no idea to make a solution.
However, best of luck for the next contests! :)
It seem to appear problems as "the one that don't know ******(an algorithm name) will FST!"
Don't worry.
The one, who don't know ***, won't pass the pretest.
Thx for the strict pretest~
I think Chinese problem setters are supposed to adjust the start time to fit Chinese participants even if only in one round.
MinakoKojima and I often go to bed late (2:00 AM ?) and get up late (10:00 AM ?).
For me, 10:00 AM is early)
It's typical Chinese Round! God bless us.
Why can't I register for Codeforces Round #259 (Div. 1)?
Your contest rating must be above 1700 in order to register for Div. 1 contests.
Div 2 (especially Chinese Round Div 2) is more suitable for you.
Chinese round again... but why not 17:00 MSK T_T
Btw I hope I can improve my rank to CM after this contest :D
(Maybe they need to have supper, but problem setter don't need to sleep early.)
It seems that setter xlk and tester GuyUpLion are the same person.
Maybe I'm wrong, but their names are Ke Bi and they are from Shijiazhuang.
They are definitely different people. Just one of them didn't tell us his true name.
Hmm, I guess one of them is Ke's girl friend.
Thank you for not guessing one is Ke's boy friend.
If you use your true name, I can also register the same account as you.
Why don't you think that is a common name? (Actually, it's a rare last name in China.)
Thank you for your clarification.
XD
Thanks MinakoKojima , xlk & sevenkplus for arranging the round. We hope more DIV1 rounds from you :)
It's a typical Chinese round.
What is the characteristics of a "typical Chinese round" ??
Hard problems (usually due to hard math) and weaker pretests than usual.
Hard math is better than very long code,do you think so?I also think that passing the Chinese pretests is skimble-skamble
When you can solve a problem, less code is a plus. When it's Chinese level hard, most people can't solve it, so it doesn't really matter how much code it needs :D
This time our pretests seem to be strong.
Thank you for spoilers about 3rd season in announce =/
MLP
why so serious?
if there was not any xiaodao in the world, it would be "Codeforces Round #59" you are maker of half of my contest life:P
Hope me can finish 2 problems in this round!
As a bad resault,I only finish one problem
Delinur в отпуске? :)
i just registered for this contest, and guess what i saw!
i think these three accounts are all the same person, and if found out they should be banned!
EDIT: it appears that the "real account" of this person has commented on OP about 10 minutes ago.
Извеняюсь за вопрос а эта строчка егодня вам придется посетить Equestria и помочь очень дружелюбной принцессе, Twilight Sparkle, решить несколько задачек. такая и должна быть?
А что не так? Сегодня вы посетите Equestria и поможете решить несколько задачек очень дружелюбной принцессе по имени Twilight Sparkle
I don't take medicine today,so I feel that my name is green QAQ I hope I can solve one problem designed by Chinese
I think that it's the first codeforces round which tested by gray coder))
Grey? Where? #EDIT: Found it.
Trinitrophenol
Maybe that will be helpful for the setters to judge whether the Div2 problems set by them are of proper difficulty and not too difficult.
In this case, i need blue tester for div1))
Trinitrophenol — тестер от Бога!
Хорошо уметь умных друзей! Они тебе и задачи дадут потестировать...
tourist is the last registrant, thereby marking his name for all to see in the next 3ish minutes.
but he didn't participate :(
but in today's MemSQL Start[c]UP 2.0 — Round 2, he did the exact opposite thing. :D
До раунда: "Бро, сегодня зарешаю как всегда А и постараюсь впервые решить B и оранжевым стану".
Через час после начала: "Решил B... ага".
То же самое...
До раунда: "Надоело быть внизу рейтинга, помнишь, как ты три задачи решил за полчаса тогда? Стремись!". "Решил A.. Ура, решен и B! Надо решать теперь С". ** Через пять минут **. "Уведомление: извините, ваше решение по задаче B взломано :(". ** Чудом пересдал задачу, нашел и контртест **. "Ну блин, опять результат похерил, попробую хотя бы других участников по задаче B ломануть, помнишь, как ты тогда за пять минут трех участников взломал? Стремись!". ** Статистика взломов -11 : +2 **. "Ёперный театр! Ну ничего, книжки почитаю, потренируюсь, вот в следующий раз...".
А я полтора часа пытался сделать что-нибудь по А (для тебя это С), а потом решил забить, ибо сдавать всё равно не было бы смысла. Зашло бы — ну круто 600+ место, минус рейтинг, не зашло — еще больший минус. А так хоть если не делаешь не одной посылки, то ничего не снимает.
Но мне еще больше обидно то, что я никого по-взламывать не смог, обычно решаю С за полчаса-час, читаю Д, понимаю что не решу, и потом хоть взломами оставшееся время развлекаю себя.
А какой смысл в том, чтобы ничего не сабмитить только потому, что из-за этого упадет твой рейтинг? С точки зрения полезности для твоего скила — это минусовое действие.
Ну во-первых, моё решение упало бы 100%, а во-вторых, что мешает мне заслать его уже после раунда? Мой скилл, думаю, от этого никак не пострадал бы.
А так вообще, я с тобой согласен, рейтинг — не главное в контестах, куда важнее опыт, но в этом конкретном случае не было никакого смысла засылать решение.
Палка о двух концах. С одной стороны, если точно уверен, что больше ничего бы не смог решить за полтора часа, и А решить тоже не смог бы, и повзламывать никого не смог бы — тогда, забив на контест, сэкономил время, чтобы не тратить его зря. С другой стороны, кто его знает, если была вероятность что-то решить (правильно или не совсем) — нас ведь учат никогда не сдаваться. Да и рейтинг придумали не только для того, чтобы радоваться его росту:) Если для тебя некоторые из div1 раундов слишком сложные, и ты не можешь там решить ничего полностью ни за полчаса, ни за целый контест, но ты будешь делать сабмиты в эти раундах и занимать далеко не лучшие места — то есть вероятность вернуться на некоторое время в div2, который ты еще не совсем побил. Или, если уже побил, то на один раунд, в котором ты докажешь всем, что получилось недоразумение:)
А если отбросить рейтинг, то о пользе самого факта написания этого контеста можно отдельный разговор завести. Например, прокачка каких-нибудь навыков работы в стрессовой ситуации, когда мысль "блин, я сегодня глубоко на дне" мешает работать — сдать задачу в таких условиях было бы намного более полезно, чем сделать то же через какое-то время в архиве. Еще конкретно под формат СF — можно потренироваться пихнуть откровенную лажу в претесты, и потом кого-то поломать на этой задаче.
I am going to sleep. Remaining problems is very hard.
what if one of ur Pretests passed submissions gets Hacked?
http://www.urbandictionary.com/define.php?term=ur
A trade-off between early sleeping and submission's safety.
looks like you made a good choice. all ur submissions got Accepted.
also, it must have been a nice surprise when u woke up and saw that u became Grandmaster. congrats. :)
tks
Awesome contest!! Thanks MinakoKojima , sevenkplus and xlk :D
Что такое математическое ожидание?
Ссылка из условия задачи не помогла?
Нет — можете простыми словами объяснить?
среднее значение случайной величины
Честно говоря, трудно сказать проще, чем написано в первой строке по ссылке, но давайте попробуем. Пусть есть случайная величина x, она может принимать значение xk с вероятностью pk. Тогда матожидание значения x это сумма произведений xk на pk. По сути, матожидание это то самое среднее значение, которое получается при достаточном количестве "бросков" этой случайной величины.
То же самое, записанное нормально: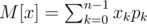 , когда x может принимать n различных значений.
, когда x может принимать n различных значений.
Пусть у вас есть какое-то испытание. В данном испытании выпадают случайные значения {x1, x2, ..., xn}, с соотвествующими вероятностями {p1, p2, ..., pn}.
Тогда мат. ожидание есть: .
.
Интуитивное объяснение. Представьте что мы провели m испытаний, и засекли сколько раз, какое значение выпало. Пусть xi выпало ki раз. Посчитаем среднее значение.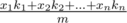 . При большом количестве испытаний
. При большом количестве испытаний 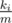 стремится к pi. Таким образом получаем формулу математического ожидания.
стремится к pi. Таким образом получаем формулу математического ожидания.
Просто говоря, мат. ожидание показывает какое среднее значение примет случайная величина при большом количестве испытаний.
А ничего, что есть ссылка на Википедию?
how to solve Div-1 B?
DP[i][mask] for each i = 1 .. n calculate min answer from 1 to i by using mask of prime numbers.
if we choose for b[i] not prime number we can call b[i] = p[x1] * p[x2].... so it's mask of primes.
Oh what a nice solution. I was thinking of a completely different Solution 7320838 during contest.
Too bad that i couldn't find my bug in contest :(
dp[i][mask] is the answer for the first i numbers if the numbers we used divide only the prime numbers from mask.
Here is a short explanation.
You have to notice that it is a Bitmask DP problem. There are 16 primes less than 58. So keep a mask of 2^16, representing the primes used before. Then start a dp with states dp(pos,mask). In each position, you can place from 1-60. You can however only place a number if and only if it contains primes that have not been used before. Otherwise you can get gcd > 1.
Just take the minimum configuration. Later print your path.
But you can't choose 100 pairwise primes less than 58. Don't downvote if I'm wrong. We are all here to learn.
Edit: NVM, forgot about 1s.
Found few people in my room who used this for solution of Div1 A : pow ( m, n ). Instant hack with test case ( 100000, 100000 ) :p That really boosted my ranking :D
i tried to hack two participants who used
powfunction to find xy, but it returned Unsuccessful hacking attempt. :(any idea why?
JuanMata You can not hack your friends :P
You were just simply looking at power function. I was using power function differently. My code has expressions of the form pow(x/y, n). It would have failed if I would have done pow(x, n) / pow(y, n).
We generally don't use pow cause of precision error. But since we are working with double here and the judge is going to ignore 10^-4 error anyways, I guess precision no longer becomes a issue anymore.
I managed to hack cause they were trying to find pow(10^5,10^5), which is a large number and will given INF or NAN.
It depends on how one uses it. I used pow as well. Except I had pow(x, y) only, where 0 <= x <= 1, which is why I don't get overflow, unlike if I was to use pow(m, n).
yes, i got it. to run?
to run?
but what i mean is, doesn't
pow(x,y)takeI think it is doable in O(log y) time.
i know we can implement finding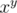 in
in 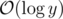 .
.
but i was referring to the
powfunction provided by<cmath>.pow(x,y)uses an expansion...so a coprocessor (in short, a part of processor that conducts some funny operations, including computations on floating point numbers) needs to do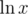 ) and
) and
exp(ex),ln(mul(x·y) operations. Each of them can be done in a matter of dozens of CPU clock ticks.In VC++
pow(x,y)with integeryrefers to binary exponentiationThis code — an terrible nightmare for the hacker... 0_0
why do you expect pow function for fail ?
when we take (10^5)^(10^5) in denominator i thought it will work in python. so tried to write in python, but got only runtime errors (i had not used python before)
Yeah... python can handle pretty large numbers, but it's still slow working with them. That's why you get TLE's if you do the unsimplified formula.
How to solve Div 1-A?
The probability that no value is bigger that x is equal to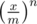 . It means that probability that max value is equal to x is equal to (probability of not getting >x) — (probability of not getting >x-1). Then you can compute the expected value.
. It means that probability that max value is equal to x is equal to (probability of not getting >x) — (probability of not getting >x-1). Then you can compute the expected value.
I got the formula...But I could not translate it into code..as the constraints were too high.
Programming languages usually have a routine to compute the powers of floating-point numbers very fast.
E.g. in C++ you can compute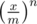 as follows:
as follows:
You can assume it works in constant time.
C++ has a useful function:
pow(base,exponent), which is fast enough.We can simplify the formula as:
could you explain this simplification?
There is a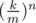 chance that maximum will be ≤ k. Consider sequence 1, 2, ..., m: probability for each k to be the max is
chance that maximum will be ≤ k. Consider sequence 1, 2, ..., m: probability for each k to be the max is 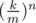 minus probability that every less value would be the maximum, so
minus probability that every less value would be the maximum, so 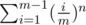 . Then multiply by value to get the expected value and you should get something along these lines.
. Then multiply by value to get the expected value and you should get something along these lines.
I just realized telescoping series in this sum. Anyway, thanks
Sorry, duplicated and deleted. See below.
It can be derived like this:
also:
are you serious? http://codeforces.net/contest/453/submission/7310927
Well, this guys did this:
Since, p <= 1, pow ( p, n ) will not overflow. pow ( m, n ) however will overflow.
Ac-93 probably meant that you included a (quite long) segment tree implementation in an easy math task :D
firstly, the code is submitted by Ac-93 himself.
secondly, he is not invoking those functions anywhere in
main. i don't see anything wrong with having segment tree implementation as part of one's template.Умение составлять сбалансированные проблемсеты у китайцев в крови:)
в Б кто-нибудь еще так делал??? dp[i][mask][last]: i = префикс, mask = маска взятых простых от 2 до 31, k = к-ое простое по счету начиная с 37?
Я просто маску простых до 60 считал, в таком случае, k-ое простое, кажется, не нужно.
ой, я насчитал, что простых до 60 20 штук, и 100 * 2^20 = 400 MB. OMG Из-за этого думал как сократить память и фигню эту написал.
Это нормально заходит в ML и при 20 простых, разве нет? Достаточно держать текущий слой динамики и всю таблицу предков для восстановления ответа. Текущий слой — это 2^20 (ладно, для максимального удобства еще на 4 и на 2, получаем 8 мб), предки — 100*2^20 char'ов, еще 100 мб. В сумме даже меньше половины МL.
чар — это с помощью какого числа пришли в это состояние? ну я хотел просто предков хранить парой(какая была маска, с помощью какого числа). всмысле не хотел каждый раз маску там пересчитывать(я вчера еле писал, башка раскалывалась, просто стало интересно Б идея верная или нет)
Да, можно и так, хранить с помощью какого числа пришли. Если для каждого числа прекалькнуть его маску в терминах наших простых, то и переходы вперед, и переходы назад в восстановлении ответа будут одинаково простыми — один xor.
Можно last не хранить в параметре, если динамикой сначала добавить все числа <= 30, а остальные выбирать жадно.
Thank you for the contest and for the great tasks!
If I would give feedback on the tasks, I would say that I disliked that the graph is not guaranteed to be connected in Div1 C/Div2 E. This, in my opinion, was a restriction with a single purpose in mind — let's invent some edge cases, which is the purpose I heavily dislike. If the graph is connected, there are no edge cases at all (and it is always possible to construct a path). Now, because this is not guaranteed, I had to add a bunch of "edge case" code — find out which vertex to start DFS from (rather than starting from any with single component), check if there is only 1 connected component etc. With a single component I felt that the task actually had short and clean solution in code. Was it really necessary to do this?
Furthermore, because the authors didn't include any test with answer -1 in pretests, I had wasted an hour worth of points before someone hacked me and I found the lack of outputing -1 in my code. Sure, this is completely my fault. But one of the point of pretests is to check the format of the output (like if there are mutiple possible string outputs — have them all in pretests), and in this case -1 was never tested. Is it fair to penalize people who accidently mistyped this constant?
Sorry for that, acknowledged.
Wait, what?
I don't mind the possible disconnectedness, especially because the "if there's no answer" in the statement worked as a good hint, but the pretests definitely should've taken care of that. I also didn't really try hacking C because I thought the only special case was included in the pretests... I wonder how many people were in a similar situation.
Well, as I said above: weaker pretests than usual. Although in a different way than I meant :D
Yeah, I didn't paid too much attention to the hint "if there's no answer", because I see authors putting this in even if there is always solution, to hide that fact, because it might make the task easier.
But to highlight my point about disconnectedness, here is the difference between my original code and the accepted version. Sure, it certainly doesn't make the task bad — I liked it very much, but this code was in my opinion unnecessary and brought nothing to the solution of the task except edge cases. Before the whole code was: read the graph, run DFS, output the answer. Now we have extra steps: find the vertex to start from, check that there is no 1 in array after DFS.
And yeah, there were different approaches to this problem, in which having unconnected graph only brought 1 line modification.
My modifications were much simpler, it's mostly just rewriting "0" to "i" in a big chunk of code.
DIV1 A and DIV1B?
Div1A -> Calculate seperately the number of times:
1 would be maximum , 2 max ........ m would be maximum
Number of times 1 max = 1
Number of times 2 maximum = 2n — 1
Number of times i maximum = in — ((i - 1)n)
So Expected value =
Mix m^n with the numerator and you can get the answer
I made the mistake of not mixing m^n with the numerator
I think you missed an "i" in the expected value expression.
Thanks for correcting me .
Please can anyone tell me how do I post mathematical symbols here ?
\sum_{i=1}^m i * \frac{i^n — (i-1)^n}{m^n}
Thanks
This was my mistake! I also did summation from 1 to n. Output for given cases did not match. I did not think of debug. I thought approach was wrong. Then I saw the solutions...
Saw the same error again (here).
So, change the summation from 1 to m
No that's not why I coded it wrong . I took summation from 1 to m but did not merge the denominator: m^n with the numerator . Thus I thought that it would overflow and did not do anything about the problem .
a
gcd(6,8)=2
a
Task C is good, but I think it would be better to set that the input graph is connected. (The other part is not very interesting).
Task D is also good, but I think the TL is a bit tie. I managed to pass the pretest by code optimization.
Task E seems to be the harder version (force to do it online) of this task: http://hihocoder.com/contest/challenge1/problem/2
I think it is not a good idea to use it here since it has already used in previous contests. For example, since I know I can't even code solution for the eaiser task, I just skip this task and focus on D, it gives me some advantages.
Overall it is a good contest, thank you all writers and testers!
C is by me. It would be a bit unnatural to constrain the graph to be connected. Also, Egor gets WA because of this. :D
And this is why I disliked the absence of this restriction in the first place in the comment above. The whole idea in the solution is run on a single connected component, then you added unnatural expansion (unnatural to the solution rather than unnatural to the statement, and I probably don't even agree that this constraint in the statement is unnatural) to allow graphs to be not connected, so that there are now some edge cases/extra work to do. And as you wrote Egor failed because of this.
Seems to me that you're pretty happy with that. I believe authors should be happy when people fail their task with a wrong solution, rather than solving it correctly and failing on the edge case. But maybe that's just me.
Don't get me wrong, I still liked the task and the contest. As cgy4ever I just feel it could have been even better with that restriction.
Sometimes we need to left something to hack, and sometimes we cover the tricky part by constraints or give such case in examples.
For me, I only left it to hack if the task is very easy or a bit classic. If I'm the writer of this task, I will cover that trick cases, because this task itself is challenging, if someone get the solution but fail by that stupid trick then it is huge lost (Getting the solution is a challenging thing, so he should get points by this).
actually, Egor's solution 7313057 failed on a much easier case than where answer was
-1. :D (but you are right about graph not being connected)It's all about connectedness, so it doesn't matter.
Every problem setters should maximize following fraction:
To make problems better.
Well, of course I should be more attentive to details, no doubt about this. But I always thought that it is just a good taste for problemsetter to include sample with answer "Impossible" or such if there is such case. I know that at the very least TopCoder requires a thing
I know it is bad, that's why I put it in the middle night~ Princess Luna, can you hear me?
а можно как-нибудь челенжить такие сравнения в double? 7314095
или так складывать и сравнивать нормально?
Уж целые числа в диапазоне [0, 10^5] double хранит точно и его можно сравнивать без эпсилона. По стандарту double хранит 52 бита мантиссы, точности хватает.
ок, спасибо
Slowest system testing I've ever seen....only 4 submission are being judged at the same time!
I am amazed that you have done 62 contests but haven't seen slower system testing. The system testing is slow because there are too many test cases for problem A. We apologize for this.
I suppose it's some technical problem...because in every contest I see almost 10 submissions that are being judged simultaneously
there cant be more that 50 cases!
Oh LOL, DIV2C/DIV1A was damn simple, and I messed it up %)
В B прошёл перебор с отсечениями по ответу и времени. 7318167
У меня то же самое. Главное, это упорядочить массив.
Good problems — 9/10
Having disconnected graph in C was not something to complain about
-1 because two very hard problems for a single match is too much
I was right because I gave up and slept early.
Honestly, I would disagree with the statement "very hard problems", at least with E. It was pretty complicated, I must say, but if you carefully broke down the problem into smaller ones, it became quite straightforward (i.e. no superclever observations and tricks were needed), although implementationally demanding. Of course, it is only my opinion :) And I didn't manage to find a (obvious) bug before the end of the contest, but still it was not "very hard".
I could find a way to find the expected number for div1 A but I couldn't implement it because I don't know how to avoid overflow my idea like this:
let prob[i] be the probability that the max number is i (for all i from 1 to M) then I compute the expected number.
let dp[i] be number of sequences with length N and every element between 1 and i and max number is i.
dp[i] = i^N-(sum(dp[j]) for every 1<=j<i)
then prob[i]=dp[i]/(M^N)
then expected number is sum(dp[i]*i) for every 1<=i<=M
But I couldn't implement it because I don't know how to avoid overflow of dp[i] and (M^N). is there anyway to implement this idea or I should search for another idea that is easy to implement?
Here is a code for my idea it works correctly for small tests.
This is not the first time that I encounter a probability problem that I could find a solution to solve it but I couldn't implement it.
My first solution was hacked because of the overflow problem, but it's fairly easy to derive the solution that doesn't overflow if you had already come up with the one that does :)
7318172
"Twilight Sparkle — единорог женского пола. В третьем сезоне сериала она превратится в единорога с крыльями и станет принцессой."
Спойлер... не буду смотреть теперь...
my submission for problem E (Div 2) is giving WA on pretest 4.But when after the contest i tried the test case it's giving correct answer on my system as well as ideone.
This is the ideone link :- http://ideone.com/EWR4KA
my codeforces submission :- http://codeforces.net/contest/454/submission/7320400
can somebody tell me the reason behind it ??
Can't see any differencies, there's the same (incorrect) answer at ideone, isn't there?
18 3 2 1 2 4 5 7 5 10 5 4 8 4 9 4 3 6 3
there is no edge from 4 to 3
Quite unfortunate that my Div1-B solution passed all pretests :'(
i saw a few AC submissions in my room for Div-1 A, which printed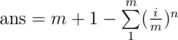 .
.
can anyone please provide a proof for this?
the answer is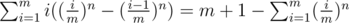 .
.
Am I too dumb or is it really not that obvious how the left hand side can be rewritten as the right hand side?
don't worry, u were not the only one. :D
here is the explanation. :)
Thank you! :)
JuanMata i don't think the limit of summation will be till m, it will be till m-1 and also instead of first term m+1 shouldn't m be there?
Have a look at this comment. http://codeforces.net/blog/entry/13247#comment-180671. If you simplify it, it will result in your formula.
The sum telescopes to
excellent explanation, thanks very much :)
Are you sure it is m + 1 in your formula?. There is only one way of getting the maximal element (in n consecutive trials) equal to one, then there are 2n - 1 ways of getting the maximal element equal two, 3n - 2n ways of getting the maximal element equal to 3, and so on. The total number of possibilities is, of course, mn. Then the expectation is calculated in the following way:
In formula by JuanMata the summation is till m. Notice that the last term is (m/m =1) so it will cancel the previous 1 . This will leave the formula given by ericxu0.
PS: There is a small typo in you formula , the summation should be till m-1 not n.
Div1-B, Nice problem!
For Div.2 problem B: http://codeforces.net/contest/454/problem/B My Submission: http://codeforces.net/contest/454/submission/7316030 It fails on pretest 6. If I'm right, here is an equivalent test: 5 4 1 2 3 5 How this array can be sorted using the given move? If my test is not equivalent, please update me with a correct one that I can trace. Thanks.
I dont think that it is equivalent. Here is a test case which your code fails. 3 1 2 1.
How to solve Div2-C ?
Look at exmath89's post for the expression to evaluate. To evaluate this expression, for everything in the summation, calculate it with exponentiation by squaring. Then, sum these up and subtract from m to get the answer.
Thank you
I try to hack 7313853 during contest with test case :
It checks all the states , with == operation for deque (99999 times for a 100000 size deque) ... My hacking of TLE was unsuccessful...
Now it has been TLE on case 41 , With a equal N , but using repetitive number 1...
Isn't it Weird ? I mean are we hacking Deep until STL Codes ? :D
The == operator only has to look until it finds a single mismatch -- so for 99999 of those equality comparisons, it exited after looking at just the first element of both deques. The system test case was TLE because it had to look through all of those 1s before finding a mismatch :)
Yes but i was not thinking of The STL implement, i thought its Linear so it should fail.
I mean my testcase should do some hacks to make STL deque Linear in case of hacking this submission. It was a bit unusual for me.
STL is evil in some way... Believe me, after IPSC 2014 there will be "HashSetKiller" programs, like already exist JavaQuickSortKiller!
p.s. one problem in this year's IPSC is to hack C++ and Java hashset program to let them get TLE in not very large test case, and there even exists a input that could hack both programs! (See HARD version of that problem)
That's Cool!!
I will check more in the STL implements.
Ratings are updated!
I was 45 minutes late, but still +71 rating.Thanks for great problems.
Forgive me if I'm a bit retarded in that subject, but were 50 points always deducted for submissions that fail on a sample test, but not on a 1st test? I thought that rule of not deducting 50 points for submission failing 1st sample test applies to all samples.
It applies only for the first sample, I can't get the point of this though.
it is mainly to check that output format exactly matches with what the checker expects. this is especially useful in problems like this one.
This way you are not penalized in case of your submission failing due to wrong output format, or if you simply chose wrong file to upload/ wrong problem to submit against.
It can be said that you pay for your own carelessness, but anyway prevention of that sort of mistakes is pretty sweet. I guess you've just never submitted wrong file on a contest ;)
Well I believe that it won't hurt if all the samples are included :D
Completely agree with you. In this contest, I got two WA on pretest 2 in div1C, which was one of the samples, directly costing me 100 points.
Though I didn't pass the system test anyway :(
The point is that you should test the samples. The reason why first sample isn't penalized is I believe to avoid penalties for technical stuff (like how to deal correctly with packages in Java, for example) rather than avoid penalizing for WA1.
Someone please tell how to solve div1C?
May I ask you to do your next contest in "Adventure Time" setting? It's very nice too :).
may i ask you not to post such large photos in comments? they are not so nice. :(
I didn't knew that CF posts pictures in their full size. My first picture-upload :(
Following this success, I will make my next round with Pokemons!
Round Stats
Thanks for the awesome problemset. Unfortunately I missed this round :-(.
OFF TOPIC THOUGH: I just came to remember this author MinakoKojima for some special reason. some days ago I was trying to learn link cut tree and found her blog:- http://www.shuizilong.com/house/archives/spoj-9577-dynamic-tree-connectivity/
Thank you MinakoKojima for your contribution to the community.
+122 rating. I love ponies, also this is surely great contest!
Ох, какая же идиотская бага у меня в Е. И главное оно прошло пртесты только потому, что либо n <= 200, либо n делится на 200 в претестах
Официальный разбор будет?
А чем, вот этот Разбор отличается от официального? Ну кроме того, что он только на английском, которого я не знаю.
А вообще, если кто-то не в курсе, то не обязательно, чтобы о разборе было написано в анонсе раунда, достаточно войти в сам раунд, и там справа снизу есть раздел "Материалы соревнования", содержащий ссылки на все записи в блогах пользователей связанных с данным раундом (то есть анонс и разбор задач, а может и еще что-то).
The new Editorial is available here.
Моё решение по А div1 не сильно отличается от оригинального, кроме того, что я забыл про существование функции pow() и возводил числа в степень используя цикл. Из-за этого моё решение работало за O(nm), что должно было бы привести к однозначному TL, но меня спасло небольшое отсечение по ответу. А именно: перестать считать, когда вероятность выпадения данного числа будет меньше 1e-7. Тогда для ввода 100000 100000 достаточно сделать не 100000 итераций, а всего 28. Но тут я решил поэкспериментировать с точностью, и вот что вышло: Моё решение.
Тест 10.
Ввод: 94444 9
Вывод: 84996.6669186450
Ответ: 85000.099992058866
Комментарий чекера: ok found '84996.66692', expected '85000.09999', error '0.00004'
В условии задачи было сказано: "Ответ будет считаться правильным, если его относительная или абсолютная погрешность не превысит 1e-4."
Относительная погрешность, которая проверяется чекером, как раз не превысила норму, но вот абсолютная погрешность получилась колоссальной. По-моему, было бы куда справедливее, если бы в условии задачи стояло бы И вместо ИЛИ. Хотя, возможно, в некоторых задачах добиться нужной абсолютной погрешности нельзя из-за того, что сам тип dooble хранит только несколько значимых цифр, но вот в этой конкретной задаче необходимая погрешность достижима.
Нет, тут должно быть как раз ИЛИ. Вы даже правильно указали причину — в некоторых задачах добиться нужной абсолютной погрешности нельзя из-за того, что сам тип dooble хранит только несколько значимых цифр. Это уже классика составления задач, участники привыкли видеть именно такое определение погрешности, и если вдруг требуется что-то другое (допустим, учитывается только абсолютная погрешность), я считал бы хорошим тоном написать об этом в условии жирным текстом.
Кроме того, вы умеете доказывать, что в этой задаче действительно достижима абсолютная погрешность в 10^-4 (или, что то же самое, относительная в 10^-9)? Это не так просто, как кажется на первый взгляд.
Ну и, вообще говоря, в данной задаче абсолютная погрешность всегда не больше относительной, поскольку правильный ответ не меньше единицы :)
Ранее я не замечал этой тонкости составления задач. Раньше всегда я, и моя команда, решали задачи опираясь чисто на абсолютную погрешность, считая это достаточным для получения правильного ответа. Спасибо за объяснение.
Can you give me solution for this round? Thank u.
/blog/entry/13190
Div-2 A solution using regexp (language: Perl): longer, shorter.
Wrong picture guys. When Twilight is solving problems she looks different: