


I hope everyone enjoyed the tasks, and thank you for participating.
Thank you to the coordinators and testers for suggesting solutions and modifications to the tasks, as I alone wouldn't be able to solve my own tasks or make it to how it is right now. Also thank you to them for dealing with me since July.
Please tell me in the comments if the editorial is written incorrectly or unintelligibly somewhere. I'm not the best at phrasing some things, and would appreciate amendments to the editorial.
Something doesn't change after each operation.
The average of the entire array doesn't change after each operation. Simply check whether the average value of $$$a$$$ is $$$x$$$ or not.
Time complexity: $$$\mathcal{O}(n)$$$ per test case.
Submission: 310297520
Try to put as many people in cell $$$n$$$ as possible.
The minimum sum of distances will always be $$$1$$$.
The following configuration gives $$$1$$$ as the sum of distances.
For odd $$$k$$$: $$$n, n, \ldots, n, n, n-1$$$
For even $$$k$$$: $$$n-1, n-1, \ldots, n-1, n, n-1$$$
And the sum of distances cannot be $$$0$$$.
Look at this as a directed (or more specifically, a functional) graph. There will be a cycle, and people in the same cycle will never be in the same cell, so not everyone can simultaneously be in cell $$$n$$$.
Time complexity: $$$\mathcal{O}(n)$$$ per test case.
Submission: 310297574
Prove that the optimal configuration is unique.
Rearrange the equation around.
Try to maximize the missing number.
The equation can be rearranged to
Choose $$$a_1$$$ as the largest number, $$$a_3, a_5, \ldots, a_{2n+1}$$$ as the next $$$n$$$ largest numbers, and the rest as $$$a_2, a_4, \ldots, a_{2n-2}$$$. The value of the missing number $$$a_{2n}$$$ will be larger than $$$a_1$$$, and so larger than every number in $$$b$$$.
Time complexity: $$$\mathcal{O}(n \log n)$$$ per test case. Logarithmic factor is from sorting.
Submission: 310297635
There are some randomization solutions where we just shuffle $$$b$$$ randomly, fill the missing number, and attempt it as a possible solution. I do not have a proof or disproof of whether this would work well enough.
It is optimal to place everyone on the same lane.
Think about the multiplier.
It is best to think of each $$$\tt{+}$$$ as "how much can we multiply this by".
This is the greedy solution.
When we get more people, place all to where the $$$\tt{+}$$$ will occur first. If both lanes have the next multiply at the same gate pair, then choose the one with higher multiply. If the multiply is the same, look to the next multiply.
It's easier to think of $$$\tt{+}$$$ as $$$\tt{x} 1$$$. The idea is as follows.
Consider the range of gate pairs between two pairs with different multiply, and the pairs in the range all have the same multiply. You have $$$l$$$ people on the left side and $$$r$$$ on the right side before you enter the range. In this range, you will gain a constant number of people, say $$$x$$$, regardless of your actions here. You choose to allocate $$$y$$$ to the left side.
At the end of the range, there's a pair of gates $$$\tt{x} a$$$ $$$\tt{x} b$$$ where $$$a > b$$$ (same argument for case $$$a < b$$$). After passing the gate, you will gain $$$(a-1)(l+y) + (b-1)(r+x-y)$$$ more people. With the current number people of $$$l+y$$$ on the left side and $$$r+x-y$$$ on the right side, we can see that maximizing $$$y$$$ is the optimal choice, because there always exist an allocation such that both number of people on the left and right side will exceed those with lower selection of $$$y$$$.
Time complexity: $$$\mathcal{O}(n)$$$ per test case. $$$\mathcal{O}(n^2)$$$ implementations are also acceptable.
Submission: 310297718
This is the dynamic programming solution.
Let $$$dp_l[i]$$$ and $$$dp_r[i]$$$ be the maximum possible multiplication possible that can be applied if a person enters the $$$i$$$-th left and right gate, respectively. Then we have the following equation (only for left is written, it's the same for the right).
If the gate is $$$\tt{+}$$$
If the gate is $$$\tt{x}$$$ by $$$a$$$
For each $$$\tt{+}$$$, we choose to place people at the side with more multiplication.
Time complexity: $$$\mathcal{O}(n)$$$ per test case.
Submission: 310297763
$$$n = 30$$$ constraint is due to overflow. The maximum answer is the case with $$$n = 30$$$, the first pair of gates is $$$\tt{+} 1000$$$ $$$\tt{+} 1000$$$, and the other pairs of gates are $$$\tt{+} 1000$$$ $$$\tt{x} 3$$$, giving the answer $$$171644573789571884 < 10^{18}$$$.
It is possible to solve this task under modulo and force $$$\mathcal{O}(n)$$$ solution, but it will be hard, or maybe impossible, to implement the DP solution which requires min/max operations, so I decided against it.
Try to get information on half of the bits.
Alternate the bits.
The queries are $$$\ldots 0101_2$$$ and $$$\ldots 1010_2$$$.
It's easier to look at the case with only two binary digits first.
Let the result of query $$$01_2$$$ be $$$q_1$$$ and $$$10_2$$$ be $$$q_2$$$.
Observe that if
$$$q_2 = 100_2$$$ then the first (from the right) digit of both $$$x$$$ and $$$y$$$ is $$$0$$$.
$$$q_2 = 101_2$$$ then the first (from the right) digit of one of $$$x$$$ or $$$y$$$ is $$$0$$$, and the other one is $$$1$$$.
$$$q_2 = 110_2$$$ then the first (from the right) digit of both $$$x$$$ and $$$y$$$ is $$$1$$$.
Similarly, if
$$$q_1 = 10_2$$$ then the second (from the right) digit of both $$$x$$$ and $$$y$$$ is $$$0$$$.
$$$q_1 = 100_2$$$ then the second (from the right) digit of one of $$$x$$$ or $$$y$$$ is $$$0$$$, and the other one is $$$1$$$.
$$$q_1 = 110_2$$$ then the second (from the right) digit of both $$$x$$$ and $$$y$$$ is $$$1$$$.
To generalize to every other digit, apply the same logic to every consecutive pair of digits in $$$x$$$ and $$$y$$$. Note that you must account for the carries from the digits before too.
After this, you will know for every digit position whether both $$$x$$$ and $$$y$$$ are $$$0$$$, are $$$1$$$, or have one $$$0$$$ and one $$$1$$$. You can use this information to find $$$(m|x) + (m|y)$$$ for any $$$m$$$.
Time complexity: $$$\mathcal{O}(\log \max (x))$$$ per test case.
Submission: 310297820
2077C - Binary Subsequence Value Sum
Find a closed-form expression for the score of a binary string.
The closed-form expression for the score of a binary string is
Where $$$cnt_0$$$ and $$$cnt_1$$$ are the number of $$$\tt{0}$$$ and $$$\tt{1}$$$ in the binary string, respectively.
The expression for counting subsequences might be simpler than you think.
Think of $$$\tt{0}$$$ as $$$-1$$$ and $$$\tt{1}$$$ as $$$1$$$. Let us count the number of subsequences of a binary string which will have the sum of $$$i$$$. Let $$$cnt_0$$$ and $$$cnt_1$$$ as the number of $$$\tt{0}$$$ and $$$\tt{1}$$$ in the binary string. The number of subsequences is
We change the perspective on $$$\tt{0}$$$ slightly from contributing $$$-1$$$ to the sum if chosen and $$$0$$$ to the sum if not chosen, to contributing $$$0$$$ to the sum if chosen and $$$1$$$ to the sum if not chosen. This changes the problem to having $$$cnt_0 + cnt_1 = n$$$ distinct objects and needing to pick $$$i+cnt_0$$$ of them.
So the desired sum of the score over all subsequences (see expression of score of a single string in Hint 2) is
At this point, you can throw convolution at the problem by precomputing the answer for $$$cnt_0 = 0, 1, \ldots, n$$$ and solve it in $$$\mathcal{O}(n \log n + q)$$$.
Submission: 310298025
Alternatively, you can do more algebra to arrive at a closed-form expression.
Consider
$$$\sum_{i = -cnt_0}^{n - cnt_0} {{n} \choose {i + cnt_0}} i^2$$$
$$$= \sum_{i = 0}^{n} {{n} \choose {i}} (i-cnt_0)^2$$$
$$$= \sum_{i = 0}^{n} {{n} \choose {i}} i^2 - 2cnt_0 \sum_{i = 0}^{n} {{n} \choose {i}} i + cnt_0^2 \sum_{i = 0}^{n} {{n} \choose {i}} 1$$$
$$$= n(n+1) \cdot 2^{n-2} - 2cnt_0 n \cdot 2^{n-1} + cnt_0^2 \cdot 2^n$$$
And
$$$\sum_{i = -cnt_0}^{n - cnt_0} {{n} \choose {i + cnt_0}} (i \mod 2) = 2^{n-1}$$$
So
$$$\frac{1}{4} \sum_{i = -cnt_0}^{n - cnt_0} {{n} \choose {i + cnt_0}} i^2 + (i \mod 2)$$$
$$$= \frac{1}{4} (n(n+1) \cdot 2^{n-2} - 2cnt_0 n \cdot 2^{n-1} + cnt_0^2 \cdot 2^n - 2^{n-1})$$$
$$$= 2^{n-4}(n(n+1) - 4cnt_0n + 4cnt_0^2 - 2)$$$
Time complexity: $$$\mathcal{O}(n+q)$$$ per test case.
Submission: 310297950
Find a way to get the answer if you fixed the largest value or the first value of the subsequence.
Sufficiently long (which is not that long) arrays will definitely be polygon side lengths.
Suppose we consider some integer $$$x$$$, and we try to find the lexicographically largest subsequence (say $$$s$$$) such that the maximum element of $$$s$$$ is $$$x$$$.
We can do it greedily.
For the subsequence $$$s$$$ to be valid, we need to ensure that the sum of the elements of $$$s$$$ is greater than $$$2x$$$.
So, our greedy strategy is like we have an empty vector $$$s$$$, and we iterate over the array $$$a$$$ from left to right, and for each element $$$a_i$$$, we do the following:
If $$$s$$$ is not empty and $$$a_i$$$ is greater than the last element of $$$s$$$, we will check whether we can make the total sum of $$$s$$$ greater than $$$2x$$$, if we remove the last element of $$$s$$$. Now what can be the maximum possible sum of $$$s$$$? We can just append all the elements of $$$a$$$ which are less than or equal to $$$x$$$, and are present to the right of $$$a_i$$$ to $$$s$$$.
Append $$$a_i$$$ to $$$s$$$.
Thus, we see that the subsequence $$$s$$$ is the lexicographically largest subsequence such that the maximum element of $$$s$$$ is $$$x$$$.
Now, we have $$$O(n)$$$ candidates for the maximum element of $$$s$$$. We cannot find the best subsequence for each candidate, as it will be too slow.
Here comes the key observation.
Now, what can be the maximum possible size of a sorted vector $$$v$$$ such that there does not exist any subsequence of $$$v$$$ which can form the sides of a valid polygon?
We should have $$$v_i > \sum_{j=1}^{i-1} v_j$$$.
Now, to get the maximum possible size of $$$v$$$, we should have $$$v_1 = 1$$$ and $$$v_i = 2^{i - 2}$$$ for $$$i \geq 2$$$.
Thus, the maximum possible size of $$$v$$$ can be $$$p = \log_2(10^9) + 2$$$.
Our claim is that in the lexicographically largest subsequence $$$s$$$, the maximum element should be one of the largest $$$p + 1$$$ elements of $$$a$$$.
Suppose we do not have the maximum element of $$$s$$$ in the largest $$$p + 1$$$ elements of $$$a$$$. Let's consider the multiset of the largest $$$p + 1$$$ elements of $$$a$$$. As we saw above, there should be a subsequence (say $$$t$$$) of this multiset which forms the sides of a valid polygon. Now if we insert the elements of $$$t$$$ in $$$s$$$, we will get a subsequence $$$s'$$$ such that $$$s'$$$ is valid and $$$s'$$$ is lexicographically larger than $$$s$$$.
Thus, we cannot have a subsequence $$$s$$$ such that $$$s$$$ is the largest possible subsequence and the maximum element of $$$s$$$ is not in the largest $$$p + 1$$$ elements of $$$a$$$.
Time complexity: $$$\mathcal{O}(n \log \max(a))$$$ per test case.
Submission: 310298095
Folding is basically alternating the parity of the indices.
Maximum subarray sum.
As mentioned in Hint 1, we can see that if the darkness of the cells $$$i_1, i_2, \ldots, i_k$$$ increases in some operation, the parity of $$$i_j$$$ should be different from that of $$$i_{j+1}$$$ for $$$1 \le j \le k - 1$$$
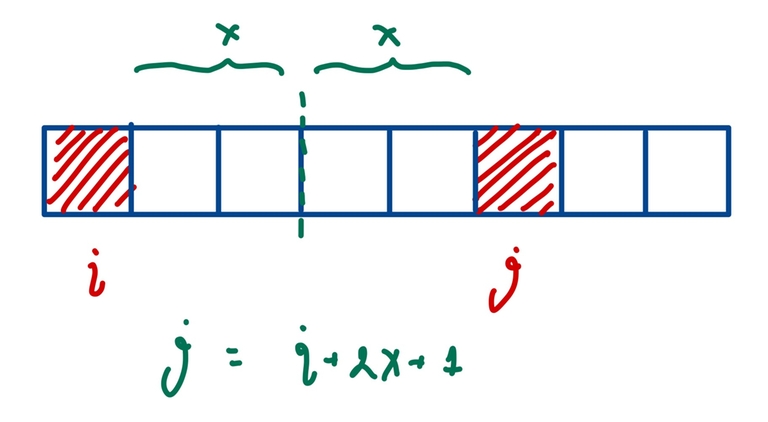
Let us try to find $$$f(a[1, n])$$$.
Consider an array $$$b$$$ such that $$$b_i = (-1)^i a_i$$$ for all $$$1 \le i \le n$$$.
Let us perform exactly one operation, and say our subsequence of indices is $$$i_1, i_2, \ldots, i_k$$$.
Let $$$a'$$$ be the updated array after performing the operation, and $$$b'_i = (-1)^{i'} a'_i$$$ for all $$$1 \le i \le n$$$.
Now we can see that
for all $$$1 \le l \le r \le n$$$.
This is so because for any subarray $$$b[l, r]$$$, if $$$x$$$ elements at odd indices and $$$y$$$ elements at even indices were selected, we should have $$$|x - y| \le 1$$$.
So, we can see that after any operation, the absolute sum of any subarray of $$$b$$$ decreases by at most $$$1$$$.
Thus, this gives us a lower bound for the value of $$$f(a[1, n])$$$, which is
Now let us consider the following greedy algorithm for selecting a subsequence $$$s$$$ of indices:
- Start from $$$i = 1$$$ and move to the right.
- If $$$b_i$$$ is zero, we continue.
- If $$$s$$$ is empty, we append $$$i$$$ to $$$s$$$, and continue.
- If $$$i$$$ does not have the same parity as the last element of $$$s$$$, we append $$$i$$$ to $$$s$$$, and continue.
- Otherwise, we continue.
Now suppose $$$T$$$ is the set of pairs of indices $$$(l, r)$$$ such that $$$b_l$$$ and $$$b_r$$$ are nonzero and
is maximized.
We can prove that the absolute sum of all subarrays in $$$T$$$ would be reduced by $$$1$$$ after performing the operation.
We can notice that if $$$(l, r) \in T$$$, then $$$l$$$ and $$$r$$$ should have the same parity. Otherwise,
Next, we claim that $$$l$$$ should be in $$$s$$$.
Suppose $$$l$$$ is not in $$$s$$$. This means that there should be an index $$$k$$$ in $$$s$$$ such that $$$k$$$ has the same parity as $$$l$$$ and there are no nonzero elements between $$$k$$$ and $$$l$$$ that have a parity different from $$$l$$$.
Now if that is the case, then $$$b[k, r]$$$ would have a greater absolute sum than $$$b[l, r]$$$.
Thus, we conclude that $$$l$$$ will always be in $$$s$$$.
Now let $$$d$$$ be the largest index in $$$s$$$ smaller than or equal to $$$r$$$.
First of all, we should have $$$d \ge l$$$.
Now $$$d$$$ should have the same parity as $$$r$$$.
This is so because if that is not the case, we should have $$$d < r$$$ and we would have selected $$$r$$$ or any other element having the same parity as $$$r$$$ after $$$d$$$ in $$$s$$$.
Thus, we can see that for all the pairs $$$(l, r) \in T$$$, we should have $$$l$$$ in $$$s$$$ and the largest element smaller than or equal to $$$r$$$ in $$$s$$$ should have the same parity as that of $$$r$$$. This implies that the absolute sum of all subarrays in $$$T$$$ would be reduced by $$$1$$$ after performing the operation.
This is because if $$$l$$$ is odd, we would have added $$$1, -1, 1, -1, \ldots, 1$$$ to the subarray $$$b[l, r]$$$, increasing the subarray sum of $$$b[l, r]$$$ by $$$1$$$.
And if $$$l$$$ is even, we would have added $$$-1, 1, -1, 1, \ldots, -1$$$ to the subarray $$$b[l, r]$$$, decreasing the subarray sum of $$$b[l, r]$$$ by $$$1$$$.
Now we can see that the greedy algorithm would achieve the lower bound.
So, the answer for the array $$$a$$$ is the maximum absolute sum over all subarrays of $$$b$$$.
Let us consider an array $$$c$$$ such that
We can further notice that the maximum absolute sum over all subarrays of $$$b$$$ is equal to
Now we can see that
Thus,
So,
Finding the value of
is a fairly standard exercise, which can be done using a stack in $$$O(n)$$$ time.
Submission: 310317161
Characterize the property of a good pair of arrays.
Think about the last operation that turns a good pair of arrays into the same array.
$$$(a, b)$$$ is a good pair only if at least one of these two conditions hold
$$$a = b$$$
There exist two distinct indices $$$i$$$, $$$j$$$ such that $$$b_i$$$ is a submask of $$$b_j$$$.
If $$$a \neq b$$$, then you need to do at least one operation to $$$a$$$. In the last operation, if you choose $$$i$$$, $$$j$$$, $$$x$$$, then $$$a_i$$$ is a submask of $$$x$$$ and $$$x$$$ is a submask of $$$a_j$$$. So in the final array, there must be at least one pair of submask and supermask.
Next, we will show that this is sufficient. For every index $$$k$$$ other than $$$i$$$ and $$$j$$$, you can do this.
Perform operation with $$$k$$$, $$$i$$$, $$$0$$$
Perform operation with $$$i$$$, $$$k$$$, $$$b_k$$$
Then
Perform operation with $$$i$$$, $$$j$$$, $$$0$$$
Perform operation with $$$j$$$, $$$i$$$, $$$0$$$
Perform operation with $$$j$$$, $$$i$$$, $$$b_i$$$
Perform operation with $$$i$$$, $$$j$$$, $$$b_j$$$
We need to check the two cases.
In the first case, the minimum cost will be $$$\sum_{i=1}^n |a_i - b_i|$$$.
In the second case, we want the minimum cost to create a submask-supermask pair in $$$b$$$.
Solution 1
For explanation simplicity, consider the graph $$$G$$$ with $$$2m$$$ vertices, representing the numbers from $$$1$$$ to $$$2m$$$. In this graph, there's an unweighted edge from vertex $$$i$$$ to vertex $$$i+1$$$, and from vertex $$$i$$$ to all submask vertices. Color all vertices in which its value appears in $$$b$$$. The answer is the shortest path between all pairs of distinct colored vertices.
The implementation itself (see below), uses dynamic programming consisting of three phases. The dynamic programming tracks the first and second closest vertex to each vertex, because the first closest vertex would be itself.
Propagate each colored vertices up (from $$$i$$$ to $$$i+1$$$).
Propagate to the submasks (from $$$i$$$ to its submasks).
Propagate down (from $$$i$$$ to $$$i-1$$$).
Time complexity: $$$\mathcal{O}(n \log n + m \log m)$$$ per test case. The $$$\log n$$$ factor is from the implementation which checks for duplicates in $$$b$$$ by sorting.
Submission: 310298215
Solution 2
Explanation will be added later.
Submission: 310317931
It might help to solve this task with two colors first. As in, minimize the difference between red and blue.
Walking back and forth can do wonders.
Let the difference between the red edges and the blue edges passed be $$$d$$$.
Let the edge weights of the red edges be $$$r_1, r_2, \ldots$$$ and the blue edges be $$$b_1, b_2, \ldots$$$.
Let $$$c = gcd(r_1, r_2, \ldots, b_1, b_2, \ldots)$$$ and $$$C = lcm(r_1, r_2, \ldots, b_1, b_2, \ldots)$$$.
We can find a walk with $$$d=0$$$ which passes every edge and returns to vertex $$$1$$$.
For each edge, walk to one of its endpoint, walk that edge, and then walk back to vertex $$$1$$$ using the same walk. This way, we passed through every edge an even number of times.
We will now walk back and forth using the edges we passed. This way, we can add to $$$d$$$ by some linear combination of $$$2r_1, 2r_2, \ldots, 2b_1, 2b_2, \ldots$$$. Because $$$d$$$ is divisible by $$$2c$$$, we can add to it such that $$$d=0$$$ by Bézout's identity.
Note: About the "can add by some linear combination", there's the slight caveat that we can only add the red and subtract the blue. We can subtract the red (or similarly, add the blue) by first subtracting from blue by $$$2C$$$, then add back red just so that it is deficit by the edge weight.
After passing every edge and returning to vertex $$$1$$$ with $$$d=0$$$, we can walk from vertex $$$1$$$ to vertex $$$n$$$. If the walk have $$$d$$$ divisible by $$$2c$$$, then the answer is $$$0$$$ and $$$c$$$ otherwise. The proof of this is similar to the proof above.
To check if a walk with $$$d$$$ divisible by $$$2c$$$ exist or not, create a state graph where each vertex is either "reach the vertex with $$$d$$$ divisible by $$$2c$$$" and "$$$d$$$ not divisible by $$$2c$$$".
In the two-color version (in Hint 1), we created a state graph on the parity. Can a similar idea be used?
Think about each color separately first.
Let
the edge weights of the red edges be $$$r_1, r_2, \ldots$$$, the green edges be $$$g_1, g_2, \ldots$$$ and the blue edges be $$$b_1, b_2, \ldots$$$.
$$$\gcd(r_1, r_2, \ldots)$$$, $$$\gcd(g_1, g_2, \ldots)$$$ and $$$\gcd(b_1, b_2, \ldots)$$$ be $$$c_r, c_g, c_b$$$.
the sum of weights of red, green and blue edges traversed be $$$d_r, d_g, d_b$$$.
Define $$$<d_{r_1}, d_{g_1}, d_{b_1}> = <d_{r_2}, d_{g_2}, d_{b_2}>$$$ only if $$$d_{r_1}-d_{g_1} = d_{r_2}-d_{g_2}$$$, $$$d_{r_1}-d_{b_1} = d_{r_2}-d_{b_2}$$$ and $$$d_{g_1}-d_{b_1} = d_{g_2}-d_{b_2}$$$.
In a similar manner to hint 1, there's a walk that passes through every edge and have $$$<d_r, d_g, d_b> = <0, 0, 0>$$$. Furthermore, if we have $$$<d_r, d_g, d_b>$$$, then we can have $$$<d_r + 2g_r, d_g, d_b>$$$ and $$$<d_r - 2g_r, d_g, d_b>$$$. The analogous statement holds for the other two colors.
Consequently, from any reachable $$$<d_r, d_g, d_b>$$$, we can have $$$<s_r, s_g, s_b>$$$, where $$$s_r$$$ is either $$$0$$$ or $$$c_r$$$ depending on whether $$$d_r \equiv 0$$$ ($$$\mod 2c_r$$$) or $$$d_r \equiv c_r$$$ ($$$\mod 2c_r$$$). The idea holds similarly for the other two colors. This invites us to look at each vertex as $$$8$$$ possible states, corresponding to $$$3$$$ binary options of each color.
We simply need to solve the answer for each reachable state then take the minimum. Each state corresponds to the following system of linear congruences.
We aim to minimize $$$\max(d_r, d_g, d_b) - \min(d_r, d_g, d_b)$$$ over all triplets which satisfy the conditions.
To do so, we will fix one of them, which we'll suppose is $$$d_r$$$, as the minimum.
Denote $$$f_g(p)$$$ and $$$f_b(p)$$$ as the minimum possible $$$d_g - (d_r + 2pc_r)$$$ and $$$r_b - (d_r + 2pc_r)$$$ where $$$r_g, r_p \geq d_r + 2pc_r$$$.
We want to find
Observe that $$$f_g(k + c_g) = f_g(p)$$$ and $$$fb(k + c_b) = f_b(p)$$$. By the Chinese remainder theorem, the expression above reduces to
Which can be evaluated in $$$\mathcal{O}(x)$$$.
Time complexity: $$$\mathcal{O}(n \log x + x)$$$ per test case. The logarithmic factor is from gcd computations.
Submission: 310298269
Some ending notes
This contest was originally proposed as a Div. 2 only. It was changed to Div. 1 + Div. 2 because we found task 1G, which was originally proposed with only two colors as 2D.
The contest itself retained little of the original proposal, and most of the tasks were once proposed for a lower position.
2B was proposed as 2A.
1A/2C was proposed as 2A.
2D was proposed as 2B. The base story is credited to my friend Punpun.
1B/2E was proposed as 2C.
1C/2F was proposed as 2E with $$$n \leq 5000$$$. The testers found the solutions for the current version.
1D was originally made for permutation arrays only. Credit to satyam343 for making the task.
1E/2G was proposed as 2D with binary arrays. The testers found the solutions for the current version. The idea of folding and dropping color is credited to my friend Punpun.
1F was proposed in a much easier form as 2B. It was buffed by satyam343.
Given arrays $$$a$$$, $$$b$$$ both of length $$$n$$$, perform the following operation no more than $$$2n$$$ times such that $$$a_i \neq b_i$$$ holds for at most $$$2$$$ values of $$$i$$$. The operation is the same one which is used to define a good pair of arrays.
- 1G was proposed as 2D with two colors. Solving this easier version can hint the full solution.
Arcaea is a good rhythm game with good mechanics, music, and story. In some tasks, I put music from Arcaea in it because I want to.






For 1A/2C how does the given solution ensure that the missing number produced satisfies the given constraint of being less than 10^18? Wasn't that also a constraint for the missing number? Am I missing something obvious here?
We see that the right hand side of the equation in the editorial is the sum of $$$n+1$$$ terms which are no greater than $$$1e9$$$, so this can't be larger than somewhere around $$$2e14$$$.
Ahh right. I forgot to see the bounds for b_i and just assumed they were from 1 to 1e18. Thank you for the clarification!
Yes, just see that the input value for array b doesn't exceed 1e9, and all the elements in b would be less that 1e9, so with some basic calculations it will give you that the missing value wouldn't exceed around 1e14.
can someone tell me why this div2 D solution doesnt work https://codeforces.net/contest/2078/submission/310325385 , its close but i dont know what is wrong with it
maybe i misread the problem at some point
thank you .
can someone please help me understand div2D DP editorial I just do not get it how is it working ?
The key idea is that you must decide where to assign your bonus people based not just on the very next gate, but on all the gates that come later. At first, it might seem that looking just one step ahead would work, but that only gets you close—not the full answer as you can see here https://codeforces.net/contest/2078/submission/310322360.
Instead, you need to see the entire future. By processing the multiplication operations from the end (backward), you determine the best multiplier chain available for each lane. In simple terms:
In short, knowing the full future multiplier effect lets you reliably choose the best lane to assign your bonus people—because once they’re placed, you can’t move them later
you can check my code here https://codeforces.net/contest/2078/submission/310327912
where i just compute the greatest multiplying factor using a prefix sum-like approach
so that i can greedily and reliably decide which lane to insert the bonus people and by having that you can do a normal dynamic programming approach
i would also encourage you to try all the ideas in your head and see them fail so that you can clear the doubts and understand it perfectly
Hope this helped :)
Thanks a lot
your welcome , i just relaized that i didnt actually put the AC submission
i edited it now
In problem 1E, I don't think we can prove both $$$l,r$$$ should be in $$$s$$$.
We can only prove $$$l \in s$$$ and the last element $$$k \in s$$$ in $$$[l,r]$$$ has the same parity as $$$r$$$. For example, consider $$$a = [1,0,1]$$$, then $$$s = [1]$$$ but $$$l=1,r=3$$$. Of course in this case the following proof still holds so it doesn't matter much :)
We can only prove $$$l \in s$$$ and the last element $$$k \in s$$$ in $$$[l, r]$$$ has the same parity as $$$r$$$.
Yes, I had even mentioned it in the editorial but mistakenly wrote that $$$r$$$ should be present in $$$s$$$ as well. I have fixed it.
div2 D, DP solution. So hard to understand. Can't even understand the first sentence
In case someone struggles to understand the $$$\binom{n}{i+cnt_0}$$$ thing like me, we can think it this way.
For a sequence A selected by $$$\binom{n}{i+cnt0}$$$, we form our sequence B by taking the 1s in A and the 0s not in A. Say A has $$$x$$$ 0s. So we have $$$(i + cnt_0 - x)$$$ 1s and $$$(cnt_0 - x)$$$ 0s in B. The score would be $$$(i + cnt_0 - x) - (cnt_0 - x) = i$$$. Namely what we'd like to achieve.
Ohhhh, how is someone supposed to come up with something like this in contest tho?? Thank you so much, I've been trying to get deepseek to explain that derivation to me for the last half hour :_)
I solved Div2 D like "mathematically on paper", storing "variables" at each step and, in the end, maximizing a certain function based on the upper bounds of those variables.
Let's say that in the i-th step, the total number of added people is x. In the next step, I assign y to the left gate and x — y to the right gate, ensuring that 0 <= y <= x. This process continues until the last step, where I sum up the values in the left and right gates and maximize the function.
To achieve that maximization, I looped through the coefficients from the last to the first, setting the variable to 0 if the coefficient was ≤ 0 or to its upper bound if it was ≥ 0