


Sorry for the late editorial. Our problem setters were so exhausted with the offline competition yesterday that they really need some good rest.
Despite the unexpected and unpleasant incidents that occurred, we are truly surprised and grateful that so many of you still participated in this competition! We sincerely hope you enjoyed it!
(Gratitude for all you guys from Ecrade_: I felt so heartbroken when I heard about the unexpected issues, but seeing so many people in the comments comforting us, sharing thoughtful and positive messages that showed genuine empathy, and continuing to fully support our competition even after the wasted time, I was deeply moved. Thank you all! Codeforces truly embodies such a positive and uplifting community spirit!)
2082A - Binary Matrix
Idea: Ecrade_
Do we really have to consider the problem on the whole matrix?
Let $$$r$$$ be the number of rows where the bitwise XOR of all the numbers in it is $$$1$$$, and $$$c$$$ be the number of columns where the bitwise XOR of all the numbers in it is $$$1$$$. Our goal is to make both $$$r$$$ and $$$c$$$ zero.
When we change an element in the matrix, both $$$r$$$ and $$$c$$$ change by exactly one. Thus, it's not hard to see that the answer is $$$\max (r,c)$$$.
The time complexity is $$$O(\sum nm)$$$.
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll t,n,m,r,c;
char s[1009];
bool a[1009][1009];
inline ll read(){
ll s = 0,w = 1;
char ch = getchar();
while (ch > '9' || ch < '0'){ if (ch == '-') w = -1; ch = getchar();}
while (ch <= '9' && ch >= '0') s = (s << 1) + (s << 3) + (ch ^ 48),ch = getchar();
return s * w;
}
int main(){
t = read();
while (t --){
n = read(),m = read(),r = c = 0;
for (ll i = 1;i <= n;i += 1){
scanf("%s",s + 1);
for (ll j = 1;j <= m;j += 1) a[i][j] = s[j] - '0';
}
for (ll i = 1;i <= n;i += 1){
bool sum = 0;
for (ll j = 1;j <= m;j += 1) sum ^= a[i][j];
if (sum) r += 1;
}
for (ll j = 1;j <= m;j += 1){
bool sum = 0;
for (ll i = 1;i <= n;i += 1) sum ^= a[i][j];
if (sum) c += 1;
}
printf("%lld\n",max(r,c));
}
return 0;
}
2082B - Floor or Ceil
Idea: Ecrade_, FairyWinx
Consider $$$x$$$ in binary form.
What are all possible values of $$$x$$$ after $$$n+m$$$ operations?
Let's consider how to find the maximum value first.
Consider $$$x$$$ in binary form. Let the number formed by the last $$$n+m$$$ bits of $$$x$$$ be denoted as $$$r$$$, and the remaining higher bits form the number $$$l$$$ (for instance, if $$$x=12=(1100)_2$$$, $$$n=1$$$, $$$m=2$$$, then $$$l=1=(1)_2$$$, $$$r=4=(100)_2$$$), then the final value of $$$x$$$ after $$$n+m$$$ operations will be either $$$l$$$ or $$$l+1$$$, depending on whether a carry-over occurs in $$$r$$$ during the last operation.
If there are no $$$1$$$s in the higher $$$m$$$ bits of $$$r$$$, then the carry-over in $$$r$$$ during the last operation can never occur (operating on some small tests may give you a better understanding). Otherwise, we can choose to perform $$$n$$$ floor operations first followed by $$$m$$$ ceil operations, which can guarantee a carry-over in $$$r$$$ during the last operation.
This demonstrates that performing $$$n$$$ floor operations first followed by $$$m$$$ ceil operations will always yield the maximum value. Similarly, performing $$$m$$$ ceil operations first followed by $$$n$$$ floor operations will always produce the minimum value. We can simply simulate these operations because after $$$O(\log x)$$$ same operations, $$$x$$$ will remain unchanged.
The time complexity is $$$O(T\log x)$$$.
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll t,x,n,m;
inline ll read(){
ll s = 0,w = 1;
char ch = getchar();
while (ch > '9' || ch < '0'){ if (ch == '-') w = -1; ch = getchar();}
while (ch <= '9' && ch >= '0') s = (s << 1) + (s << 3) + (ch ^ 48),ch = getchar();
return s * w;
}
ll F(ll x,ll n){
while (n --){
if (!x) return x;
x = (x >> 1);
}
return x;
}
ll C(ll x,ll n){
while (n --){
if (x <= 1) return x;
x = ((x + 1) >> 1);
}
return x;
}
int main(){
t = read();
while (t --){
x = read(),n = read(),m = read();
printf("%lld %lld\n",F(C(x,m),n),C(F(x,n),m));
}
return 0;
}
2081A - Math Division
Idea: Ecrade_
Consider $$$x$$$ in binary form.
What are all possible numbers of operations to make $$$x$$$ equal to $$$1$$$?
Consider using dynamic programming to calculate the answer.
Similar to the previous problem, the possible number of operations can only be $$$n-1$$$ or $$$n$$$, depending on whether a carry-over occurs in $$$x$$$ during the $$$(n-1)$$$ -th operation.
We can use dynamic programming to compute the probability of a carry-over occurring during the $$$(n-1)$$$ -th operation.
Let $$$f_i$$$ denote the probability of a carry-over occurring at the $$$i$$$ -th least significant bit. The recurrence relation is:
The final answer is given by $$$n-1+f_{n-1}$$$.
The time complexity is $$$O(\sum n)$$$.
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const ll inv2 = 5e8 + 4,mod = 1e9 + 7;
ll t,n;
char s[1000009];
inline ll read(){
ll s = 0,w = 1;
char ch = getchar();
while (ch > '9' || ch < '0'){ if (ch == '-') w = -1; ch = getchar();}
while (ch <= '9' && ch >= '0') s = (s << 1) + (s << 3) + (ch ^ 48),ch = getchar();
return s * w;
}
int main(){
t = read();
while (t --){
n = read(),scanf("%s",s + 1);
ll ans = 0;
for (ll i = n;i > 1;i -= 1) ans = (ans + (s[i] == '1')) * inv2 % mod;
printf("%lld\n",(n - 1 + ans) % mod);
}
return 0;
}
2081B - Balancing
Idea: Ecrade_
Let's only consider the comparison between adjacent pairs first. Call a pair $$$(a_i,a_{i+1})$$$ an inversion pair if $$$a_i>a_{i+1}$$$.
In each operation, how can the number of inversion pairs change?
Under what circumstances can we decrease the maximum number of inversion pairs in every operation?
Let's only consider the comparison between adjacent pairs first. Call a pair $$$(a_i,a_{i+1})$$$ an inversion pair if $$$a_i>a_{i+1}$$$. Our goal is to decrease the number of inversion pairs to zero.
If we choose to replace $$$a_l,a_{l+1},\ldots,a_r$$$, only the comparison between $$$(a_{l-1},a_l)$$$ and $$$(a_{r},a_{r+1})$$$ can change, which means we can eliminate at most two inversion pairs in one operation. Let $$$s$$$ be the number of inversion pairs in $$$a_1,a_2,\ldots,a_n$$$, then a lower bound of the answer is $$$l=\left\lceil\dfrac{s}{2}\right\rceil$$$.
Case 1: $$$s>0$$$ and $$$2\mid s$$$
In order to obtain the lower bound $$$l$$$, each operation must eliminate exactly two inversion pairs. This necessitates that we cannot alter any numbers before the first element $$$a_{p_1}$$$ of the first inversion pair or after the second element $$$a_{p_2}$$$ of the last inversion pair. (Why?)
An intuitive idea is that the difference between $$$a_{p_1}$$$ and $$$a_{p_2}$$$ should be as large as possible (more precisely, $$$a_{p_2} - a_{p_1} \geq p_2 - p_1$$$), so that a strictly increasing sequence can be "accommodated" between them. It is not difficult to constructively prove by recursion that this condition is both necessary and sufficient.
In other words, when $$$a_{p_2} - a_{p_1} \geq p_2 - p_1$$$, the answer is $$$l$$$; otherwise, an additional operation is required, making the answer $$$l+1$$$.
Case 2: $$$s=0$$$ or $$$2\not\mid s$$$
It's not difficult to prove that the answer in this case is $$$l$$$. (Why?)
The time complexity is $$$O(\sum n)$$$.
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll t,n,a[200009];
inline ll read(){
ll s = 0,w = 1;
char ch = getchar();
while (ch > '9' || ch < '0'){ if (ch == '-') w = -1; ch = getchar();}
while (ch <= '9' && ch >= '0') s = (s << 1) + (s << 3) + (ch ^ 48),ch = getchar();
return s * w;
}
int main(){
t = read();
while (t --){
n = read();
for (ll i = 1;i <= n;i += 1) a[i] = read();
ll ans = 0,pos1 = 0,pos2 = 0;
for (ll i = 1;i < n;i += 1) if (a[i] > a[i + 1]){
ans += 1,pos2 = i + 1;
if (!pos1) pos1 = i;
}
if ((ans & 1) || (pos1 && a[pos2] - a[pos1] < pos2 - pos1)) printf("%lld\n",(ans >> 1) + 1);
else printf("%lld\n",ans >> 1);
}
return 0;
}
2081C - Quaternary Matrix
Idea: Ecrade_
Do we really have to consider the problem on the whole matrix?
Use greedy algorithm and guess some possible conclusions. Can you prove them (or construct some counterexamples) ?
The problem can be rephrased as follows: Let the XOR sum of each row be $$$ r_1, r_2, \ldots, r_n $$$, and the XOR sum of each column be $$$ c_1, c_2, \ldots, c_m $$$. In each operation, we can choose any $$$ 1 \le i \le n $$$, $$$ 1 \le j \le m $$$, and $$$ 0 \le x \le 3 $$$, then let $$$ r_i \leftarrow r_i \oplus x $$$ and $$$ c_j \leftarrow c_j \oplus x $$$. The goal is to determine the minimum number of operations required to make all $$$ r_1, r_2, \ldots, r_n $$$ and $$$ c_1, c_2, \ldots, c_m $$$ zero.
Let $$$ R_x\ ( 0 \le x \le 3 )$$$ denote the count of $$$ x $$$ in $$$ r_1, r_2, \ldots, r_n $$$, and $$$ C_x $$$ denote the count of $$$ x $$$ in $$$ c_1, c_2, \ldots, c_m $$$. A trivial upper bound for the answer is $$$ s = R_1 + R_2 + R_3 + C_1 + C_2 + C_3 $$$, which corresponds to the scenario where each operation only zeros out one of $$$ r_i $$$ and $$$ c_j $$$.
To reduce the number of operations, we can consider grouping the non-zero elements in $$$ r_1, \ldots, r_n, c_1, \ldots, c_m $$$ into disjoint groups where:
- The XOR sum of each group is zero.
- Each group contains at least one element from $$$ r $$$ and one from $$$ c $$$.
For such a group, we can reduce the number of operations by one, as there always exists an operation which can zero out both $$$ r_i $$$ and $$$ c_j $$$. Thus, the goal is to maximize the number of such groups, and the minimum number of operations will be $$$s - \text{(number of groups formed)}$$$.
Define the following group types:
- $$$ P_2 $$$: Groups of the form $$$(R_1,C_1)$$$, $$$(R_2,C_2)$$$ or $$$(R_3,C_3)$$$.
- $$$ P_3 $$$: Groups of the form $$$(R_1,R_2,C_3)$$$, $$$(R_1,C_2,C_3)$$$, $$$(R_1,C_2,R_3)$$$, $$$(C_1,C_2,R_3)$$$, $$$(C_1,R_2,R_3)$$$ or $$$(C_1,R_2,C_3)$$$.
- $$$ P_4 $$$: Groups of the form $$$(R_1,R_1,C_2,C_2)$$$, $$$(R_1,R_1,C_3,C_3)$$$, $$$(R_2,R_2,C_1,C_1)$$$, $$$(R_2,R_2,C_3,C_3)$$$, $$$(R_3,R_3,C_1,C_1)$$$ or $$$(R_3,R_3,C_2,C_2)$$$.
Conclusion 1: There exists an optimal solution where all groups are of the form $$$ P_2 $$$, $$$ P_3 $$$, or $$$ P_4 $$$.
- Each group must have size at least 2. Groups of size 2 or 3 can only be $$$ P_2 $$$ or $$$ P_3 $$$.
- Groups of size 4 not conforming to $$$ P_4 $$$ (e.g., $$$ (R_1, R_1, R_1, C_1) $$$) can be decomposed into at least one $$$ P_2 $$$.
- Larger groups can be decomposed into combinations of $$$ P_2 $$$, $$$ P_3 $$$, and $$$ P_4 $$$.
Conclusion 2: There exists an optimal solution where all $$$ P_3 $$$ groups share the same structure, and so do all $$$ P_4 $$$ groups.
- Two different $$$ P_3 $$$ groups can be decomposed into at least two $$$ P_2 $$$ or at least one $$$ P_2 $$$ and one $$$ P_4 $$$.
- Two different $$$ P_4 $$$ groups can be decomposed into at least two $$$ P_2 $$$ or at least two $$$ P_3 $$$.
Conclusion 3: There exists an optimal solution where the elements in $$$ P_4 $$$ groups are a subset of those in $$$ P_3 $$$ groups (e.g., if $$$ P_3 $$$ is $$$ (R_1, R_2, C_3) $$$, then $$$ P_4 $$$ can only be $$$ (R_1, R_1, C_3, C_3) $$$ or $$$ (R_2, R_2, C_3, C_3) $$$). The proof is analogous to Conclusion 2 and is left as an exercise.
Based on these conclusions, the optimal strategy is: first form as many $$$P_2$$$ groups as possible; then form as many $$$P_3$$$ groups as possible from the remaining elements; then form as many $$$P_4$$$ groups as possible from the remaining elements.
After grouping, each group can be zeroed out with one less operation. Note that the remaining ungrouped elements require individual operations.
The time complexity is $$$O(\sum nm)$$$.
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll t,n,m,a[1009][1009];
char s[1009];
vector <ll> row[4],col[4];
inline ll read(){
ll s = 0,w = 1;
char ch = getchar();
while (ch > '9' || ch < '0'){ if (ch == '-') w = -1; ch = getchar();}
while (ch <= '9' && ch >= '0') s = (s << 1) + (s << 3) + (ch ^ 48),ch = getchar();
return s * w;
}
int main(){
t = read();
while (t --){
n = read(),m = read();
for (ll i = 1;i <= 3;i += 1) row[i].clear(),col[i].clear();
for (ll i = 1;i <= n;i += 1){
scanf("%s",s + 1);
for (ll j = 1;j <= m;j += 1) a[i][j] = s[j] - '0';
}
for (ll i = 1;i <= n;i += 1){
ll sum = 0;
for (ll j = 1;j <= m;j += 1) sum ^= a[i][j];
if (sum) row[sum].emplace_back(i);
}
for (ll j = 1;j <= m;j += 1){
ll sum = 0;
for (ll i = 1;i <= n;i += 1) sum ^= a[i][j];
if (sum) col[sum].emplace_back(j);
}
ll ans = 0;
for (ll i = 1;i <= 3;i += 1){
while (row[i].size() && col[i].size()){
ans += 1;
a[row[i].back()][col[i].back()] ^= i;
row[i].pop_back(),col[i].pop_back();
}
}
for (ll i = 1;i <= 3;i += 1){
ll j = i % 3 + 1,k = j % 3 + 1;
while (row[i].size() && col[j].size() && col[k].size()){
ans += 2;
a[row[i].back()][col[j].back()] ^= j;
a[row[i].back()][col[k].back()] ^= k;
row[i].pop_back(),col[j].pop_back(),col[k].pop_back();
}
while (col[i].size() && row[j].size() && row[k].size()){
ans += 2;
a[row[j].back()][col[i].back()] ^= j;
a[row[k].back()][col[i].back()] ^= k;
col[i].pop_back(),row[j].pop_back(),row[k].pop_back();
}
}
for (ll i = 1;i <= 3;i += 1) for (ll j = 1;j <= 3;j += 1) if (i != j){
while (row[i].size() >= 2 && col[j].size() >= 2){
ll r1 = row[i].back(); row[i].pop_back();
ll r2 = row[i].back(); row[i].pop_back();
ll c1 = col[j].back(); col[j].pop_back();
ll c2 = col[j].back(); col[j].pop_back();
ans += 3;
a[r1][c1] ^= i;
a[r2][c1] ^= (i ^ j);
a[r2][c2] ^= j;
}
}
for (ll i = 1;i <= 3;i += 1){
while (row[i].size()) ans += 1,a[row[i].back()][1] ^= i,row[i].pop_back();
while (col[i].size()) ans += 1,a[1][col[i].back()] ^= i,col[i].pop_back();
}
printf("%lld\n",ans);
for (ll i = 1;i <= n;i += 1,puts("")) for (ll j = 1;j <= m;j += 1) printf("%lld",a[i][j]);
}
return 0;
}
2081D - MST in Modulo Graph
Idea: newbiewzs
There are only $$$O(n\log n)$$$ edges that are truly useful in the whole graph.
First, for vertices with the same weight, they can naturally be treated as a single vertex.
We observe that in the interval of weights $$$(kx,(k+1)x)\ (k\ge 1)$$$, only the smallest $$$y$$$ is useful. It is because, if $$$x<y<z<2x$$$, connecting edges $$$(x,y)$$$ and $$$(y,z)$$$ will always be better than connecting $$$(x,y)$$$ and $$$(x,z)$$$.
Therefore, for a vertex with weight $$$x$$$, we enumerate $$$k = x , 2 x , \ldots , \lfloor \frac{n}{x}\rfloor\cdot x$$$. For each $$$k$$$, we connect $$$x$$$ to the smallest $$$y$$$ that is greater than or equal to $$$k$$$.
It can be proven that this approach guarantees a connected graph (since connecting only the first edge larger than $$$x$$$ already forms a connected structure).
This method generates $$$O(n\log n)$$$ edges (due to the harmonic series property). Directly applying Kruskal's algorithm would result in a time complexity of $$$O(n\log^2 n)$$$. With radix sort, this can be optimized to $$$O(n\log n)$$$.
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<string.h>
#include<vector>
#include<queue>
#include<map>
#include<ctime>
#include<bitset>
#include<set>
#include<math.h>
//#include<unordered_map>
#define fi first
#define se second
#define mp make_pair
#define pii pair<int,int>
#define pb push_back
#define pil pair<int,long long>
#define pll pair<long long,long long>
#define vi vector<int>
#define vl vector<long long>
#define ci ios::sync_with_stdio(false)
//#define int long long
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
int read(){
char c=getchar();
ll x=1,s=0;
while(c<'0'||c>'9'){
if(c=='-')x=-1;c=getchar();
}
while(c>='0'&&c<='9'){
s=s*10+c-'0';c=getchar();
}
return s*x;
}
const int N=5e5+55;
int MAXN=0;
int n,tot,ans,maxx,f[N],siz[N],p[N],bj[N],pre[N],suf[N],pos[N];
struct node{
int from,to,dis;
}a[N*20];
int cmp(node x,node y){
return x.dis<y.dis;
}
int find(int x){
if(f[x]!=x)return f[x]=find(f[x]);
else return x;
}
void merge(int x,int y){
x=find(x);y=find(y);
if(siz[x]<siz[y])swap(x,y);
siz[x]+=siz[y];
f[y]=x;
}
int T;
int main(){
T=read();
while(T--)
{
tot=ans=maxx=0;
for(int i=1;i<=MAXN;++i)
{
f[i]=siz[i]=p[i]=bj[i]=pre[i]=suf[i]=pos[i]=0;
}
for(int i=0;i<=MAXN*19;++i)
a[i].from=a[i].to=a[i].dis=0;
n=read();
MAXN=n;
for(int i=1;i<=n;i++)p[i]=read(),bj[p[i]]=1,maxx=max(maxx,p[i]),MAXN=max(MAXN,p[i]);
sort(p+1,p+n+1);
for(int i=1;i<=maxx;i++){
if(bj[i])pre[i]=i;
else pre[i]=pre[i-1];
}
for(int i=maxx;i>=1;i--){
if(bj[i])suf[i]=i;
else suf[i]=suf[i+1];
}
for(int i=1;i<=n;i++)pos[p[i]]=i;
for(int i=1;i<=n;i++){
if(p[i]==p[i-1]){
a[++tot]={i,i-1,0};
continue;
}
for(int k=1;k*p[i]<=maxx;k++){
int tmy=0;
if(bj[k*p[i]] and k!=1){
a[++tot]={pos[k*p[i]],i,0};
continue;
}
if(suf[k*p[i]+1]<=(k+1)*p[i])tmy=suf[k*p[i]+1];
if(!tmy)continue;
int cost=abs(k*p[i]-tmy);
a[++tot]={pos[tmy],i,cost};
}
}
sort(a+1,a+tot+1,cmp);
for(int i=1;i<=n;i++)f[i]=i,siz[i]=1;
for(int i=1;i<=tot;i++){
if(find(a[i].from)!=find(a[i].to)){
merge(a[i].from,a[i].to);
ans+=a[i].dis;
}
}
cout<<ans<<endl;
}
return 0;
}
2081E - Quantifier
Idea: chen_03
Move each chip as deep as possible in descending order of labels. Can we simplify the operations after that?
Now we only need to move the chips upward and swap adjacent chips with the same color. What can we do after that?
We can perform dynamic programming (DP) to calculate the numbers. What information do we need to record?
We need to record the color and the length of the top monochromatic segment. How can we perform the DP in $$$\mathcal{O}(m^2)$$$ time complexity?
First, in descending order of labels, move each chip to the deepest possible position successively. It can be shown that this allows each chip to reach the theoretically deepest position it can attain. Consequently, every final state can be obtained from this configuration by performing only upward moves of chips and swaps of adjacent chips with the same color.
Next comes the process of moving chips upward while performing dynamic programming (DP). Let $$$e_u$$$ denote the edge from node $$$u$$$ to its parent. Assume we have decided the order of all the chips in subtree $$$u$$$ (except the ones on $$$e_u$$$), and we need to merge them with the original chips on $$$e_u$$$. If the bottom chip on $$$e_u$$$ shares color with the subtree's top chip, we need to know the length of the subtree's topmost maximal monochromatic contiguous segment to calculate the number of ways to merge the two parts, i.e., if the length of the bottommost segment on $$$e_u$$$ is $$$x$$$ and the length of the topmost segment of the subtree is $$$y$$$, we have $$$\dbinom{x+y}{x}$$$ ways to combine them. So we need to record the color and the length of the top segment.
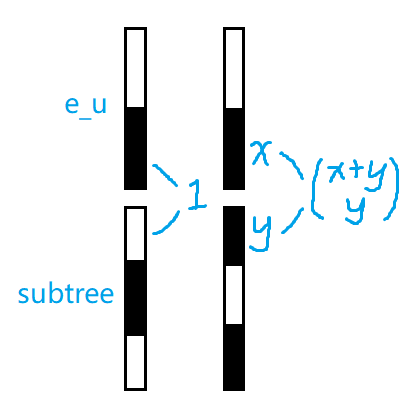
Let $$$f_{u,0/1,i}$$$ denote the number of permutation schemes on $$$e_u$$$ after moving all the chips in subtree $$$u$$$ to $$$e_u$$$, where:
- The topmost chip on $$$e_u$$$ is black/white (0/1).
- The length of the topmost maximal monochromatic contiguous segment on $$$e_u$$$ is $$$i$$$.
When calculating $$$f_{u,0/1,i}$$$ for all $$$i$$$, we first merge the DP states of all the subtrees of node $$$u$$$, and then merge the original chips on $$$e_u$$$ into the resulting DP states.
Subtree merging: Assume we merge two subtrees $$$v$$$ and $$$w$$$. Let $$$S$$$ and $$$T$$$ denote the number of chips on $$$e_v$$$ and $$$e_w$$$ respectively, and let $$$g_{0/1,i}$$$ be a temporary DP array initialized to all zeros.
Let's consider two cases.
Case 1: Different colors at tops of $$$e_v$$$ and $$$e_w$$$
Suppose the top chip comes from $$$e_v$$$ after merging. Then the maximal monochromatic segment length from $$$e_w$$$ becomes irrelevant, and therefore let $$$h_c=\sum_{i=1}^T f_{w,c,i}$$$. If the top chip of $$$e_w$$$ would split the top segment of $$$e_v$$$, enumerate split positions. The split position should be strictly inside the top segment of $$$e_v$$$.
Otherwise, the position of the top chip of $$$e_w$$$ becomes irrelevant.
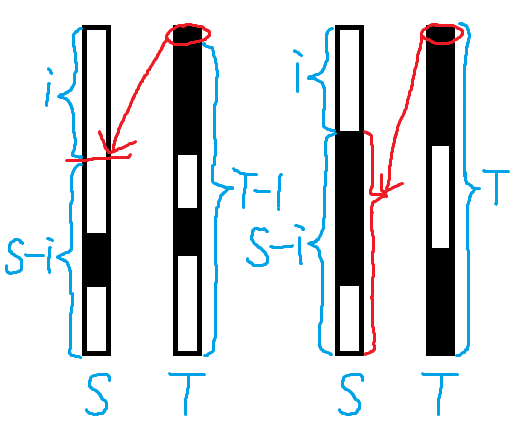
With suffix sum optimization, this achieves $$$\mathcal{O}(m^2)$$$ time complexity.
Case 2: Same color at tops
If there are only chips of this color on both edges:
Otherwise, assume the topmost different-colored chip is from subtree $$$w$$$ after merging. Enumerate insertion positions where this chip splits the top segment of the other (not necessarily strictly inside the segment).
(Similar transition equation for $$$v$$$.)
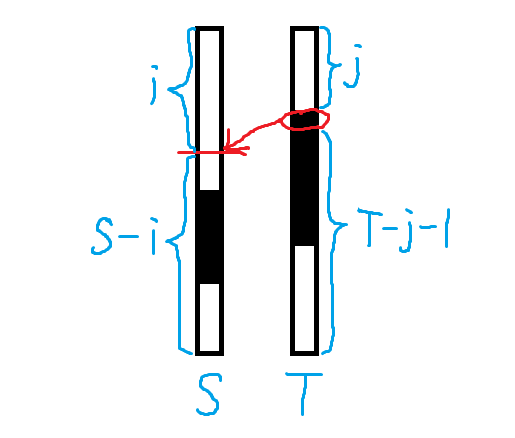
With suffix sum optimization, this forms a tree knapsack DP with $$$\mathcal{O}(m^2)$$$ time complexity.
After computing $$$g_{0/1,i}$$$, we can treat $$$g$$$ as the DP states of a subtree, and continue to perform the process above.
Merging original chips on $$$e_u$$$ into the results: We first account for internal permutations of original monochromatic segments. After that, if the bottom chip on $$$e_u$$$ shares color with merged subtrees' top chip (with segment lengths $$$x$$$ and $$$y$$$), multiply the DP state by $$$\dbinom{x+y}{x}$$$.
Assuming $$$n$$$ and $$$m$$$ are of the same order, the overall time complexity is $$$\mathcal{O}(m^2)$$$.
#include <bits/stdc++.h>
#define eb emplace_back
using namespace std;
typedef long long ll;
const int p=998244353;
int T,n,m,fa[5005],col[5005],d[5005],stk[5005],top,ct[5005][2];
int C[5005][5005],fac[5005],siz[5005],f[5005][2][5005],g[2][5005],ans;
vector<int> to[5005],vec[5005];
inline void diff(int u,int v){
int S=siz[u],T=siz[v];
for(int x=0,A,B;x<2;++x){
A=B=0;
for(int j=1;j<=T;++j)B=(B+f[v][x^1][j])%p;
for(int i=S;i>=1;--i){
g[x][i]=(g[x][i]+((ll)A*C[S+T-i-1][T-1]+(ll)f[u][x][i]*C[S+T-i][T])%p*B)%p;
A=(A+f[u][x][i])%p;
}
}
}
inline void same1(int u,int v){
int S=siz[u],T=siz[v];
for(int x=0,A,B;x<2;++x){
for(int i=1;i<S;++i){
if(!(A=f[u][x][i]))continue;
B=0;
for(int j=T;j>=0;--j){
B=(B+f[v][x][j])%p;
g[x][i+j]=(g[x][i+j]+(ll)A*B%p*C[i+j][j]%p*C[S-i-1+T-j][T-j])%p;
}
}
}
}
inline void same(int u,int v){
same1(u,v),same1(v,u);
int S=siz[u],T=siz[v];
for(int x=0;x<2;++x)
g[x][S+T]=(g[x][S+T]+(ll)f[u][x][S]*f[v][x][T]%p*C[S+T][T])%p;
}
inline void merge(int u,int v){
for(int i=1;i<=siz[u]+siz[v];++i)g[0][i]=g[1][i]=0;
diff(u,v),diff(v,u),same(u,v);
siz[u]+=siz[v];
for(int i=1;i<=siz[u];++i)
f[u][0][i]=g[0][i],f[u][1][i]=g[1][i];
}
void dfs(int u){
siz[u]=0;
for(auto v:to[u]){
dfs(v);
if(!siz[v])continue;
if(siz[u])merge(u,v);
else{
for(int i=1;i<=siz[v];++i)
f[u][0][i]=f[v][0][i],f[u][1][i]=f[v][1][i];
siz[u]=siz[v];
}
}
if(vec[u].empty())return;
int prd=1,L=vec[u].size(),c=vec[u][0],fir=0,lst=0,res=0;
for(int i=0,j=0;i<L;i=j){
while(j<L && vec[u][i]==vec[u][j])++j;
if(i==0)fir=j-i;
if(j==L)lst=j-i;
prd=(ll)prd*fac[j-i]%p;
}
for(int i=siz[u]+1;i<=siz[u]+L;++i)f[u][0][i]=f[u][1][i]=0;
if(!siz[u])f[u][vec[u][L-1]][lst]=prd;
else if(fir==L){
for(int i=siz[u];i>=1;--i){
f[u][c][i+L]=(ll)f[u][c][i]*C[i+L][i]%p*fac[L]%p;
res=(res+f[u][c^1][i])%p;
f[u][c^1][i]=0;
}
for(int i=1;i<L;++i)f[u][c][i]=0;
f[u][c][L]=(ll)res*fac[L]%p;
}
else{
for(int i=1;i<=siz[u];++i){
res=(res+(ll)f[u][c][i]*C[i+fir][i]+f[u][c^1][i])%p;
f[u][0][i]=f[u][1][i]=0;
}
f[u][vec[u][L-1]][lst]=(ll)res*prd%p;
}
siz[u]+=L;
}
int main(){
scanf("%d",&T);
while(T--){
scanf("%d%d",&n,&m);
for(int i=0;i<=n;++i){
to[i].clear(),vec[i].clear();
ct[i][0]=ct[i][1]=0;
}
for(int i=1;i<=n;++i)
scanf("%d",fa+i),to[fa[i]].eb(i);
for(int i=1;i<=m;++i)scanf("%d",col+i);
for(int i=1;i<=m;++i)scanf("%d",d+i);
for(int i=m,u;i>=1;--i){
top=0,u=d[i];
while(u)stk[++top]=u,u=fa[u];
for(int j=top;j>=1;--j){
if(j>1 && !ct[stk[j]][col[i]^1])continue;
vec[stk[j]].eb(col[i]),++ct[stk[j]][col[i]];
break;
}
}
C[0][0]=fac[0]=1;
for(int i=1;i<=m;++i){
for(int j=1;j<=i;++j)
C[i][j]=(C[i-1][j-1]+C[i-1][j])%p;
C[i][0]=1;
fac[i]=(ll)fac[i-1]*i%p;
}
dfs(1),ans=0;
for(int i=1;i<=m;++i)
ans=((ll)ans+f[1][0][i]+f[1][1][i])%p;
printf("%d\n",ans);
}
return 0;
}
2081F - Hot Matrix
Idea: 18Michael
First, it is not difficult to observe that when $$$ n $$$ is odd, a solution exists if and only if $$$ n = 1 $$$.
When $$$ n $$$ is even, a solution always exists.
Consider the following construction:
Let $$$ n = 2m $$$. Use $$$(x, y)$$$ to denote the cell in the $$$ x $$$-th row and $$$ y $$$-th column of the matrix, and assume the top-left corner of the matrix is $$$(1, 1)$$$, while the bottom-right corner is $$$(n, n)$$$.
For $$$(a, b)$$$ and $$$(c, d)$$$, let $$$ k_1 = c - a $$$ and $$$ k_2 = d - b $$$. When $$$ |k_1| = |k_2| $$$, denote $$$(a, b) \sim (c, d)$$$ as:
- $$$(a, b), (a+1, b+1), \dots, (a+k_1, b+k_2)$$$ if $$$ k_1, k_2 \geq 0 $$$.
- $$$(a, b), (a+1, b-1), \dots, (a+k_1, b+k_2)$$$ if $$$ k_1 \geq 0, k_2 \leq 0 $$$.
- $$$(a, b), (a-1, b+1), \dots, (a+k_1, b+k_2)$$$ if $$$ k_1 \leq 0, k_2 \geq 0 $$$.
- $$$(a, b), (a-1, b-1), \dots, (a+k_1, b+k_2)$$$ if $$$ k_1, k_2 \leq 0 $$$.
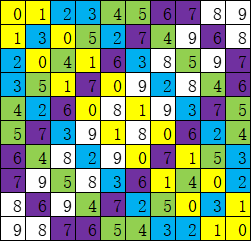
For any $$$ 1 \leq i \leq m $$$, we alternately fill the numbers $$$ 2i-1 $$$ and $$$ 2i-2 $$$ in the cells along the paths $$$(1, 2i) \sim (n-2i+1, n)$$$, $$$(n-2i+2, n) \sim (n, n-2i+2)$$$, $$$(n, n-2i+1) \sim (2i, 1)$$$, and $$$(2i-1, 1) \sim (1, 2i-1)$$$.
An illustration for $$$ n = 10 $$$:
Next, we prove that this construction satisfies all the requirements of the problem:
- Each row and column of $$$ A $$$ is a permutation of $$$ 0 \sim n-1 $$$.
For each $$$ 1 \leq i \leq m $$$, color the cells containing the numbers $$$ 2i-1 $$$ and $$$ 2i-2 $$$ black and white alternately along the paths described above. It can be shown that each row and column contains exactly one black and one white cell, ensuring that $$$ 2i-1 $$$ and $$$ 2i-2 $$$ appear exactly once in each row and column. Thus, each row and column is a permutation of $$$ 0 \sim n-1 $$$.
- $$$ a_{i,j} + a_{i,n-j+1} = n-1 $$$ and $$$ a_{i,j} + a_{n-i+1,j} = n-1 $$$.
From the filling process, the cells containing $$$2i-1$$$ and $$$2i-2$$$ and the cells containing $$$n-2i+1$$$ and $$$n-2i$$$ are symmetric with respect to the midline between the $$$m$$$-th and $$$(m+1)$$$-th rows, as well as the midline between the $$$m$$$-th and $$$(m+1)$$$-th columns. This symmetry further ensures that $$$ 2i-1 $$$ and $$$ n-2i $$$ are symmetric, as are $$$ 2i-2 $$$ and $$$ n-2i+1 $$$. Therefore, both $$$ a_{i,j} + a_{i,n-j+1} = n-1 $$$ and $$$ a_{i,j} + a_{n-i+1,j} = n-1 $$$ are satisfied.
- All ordered pairs $$$ \langle a_{i,j}, a_{i,j+1} \rangle $$$ (for $$$ 1 \leq i \leq n, 1 \leq j < n $$$) are distinct, and all ordered pairs $$$ \langle a_{i,j}, a_{i+1,j} \rangle $$$ (for $$$ 1 \leq i < n, 1 \leq j \leq n $$$) are distinct.
For each $$$ 1 \leq i \leq m $$$, divide the cells containing $$$ 2i-1 $$$ and $$$ 2i-2 $$$ into four categories:
- First category: $$$(1, 2i) \sim (n-2i+1, n)$$$
- Second category: $$$(n-2i+2, n) \sim (n, n-2i+2)$$$
- Third category: $$$(n, n-2i+1) \sim (2i, 1)$$$
- Fourth category: $$$(2i-1, 1) \sim (1, 2i-1)$$$
For any $$$ 1 \leq i < j \leq m $$$:
- The first and third category cells of $$$ 2i-1, 2i-2 $$$ do not neighbor the first and third category cells of $$$ 2j-1, 2j-2 $$$ (since the sum of their coordinates is odd).
- The second and fourth category cells of $$$ 2i-1, 2i-2 $$$ do not neighbor the second and fourth category cells of $$$ 2j-1, 2j-2 $$$ (since the sum of their coordinates is even).
- The second and fourth category cells of $$$ 2i-1, 2i-2 $$$ do not have row-wise neighbors with the first and third category cells of $$$ 2j-1, 2j-2 $$$, and the first and third category cells of $$$ 2i-1, 2i-2 $$$ have exactly $$$2$$$ pairs of row-wise neighbors with the second and fourth category cells of $$$ 2j-1, 2j-2 $$$ (this can be visualized and proven through diagrams).
Specifically:
The first category cells of $$$ 2i-1, 2i-2 $$$ and the second category cells of $$$ 2j-1, 2j-2 $$$ have exactly 2 pairs of row-wise neighbors:
- $$$ a_{n-i-j+1,n+i-j} = 2i-2 + ((i+j+1) \bmod 2), a_{n-i-j+1,n+i-j+1} = 2j-2 + ((i+j+1) \bmod 2) $$$
- $$$ a_{n-i-j+2,n+i-j+1} = 2i-2 + ((i+j) \bmod 2), a_{n-i-j+2,n+i-j} = 2j-2 + ((i+j) \bmod 2) $$$
The first category cells of $$$ 2i-1, 2i-2 $$$ and the fourth category cells of $$$ 2j-1, 2j-2 $$$ have exactly 2 pairs of row-wise neighbors:
- $$$ a_{j-i,i+j-1} = 2i-2 + ((i+j) \bmod 2), a_{j-i,i+j} = 2j-2 + ((i+j+1) \bmod 2) $$$
- $$$ a_{j-i+1,i+j} = 2i-2 + ((i+j+1) \bmod 2), a_{j-i+1,i+j-1} = 2j-2 + ((i+j) \bmod 2) $$$
The third category cells of $$$ 2i-1, 2i-2 $$$ and the second category cells of $$$ 2j-1, 2j-2 $$$ have exactly 2 pairs of row-wise neighbors:
- $$$ a_{n+i-j+1,n-i-j+2} = 2i-2 + ((i+j) \bmod 2), a_{n+i-j+1,n-i-j+1} = 2j-2 + ((i+j+1) \bmod 2) $$$
- $$$ a_{n+i-j,n-i-j+1} = 2i-2 + ((i+j+1) \bmod 2), a_{n+i-j,n-i-j+2} = 2j-2 + ((i+j) \bmod 2) $$$
The third category cells of $$$ 2i-1, 2i-2 $$$ and the fourth category cells of $$$ 2j-1, 2j-2 $$$ have exactly 2 pairs of row-wise neighbors:
- $$$ a_{i+j,j-i+1} = 2i-2 + ((i+j+1) \bmod 2), a_{i+j,j-i} = 2j-2 + ((i+j+1) \bmod 2) $$$
- $$$ a_{i+j-1,j-i} = 2i-2 + ((i+j) \bmod 2), a_{i+j-1,j-i+1} = 2j-2 + ((i+j) \bmod 2) $$$
From the above analysis and by enumerating the parity of $$$i+j$$$, it is clear that all ordered pairs $$$ \langle a_{i,j}, a_{i,j+1} \rangle $$$ (for $$$ 1 \leq i \leq n, 1 \leq j < n $$$) are distinct, and all ordered pairs $$$ \langle a_{i,j}, a_{i+1,j} \rangle $$$ (for $$$ 1 \leq i < n, 1 \leq j \leq n $$$) are distinct.
In conclusion, we have provided a construction for even $$$ n $$$ and proven that it satisfies all the problem's requirements.
The time complexity is $$$O(\sum n^2)$$$.
#include<bits/stdc++.h>
using namespace std;
int Test_num,n;
int a[3002][3002];
void solve()
{
scanf("%d",&n);
if(n>=3 && (n&1))return (void)(puts("NO"));
puts("YES");
if(n==1)return (void)(puts("0"));
for(int i=0;i<n;i+=2)
{
for(int j=1;j<=i+1;++j)a[j][i+2-j]=i+((j&1)^1);
for(int j=i+2;j<=n;++j)a[j][j-i-1]=i+((j&1)^1);
for(int j=1;j<=n-i-1;++j)a[j][i+1+j]=i+(j&1);
for(int j=n-i;j<=n;++j)a[j][2*n-i-j]=i+(j&1);
}
for(int i=1;i<=n;++i)for(int j=1;j<=n;++j)printf("%d%c",a[i][j],j==n? '\n':' ');
}
int main()
{
for(scanf("%d",&Test_num);Test_num--;)solve();
return 0;
}
2081G1 - Hard Formula
Idea: Prean
If $$$g'(np)\neq g'(n)$$$ , then $$$p\le n$$$ unless $$$n=2,p=3$$$ or $$$n=1,p=2$$$ .
Think about the method of $$$\min 25$$$ sieve.
We define $$$\displaystyle g(n)=\frac n{\varphi(n)}=\prod_{p|n}\frac p{p-1},g'(n)=\lfloor g(n)\rfloor$$$.
It's easy to see that $$$res=\frac{N(N+1)}2-\sum_{i=1}^Ng'(i)\varphi(i)$$$.
Let's consider how to calculate $$$\sum_{i=1}^Ng'(i)\varphi(i)$$$.
$$$\texttt{Key observation 1}$$$:if $$$g'(np)\neq g'(n)$$$, then $$$p\le n$$$ unless $$$n=2,p=3$$$ or $$$n=1,p=2$$$.
if $$$p=n+1$$$, then $$$\dfrac{x+n}x=n+1\implies x=1\implies \left(1+\left\lfloor \dfrac n{\phi(n)}\right\rfloor\right)\varphi(n) = n+1 \implies \varphi(n)\mid n+1$$$.
if $$$n\gt 2$$$ then $$$\varphi(n)\ge 2$$$, but $$$\varphi(n)\mid n+1=p$$$, which is contradict the fact that $$$p$$$ is a prime number.
The case of $$$n\le 2$$$ is easy to check.
Therefore, all the prime factors $$$p$$$ that $$$\gt \sqrt N$$$ wouldn't change the number of $$$g'(n)$$$.
Use a linear sieve to find all the prime numbers $$$\le \sqrt N$$$, following the approach for handling composite numbers in the min25 sieve:
Let's define:
When $$$p\leq\frac{n+(\varphi(n)-n\mod\varphi(n))}{\varphi(n)-n\mod\varphi(n)}$$$, there is $$$g'(np)=g'(n)+1$$$, otherwise $$$g'(np)=g'(n)$$$.
Pre-calculate the prefix of $$$\varphi(p)$$$ among prime numbers, we can calculate $$$s(n,k)$$$ like this:
The answer is $$$\frac{N(N+1)}{2}-1-S(1,1)$$$.
With time complexity $$$\mathcal O\left(\frac{n^{0.75}}{\log n}\right)$$$, it could pass the test cases of $$$N\le 10^{11}$$$.
#include<cstdio>
#include<cmath>
typedef unsigned long long ull;
typedef unsigned uint;
const uint M=1e6+5;
ull N;const uint ANS[11]={0,0,0,1,1,2,2,3,3,6,8};
uint B,n4,top,pri[M],F0[M],F1[M],G0[M],G1[M],SF[M],SG[M];
inline ull Div(const ull&n,const ull&m){
return double(n)/m;
}
inline ull min(const ull&a,const ull&b){
return a>b?b:a;
}
inline uint DFS(const ull&n,uint k,const ull&phi){
const ull&T=Div(N,n);
const uint&g=int(n*1./phi),&R=min(Div((g+1)*phi,(g+1)*phi-n),min(ull(B),T));
uint ans=0;
if(k>top)ans=T<=B?0:g*phi*(SF[n]-SG[B]);
else if(pri[k]>T)ans=0;
else if(pri[k]<=R)ans=g*phi*((n<=B?SF[n]:SG[T])-SG[R])+(g+1)*phi*(SG[R]-SG[pri[k-1]]);
else ans=g*phi*((n<=B?SF[n]:SG[T])-SG[pri[k-1]]);
for(;k<=top;++k){
const uint&p=pri[k],&w=p<=R?g+1:g;if(1ull*p*p>T)break;
for(ull x=n,tp=phi*(p-1);x*p<=N;tp*=p)ans+=DFS(x*=p,k+1,tp)+w*tp;
ans-=w*phi*(p-1);
}
return ans;
}
signed main(){
scanf("%llu",&N);
if(N<=10)return!printf("%d",ANS[N]);B=sqrt(N);n4=sqrt(B);
for(uint i=1;i<=B;++i){
const ull&w=Div(N,i);
F0[i]=w-1;F1[i]=w*(w+1)/2-1;
G0[i]=i-1;G1[i]=i*(i+1ull)/2-1;
}
for(uint p=2;p<=n4;++p)if(G0[p]!=G0[p-1]){
const uint&lim=Div(B,p),&S0=G0[p-1],&S1=G1[p-1];pri[++top]=p;
for(uint k=1;k<=lim;++k){
F0[k]-=F0[k*p]-S0;F1[k]-=p*(F1[k*p]-S1);
}
for(uint k=lim+1;k<=B;++k){
const uint&x=Div(N,k*p);F0[k]-=G0[x]-S0;F1[k]-=p*(G1[x]-S1);
}
for(uint k=B,e=lim;e>=p;--e)for(uint x=e*p,V0=G0[e]-S0,V1=p*(G1[e]-S1);k>=x;--k){
G0[k]-=V0;G1[k]-=V1;
}
}
for(uint p=n4+1;p<=B;++p)if(G0[p]!=G0[p-1]){
const uint&lim=Div(B,p),&T=Div(N,1ll*p*p),&S0=G0[p-1],&S1=G1[p-1];pri[++top]=p;
for(uint k=1;k<=lim;++k){
F0[k]-=F0[k*p]-S0;F1[k]-=p*(F1[k*p]-S1);
}
for(uint k=lim+1;k<=T;++k){
const uint&x=Div(N,k*p);F0[k]-=G0[x]-S0;F1[k]-=p*(G1[x]-S1);
}
}
for(uint i=1;i<=B;++i)SF[i]=F1[i]-F0[i],SG[i]=G1[i]-G0[i];
printf("%u",N*(N+1)/2-1-DFS(1,1,1));
}
2081G2 - Hard Formula (Hard Version)
Idea: Prean
Consider the DFS structure of $$$\min 25$$$ sieve.
What kind of nodes are important?
How many of nodes are important?
Consider using Du Sieve to get some important functions.
For further optimization, let's consider the DFS tree of $$$\min25$$$ sieve: $$$N$$$ vertices, rooted on $$$1$$$, the father of a node $$$d$$$ is $$$\frac{d}{\text{maxp}(d)}$$$ where $$$\text{maxp}(d)$$$ denotes the maximum prime factor of $$$d$$$.
Consider all the positions $$$d$$$ that $$$g'(d)\neq g'(fa_d)$$$. Let's divide them into two cases:
- $$$d$$$ is a leaf, which means $$$d\le N\lt d\times \operatorname{maxp}(d)$$$.
- $$$d$$$ is not a leaf, which means $$$d\times \operatorname{maxp}(d)\le N$$$.
The answer could be calculated like this:
where $$$G(d,p)$$$ denotes the sum of $$$\varphi$$$ in the subtree of node $$$d$$$, and $$$G(d,p)$$$ could be calculated like this:
We could use DFS to search all the nodes $$$d$$$ which satisfy case 2, and we can calculate its contribution to the answer during our DFS.
For a non-leaf node $$$u$$$, let's consider its child nodes $$$up$$$ which satisfy case 1.
It's easy to see that $$$p$$$ is in an interval, which allows $$$O(1)$$$ calculation of the contributions of these nodes.
As a result, we get the number of nodes $$$d$$$.
//pi[n] means the number of prime number <=n
//Sp[k] The prefix sum of phi(p) among the first k prime numbers
//g[k]=(pri[k]-1.0)/pri[k]
inline ull div(ull n,ull m){
return n*1./m;
}
inline bool check(double P,ull n,uint k){
ull x(1);while(P>1&&k<=m&&x*pri[k]<=n)P*=g[k],x*=pri[k++];return P>1;
}
bool DFS1(ull n,uint k,ull phi){
const ull T=div(N,n);const uint w=int(1.*n/phi)+1;
if(check(w*phi*1./n,T,k))return true;
//if the g' would not change in the subtree, return directly
const uint R=pi[min(div(w*phi,w*phi-n),min(ull(B),T))];
//g(n)*p/(p-1)>=int(g(n))+1
for(;k<=m;++k){
const uint&p=pri[k];if(p*p>T)break;
if(k<=R)d[k].push_back(nb(n,phi)),n*p<=K&&(lim=max(lim,k));
for(ull x=n,tp=phi*(p-1);x*p<=N;tp*=p)if(DFS1(x*=p,k+1,tp))break;
//The subtree of np^e is isomorphic to the subtree of np^(e+1) , so if we didn't find in the previous one, we do not need to dfs into the latter one
//This will not effect the efficiency significantly since dfs is not the efficiency bottleneck
}
if(k<=R)sum+=phi*(Sp[R]-Sp[k-1]);
//The contribution of its child nodes which is leaf
return false;
}
| $$$N$$$ | The number of non-leaf nodes satisfy $$$g'(d)\neq g'(fa_d)$$$ | Time to DFS (tested in i9-14900HX) |
|---|---|---|
| $$$10^{10}$$$ | 78370 | 0.007s |
| $$$10^{11}$$$ | 285027 | 0.021s |
| $$$10^{12}$$$ | 1074403 | 0.085s |
| $$$10^{13}$$$ | 4010656 | 0.505s |
Let's consider how to calculate $$$G(d,p)$$$. Define:
where $$$\text{minp}(i)$$$ denote the minimum prime number of $$$i$$$.
Then we can see that:
It's easy to see that $$$F_0(x)=\frac{\zeta(x-1)}{\zeta(x)}$$$, we can use Du Sieve to get all the $$$f_0(\lfloor \frac Nd\rfloor)$$$ in $$$O(N^{\frac 23})$$$.
According to $$$\texttt{Key observation 1}$$$, $$$\forall d\notin{2,6},\mathrm{maxp}(d)\leq\sqrt d$$$.
Let $$$k=\max_{g'(d)\neq g'(fa_d)\And d\leq B}(\mathrm{maxp}(d))$$$, categorize these nodes $$$d$$$ again:
- (i) $$$\mathrm{maxp}(d)\leq k$$$, Then $$$\mathrm{maxp}(d)\leq \sqrt B$$$.
- (ii) $$$\mathrm{maxp}(d)>k$$$, then $$$B\leq\mathrm{maxp^2(d)}\leq d$$$, $$$\lfloor\frac{N}{d}\rfloor<\frac NB$$$.
For those $$$d$$$ satisfy condition (i), let's begin with $$$f_0$$$, delete the prime numbers from small to large, until $$$f_k$$$ and calculate the contributions of these $$$d$$$.
We could use Dirichlet convolution to calculate $$$f_{p+1}$$$ from $$$f_p$$$.
Step 1:
Step 2:
These could solve in $$$O\left(\frac{\sqrt N \times \sqrt B}{\log n}\right)$$$.
For those $$$d$$$ satisfy condition (ii), we calculate $$$G(d,p)$$$ in this method:
Because $$$p\geq \sqrt B$$$ and $$$d\geq B$$$, we only need to consider $$$k\le \frac{\log N}{\log B}$$$, which is similar to $$$O(1)$$$.
In this part, we only need $$$f(x)$$$ for $$$x\le B$$$, so to calculate these $$$f$$$ is actually a two-dimensional partial order problem which can be solved using a BIT, time complexity $$$O(\frac NB\log N)$$$.
Since for each $$$d$$$, we get $$$G(d,p)$$$ in $$$O(1)$$$ in case (i), and $$$O(\log N)$$$ in case (ii).
The total time complexity is $$$O\left(N^{\frac 23} + \frac{\sqrt N\times \sqrt B}{\log N}+ \frac NB\log N+D\log N\right)$$$.
Let $$$B=N^{\frac 13}\log^{\frac 43}N$$$, the total time complexity is $$$O\left(N^{\frac 23}+ \frac{N^{\frac 23}}{\log^{\frac 13}N}+D\log N\right)$$$.
Further optimization to $$$n=10^{13}$$$
This part is included in the offline contest.
$$$\texttt{Key observation 2}$$$ : The number of $$$i$$$ in range $$$[1,n]$$$ that satisfy $$$\mathrm{minp}\geq n^{\frac{1}{4}}$$$ is of the order of $$$\frac{n}{\ln n}$$$.
Since we only need to calculate $$$G(\frac{d}{\mathrm{maxp}(d)},\mathrm{maxp}(d))$$$ where $$$\text{maxp}(d)\gt \sqrt B$$$ in case (ii).
We actually only need to consider those $$$\text{minp}(i)\gt \sqrt B$$$, and $$$i\le \frac{d}{\text{maxp}(d)}\le\frac N{\sqrt B}$$$.
Then if $$$B\gt N^{\frac 13}$$$, the actual size to append into the BIT is only $$$O(\frac{N}{B\log N})$$$, so the time complexity of case ii is $$$O(\frac NB)$$$.
Then we could adjust $$$B$$$ to $$$N^{\frac 13}\log^{\frac 23}N$$$, the time complexity could reduce to $$$O\left(\frac {N^{\frac 23}}{\log^{\frac 23}N}+D\log N+N^{\frac 23}\right)$$$.
To further optimize, let's introduce a method that could significantly reduce the time consumption of Du Sieve.
The formula of Du Sieve is $$$\sum_{xy\leq N}f(x)g(y)=S_{f*g}(N)$$$. We can see that $$$\min(x,y)\leq\sqrt{N}$$$, Let $$$B=\lfloor\sqrt{N}\rfloor$$$, the formula could be rewritten like this:
Traditionally, we need $$$[6B,8B]$$$ times of division, but using this method need a maximum of $$$2B$$$ times of division.
As for what we need to calculate in this problem, we can get the formula:
Without using things like $$$\text{std::map}$$$, and use dynamic programming instead of DFS, we can further reduce the time consumption.
Then consider how to optimize Du Sieve to $$$O\left(\frac{N^{\frac{2}{3}}}{\log N}\right)$$$.
Definition: if $$$f$$$ is a multiplicative function, then we define a multiplicative function $$$f_x(p^k)=[p\geq x]f(p^k)$$$.
We can calculate $$$\varphi_{N^{\frac{1}{6}}}(\lfloor\frac {N}{i} \rfloor)$$$ for each $$$i$$$ and then recurrence $$$\varphi$$$ from $$$\varphi_{N^{\frac 16}}$$$. Let $$$n6=N^{\frac{1}{6}}$$$, we can change the formula into:
Where $$$\text{id}(x)=x$$$ and $$$1(x)=1$$$, which can be calculated through $$$\text{min25}$$$ Seive, but we only need to solve $$$p\leq n6$$$ instead of $$$p\leq\sqrt N$$$.
According to $$$\texttt{Key observation 2}$$$, we know that the number of $$$i\le \sqrt N$$$ that satisfy $$$\mathrm{minp}(i)\geq n6$$$ is about $$$\frac{\sqrt N}{\log N}$$$, find them and iterate these numbers in the Du Sieve. The time complexity of this part is $$$O\left(\frac{N^{\frac{2}{3}}}{\log N}\right)$$$.
At last we get a solution of $$$O\left(\frac{N^{\frac{2}{3}}}{\log N}+\frac{\sqrt{NK}}{\log N}+\frac{N}{K}\right)$$$.
#include<bitset>
#include<cstdio>
#include<vector>
#include<cmath>
#include<ctime>
using std::min;
using std::max;
typedef unsigned uint;
typedef unsigned long long ull;
namespace Sol{
const uint M=4162277+5,Pi=1001258+5,M2=500000000+5;
uint sum;ull N;
uint F[M],G[M];
uint top,Sp[Pi],pri[Pi],pi[M],phi[M2];double g[Pi];
uint n4,K,B,m,lim,BIT[M];
double st,ed;
struct nb{
ull n;uint phi;
nb(const ull&n=1,const uint&phi=1):n(n),phi(phi){}
};std::vector<nb>d[Pi];
inline ull div(const ull&n,const ull&m){
return n*1./m;
}
inline void Add(uint n,const uint&V){
while(n<=B)BIT[n]+=V,n+=n&-n;
}
inline uint Qry(uint n){
uint ans(0);while(n)ans+=BIT[n],n-=n&-n;return ans;
}
inline bool check(double P,ull n,uint k){
ull x(1);while(P>1&&k<=m&&x*pri[k]<=n)P*=g[k],x*=pri[k++];return P>1;
}
inline bool DFS1(const ull&n,uint k,const ull&phi){
const ull&T=div(N,n);const uint&w=int(n/phi)+1;
if(check(w*phi*1./n,T,k))return true;
//g(n)*p/(p-1)>=int(g(n))+1
const uint&R=pi[min(div(w*phi,w*phi-n),min(ull(B),T))];
for(;k<=m;++k){
const uint&p=pri[k];if(p*p>T)break;
if(k<=R)d[k].push_back(nb(n,phi)),n*p<=B&&(lim=max(lim,k));
for(ull x=n,tp=phi*(p-1);x*p<=N;tp*=p)if(DFS1(x*=p,k+1,tp))break;
}
if(k<=R)sum+=phi*(Sp[R]-Sp[k-1]);
return false;
}
inline void DFS2(const uint&n,uint k,const uint&phi){
const uint&T=div(B,n);Add(n,phi);
for(;k<=m;++k){
const uint&p=pri[k],&T2=div(B,p);if(p>T)return;
for(uint x=n,tp=phi*(p-1);x<=T2;tp*=p)DFS2(x*=p,k+1,tp);
}
}
void sieve(const uint&n){
phi[1]=1;
for(uint i=2;i<=n;++i){
if(!phi[i]){
phi[i]=i-1;if(i<=B)pri[++top]=i,g[top]=1.*(i-1)/i,Sp[top]=Sp[top-1]+phi[i],pi[i]=1;
}
for(uint x,j=1;j<=top&&(x=i*pri[j])<=n;++j){
phi[x]=phi[i]*(pri[j]-1);if(div(i,pri[j])*pri[j]==i){phi[x]+=phi[i];break;}
}
if(i<=B)pi[i]+=pi[i-1];
}
}
void Getphi(const ull&n){
const uint&B2=div(N,K);
for(uint i=1;i<=B;++i)G[i]=G[i-1]+phi[i];for(uint i=div(N,B);i>=1;--i)F[B]+=phi[i];
for(uint i=B-1;i>B2;--i){
const uint&L=div(N,i+1)+1,&R=div(N,i);F[i]=F[i+1];for(uint k=L;k<=R;++k)F[i]+=phi[k];
}
for(uint i=B2;i>=1;--i){
const ull&T=div(N,i);const uint&lim=sqrt(T);F[i]=lim*G[lim]+T*(T-1)/2;
for(uint k=2;k<=lim;++k){
const uint&x=div(T,k);F[i]-=(i*k<=B?F[i*k]:G[x])+phi[k]*x;
}
}
}
uint Solve(const ull&n){
st=clock();
N=n;B=sqrt(N);n4=sqrt(B);
sieve(K=uint(pow(N,2./3)));m=pi[B];
fprintf(stderr,"sieve(%d) done %lf\n",K,((ed=clock())-st)/1000);st=ed;
DFS1(1,1,1);
fprintf(stderr,"DFS done %lf\n",((ed=clock())-st)/1000);st=ed;
Getphi(N);sum+=F[1];
fprintf(stderr,"Getphi done %lf\n",((ed=clock())-st)/1000);st=ed;
for(uint i=1;i<=lim;++i){
const uint&p=pri[i],&T=B/p;const ull&k=div(N,p);
for(nb&x:d[i])sum+=x.phi*(x.n<=B?F[x.n]:G[div(N,x.n)]);
for(uint i=1;i<=T;++i)F[i]-=p*F[i*p];
for(uint i=T+1;i<=B;++i)F[i]-=p*G[div(k,i)];
for(uint i=B,j=div(i,p);j;--j)for(uint e=j*p,V=p*G[j];i>=e;--i)G[i]-=V;
for(uint i=p,j=1;i<=B;++j)for(uint e=min(i+p,B+1),V=G[j];i<e;++i)G[i]+=V;
for(uint i=B;i>T;--i)F[i]+=G[div(k,i)];
for(uint i=T;i>=1;--i)F[i]+=F[i*p];
for(nb&x:d[i])sum-=x.phi*(x.n<=B?F[x.n]:G[div(N,x.n)]);
}
fprintf(stderr,"case1 done %lf\n",((ed=clock())-st)/1000);st=ed;
Add(1,1);
for(uint i=m;i>lim;--i){
const uint&p=pri[i];
for(nb&x:d[i]){
ull n=N/x.n/p,phi=x.phi*(p-1);
while(n)sum+=phi*Qry(n),n/=p,phi*=p;
}
for(ull x=p,phi=p-1;x<=B;x*=p,phi*=p)DFS2(x,i+1,phi);
}
fprintf(stderr,"case2 done %lf\n",((ed=clock())-st)/1000);st=ed;
return n*(n+1)/2-sum;
}
}
namespace sol{
uint top,pri[10005],pos[10005],phi[10005];
inline uint solve(const uint&N){
uint sum(0);phi[1]=1;
for(uint i=2;i<=N;++i){
if(!pos[i])pri[pos[i]=++top]=i,phi[i]=i-1;
for(uint x,j=1;j<=pos[i]&&(x=i*pri[j])<=N;++j)phi[x]=(pos[x]=j)==pos[i]?phi[i]*pri[j]:phi[i]*(pri[j]-1);
sum+=i%phi[i];
}
return sum;
}
}
signed main(){
ull n;scanf("%llu",&n);if(n<=10000)return printf("%u\n",sol::solve(n)),0;printf("%u\n",Sol::Solve(n));
}






Ecrade_ orzzzzzzzzz!
yinianzhijian orzzzzzzzzz!
Ecrade_ orzzzzzzzzz!
Ecrade_ orzzzzzzzzz!
Ecrade_ orzzzzzzzzz!
Ecrade_ orzzzzzzzzz!
Ecrade_ orzzzzzzzzz!
Ecrade_ orzzzzzzzzz!
the solution in editorial for A is fine and quite understandable but i was expecting to see a proof for the claim, i personally did find it hard to see that the answer is max(r,c), yes changing a cell implies that r and c change by 1 but i dont see how that implies that the minimum number of operations is max(r,c), is there a way to construct this optimal matrix without brute force, maybe by some clever construction?
$$$\max(r,c)$$$ is the lower bound of the answer, since each time we can change $$$r$$$ and $$$c$$$ only by one.
Greedily, if $$$r$$$ and $$$c$$$ are both greater than $$$0$$$, then we should make them both minus $$$1$$$; otherwise, let's assume that $$$r>0$$$ and $$$c=0$$$, then we can only make $$$r$$$ minus $$$1$$$ and $$$c$$$ plus $$$1$$$. This greedy strategy yields the lower bound $$$\max(r,c)$$$.
You can personally perform the strategy on some small tests like $$$r=[0,0,1,1]$$$ and $$$c=[1,1,1,1]$$$, which might be helpful to your understanding.
thanks for the reply! lets say that the lower bound is max(r,c) which makes sense if we greedily reduce r and c, but you haven't proven that it is always possible to transform the matrix into a good one by performing exactly max(r,c) operations or that there always exists a greedy solution, intuitively it feels like the greedy solution shouldnt always exist because +1 is always possible but apparently it does.
Maybe you can create some small tests and apply the greedy solution on them. You may get some inspiration from the process.
div2A was not at all obvious to me. however, I guessed it because I try not to think very hard in div2A but was hoping for better intuitions and maybe a little more understanding of the matrix properties.
div2B seriously made me happy that this round was unrated LMAO, and that carry-over logic by looking at bits does make me understand the solution, thanks. .. although I got div1 this time but I tried to do it virtually for div2
div2A seems very difficult to prove on paper, because the parity of the number of "bad rows" puts some constraints on the parity of the number "bad cols" which are themselves kinda tricky to prove
yes I also figgured out some stuff with parity, but didn't do much thinking because div2A and you loose score for time... I was expecting mention about that in the editorial
just mentioning what is this parity thing — basically non zero XOR means parity of count of 1s is odd.
I also struggled with div2B because I don't how to write ceil division mathematically (x/y+1 [x%y!=0]). But I just changed order of operation in max and min and it worked ^_^
a version of ceil division which people use
ceilDiv(a,b) = (a + (b-1)) / bhere
bis 2 so..(a+1)/2Yeah I got that :) But I was saying I was not been able to prove why my approach because I was not been able to write mathematical equation for ceil division
((x/2)+1)/2 => x/4+1/2 -> apply ceil first
((x/2)/2+1) => x/4+1 -> apply floor first
BTW I have taken above proof from someone's comment
oh ok .. sorry ...
There is a simpler solution for div2B.
Let $$$s_1 s_2 \ldots s_k$$$ be the binary sequence representing floor and ceil operations.
Claim: $$$01$$$ is larger than or equal to $$$10$$$.
Proof:
Greedily sort the sequence of operations. Implement it in 10-20 lines.
P.s. is it just me or was the round very hard? I couldn't actually solve div2B without a hint.
it was hard for me too. after a long time struggled so much with B.
C was also some expectation + dp which I am weak at... :( :(
Wow that's definitely an elegant proof! Thank you for sharing it!
ok, this explanation for div2B is so cool, thanks for sharing this.
now I feel more dumb
Fill in the detailed reasoning steps:
Obviously,operation 1 is no worse than operation 2
can't we do 11? which gives floor( (x + 3 ) / 4 ). which is bigger. how this proves 000....11 is better for max?
The intended solutions of these two problems are very simple and not that hard to guess, and guessing some conclusions is, to some extent, an important skill in programming contests, as you only need to write the code instead of the proof.
yes I am lowkey happy that I saw some tough problem, shows me I need to grind harder. and editorial of B is also very helpful ,thanks for that ... instead of just saying "it is trival to show" LMAO
but why won't these tears stop .... aaaaaaa!!!!!
div2C/div1A: it is noteworthy that a closed form solution exists (that can be derived from the recurrence relation):
so we can just perform right bit shift n-1 and convert the remaining value int a integer + n-2?
How did you derive this from the recurrence relation?
Can someone explain the recurrence relation mentioned in Div2 C or Div 1 A Math Division problem?
if the i'th least significant bit is 1, why is it 1/2 * (1 — f(i-1)) + f(i-1)?
Assume that the current bit is $$$1$$$. If a carry-over occurs in the previous bit (with probability $$$f_{i-1}$$$), then a carry-over always occurs in the current bit; otherwise, if a carry-over doesn't occur in the previous bit (with probability $$$1-f_{i-1}$$$), then a carry-over occurs in the current bit only when we perform the ceil operation.
Thanks!very interesting problem
.
You can also turn off your brain in Div1-A and just calculate the probability of which bit is in position and whether there is a transition through the digit
It feels like I'm a clown after reading how simple the editorial solution is for D1A-D2C (vs my solution — the turn off brain one).
Oh well, Today I learn.
Can someone please explain solution for problem B. I am not able to understand :( what is meant by this term "carry over"
it just means that can a 1 survive after the operation
so you can
carry over1 towards right with ceil, but you can't do it with floor.to get max value we want to carry over, for min we don't want to carry over
Proud of my solution -> read editorial -> cry.
can someone tell me why does the following approach fail for div2B?
we repeat the same steps to find maximal value but with just one change, we use type 2 operation when x is odd and type 1 operation otherwise.
At first my idea is that too, but turns out that it's not. And yeah, it's hard to see that why it's wrong. Consider the test case:
1
11 1 2
The problem with that greedy idea is that, sometimes, “burning” straight away a type 1 operation could lead to “burning” one of your floor operations when it would be more beneficial to delay it. In this test case:
If you use Type 1 first (since it's odd), then you are left with 5. But when you must do two other Type 2 operations, it becomes 3 and 2.
But the optimal solution should be you use two Type 2 operations first, which leads to 6 and 3. Then, if you do a Type 1, you will yield the minimum value which is 1, not 2.
I think most of the people thought about the "even/odd" greedy idea, and it certainly is hard to know why it's wrong.
thanks for the counter example and the explanation!
i guess thinking specifically in terms of bits does help in this particular problem.
I might be mistaken, but shouldn't $$$l$$$ in Div1B/Div2D be ceil instead of floor?
Yes you're right! Sorry for my mistake and thank you for pointing it out!
B was really cool. I originally thought that having to save floors for the end to reach 0 when finding min was an edge case but after thinking about binary it makes way more sense. To find the min you use ceil because ceil stacks / carries over all the 1's in the binary representation of the number and moves them left. This allows you to minimize the number of ones and have a better chance of using the floors to cut off all the 1's and make the number 0. Conversely, for max you want to keep as many 1's as possible so the floor won't be able to get to 0 and the max will be as big as possible. Great problem despite the technical difficulties, thanks for the round!
plz somebody explain me c Didn't get a single word in the editorial can somebody explain me plz with good examples
thanks for the contest Ecrade_
Div1 B, C, D, E are all good problems I think. (cant comment about F and G felt not that since especially since hardcoding solutions exist)
Thank you too for your huge support! Much love bro!
in Div1B why cant it be the case that instead of first and last elements we choose some other pair whose values have been changed. Why is it only valid if we can do the first and last element in the end.
div2B was very interesting
Although I couldn’t solve any problems (I can generally solve 2 problems in Div-2), the problems were really cool.
There also exists a $$$O(n\log^2n)$$$ solution in Div1 D using the Boruvka algorithm. It's much more difficult to implement than the official editorial, but sadly without any brain I can't notice the key observasion :(