


Hii I am trying to solve this problem http://www.spoj.com/problems/ZQUERY/ after thinking so many days i am not able to come up with efficient solution ,would any one like to suggest some idea, how to solve this ?
→ Pay attention
→ Streams
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3856 |
| 2 | jiangly | 3747 |
| 3 | orzdevinwang | 3706 |
| 4 | jqdai0815 | 3682 |
| 5 | ksun48 | 3591 |
| 6 | gamegame | 3477 |
| 7 | Benq | 3468 |
| 8 | Radewoosh | 3462 |
| 9 | ecnerwala | 3451 |
| 10 | heuristica | 3431 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 167 |
| 2 | -is-this-fft- | 162 |
| 3 | Dominater069 | 160 |
| 4 | Um_nik | 158 |
| 5 | atcoder_official | 156 |
| 6 | adamant | 152 |
| 6 | djm03178 | 152 |
| 8 | Qingyu | 151 |
| 9 | luogu_official | 149 |
| 10 | awoo | 147 |
→ Find user
→ Recent actions






Codeforces (c) Copyright 2010-2025 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Feb/20/2025 22:24:09 (i1).
Desktop version, switch to mobile version.
Supported by

Obviously, you can sort the queries to solve the problem offline and use prefix sums to covert the question to "longest subarray with S[l] = S[r], L ≤ l ≤ r ≤ R.
Then, you can increase R and keep the answers for all L; it's just a matter of updating these answers when R is incremented. It can be done in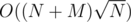 .
.
@Xellos Thanks , can you explain more how to solve efficiently to find the longest subarray with S[l]=S[r] ,L<=l<=r<=R,
can you please explain the part keep answer for all L?
First we use this Mo's algorithm to sort Query.
http://codeforces.net/blog/entry/7383
Let's call each group is a "bucket"
For each Query, we have to find i j which s[i] = s[j] and L<=i<=j<=R
Each i j has 3 cases :
i and j in bucket, so we can for, just O(sqrt(n))
i in bucket, j out of bucket. Let's call id1[s[j]]=j is the max position of s[j]. So answer is max(id1[s[i]]-i)
i and j out of bucket. Similar, call id2[s[j]]=j is the min position of s[j], so answer is max(id1[s[j]]-id2[s[j]])
I_love_PMK can you explain bit more after query sorting step ?
Let's p = sqrt(n)
Every query has L <= p is in bucket 1
p < L <= 2*p is in bucket 2....
With every query in the same bucket, sort query with increasing of R.
I have solved it with MO's algorithm + segment tree for keeping track of the maximum value . Complexity is O( (N + M) * ROOT(N) * LOG (N) ) .
Here is the implementation http://ideone.com/YayNX7.
It would be good is someone can tell how to solve without the segment tree in O( (N + M) * ROOT(N) ).
Could you please explain how did you solve it??
Have a look at codechef march challenge problem: qchef , it has a nice and detailed editorial.
Thanks Everyone now it is solved :)
Here is a editorial to a different problem with a similar solution.