


Теоретическая база
Если вы давно решаете задачи Div1-Div2 на Codeforces, то наверняка уже слышали про дерево отрезков. Звучит возможно для кого-то страшно и не понятно, но на деле это очень полезная структура данных. Проще говоря, дерево отрезков — это такое бинарное дерево, в узлах которого хранятся агрегированные данные о каком-то отрезке массива. За счёт этой древовидной структуры мы можем быстро отвечать на запросы о произвольных сегментах массива да и не только отвечать, но и обновлять элементы.
Представьте, что у нас есть массив, и требуется многократно узнавать что-то про подотрезки этого массива, например, сумму элементов, минимум, максимум, количество каких-то значений и т.д. Дерево отрезков позволяет делать такие запросы очень быстро — обычно за O(log n) на каждый запрос вместо тривиального O(n) перебора. При этом оно достаточно гибкое, поддерживает изменение отдельных элементов, а с дополнительными трюками (ленивые пропагации) может даже массово обновлять целые диапазоны за то же логарифмическое время. В общем, дерево отрезков может довольно хорошо оптимизировать алгоритм программы, когда обычных массивов и сортировок уже не хватает.
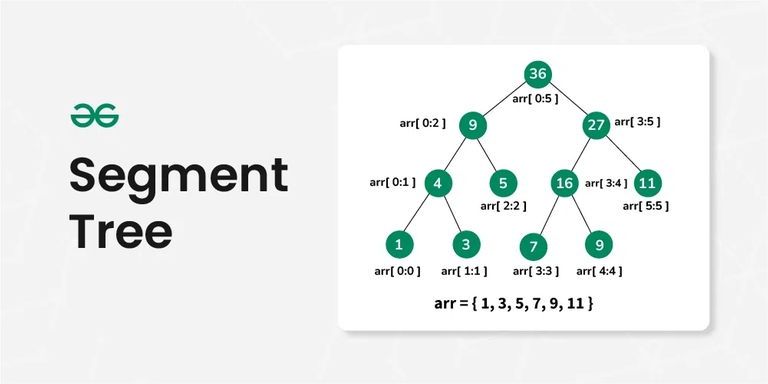
Пример дерева отрезков, построенного для массива arr = {1, 3, 5, 7, 9, 11}. Каждый узел хранит сумму на соответствующем отрезке: корень содержит 36 (сумма на всём отрезке [0;5]), его дети – суммы на [0;2] и [3;5] (9 и 27) и так далее.
Как это работает?
Мы рекурсивно делим массив пополам, пока не дойдём до отдельных элементов. Эти элементы — листья дерева. Затем начинаем “склеивать” информацию снизу вверх: каждый внутренний узел вычисляется из двух дочерних. Например, если нам нужны суммы, то значение узла = сумма левого сына + сумма правого сына. Если нужны минимумы — берём минимум из двух детей, и т.д. В итоге корень хранит агрегат (сумму/мин/макс и пр.) по всему массиву, а путь от корня к листу соответствует делению отрезка на подотрезки.
Когда это нужно?
Дерево отрезков может быть использовано, когда: 1. Нужно эффективно отвечать на запросы о подмножествах элементов массива (сумма на отрезке, максимум на отрезке, НОД на отрезке и т.п.) и при этом между запросами могут происходить изменения отдельных элементов или целых диапазонов, то есть данные динамические. В таком случае простое предвычисление всех ответов не поможет 2. Запросов и обновлений много (десятки и сотни тысяч) и делать их за линейное время слишком медленно
Дерево отрезков обеспечивает (log n) на один запрос или обновление, что обычно укладывается в лимиты при n и количестве запросов порядка 10^5. При этом его память ~4*n элементов для массива размера n — тоже вполне ок.
Примеры задач, решаемых деревом отрезков
Диапазонные суммы, поиск минимума/максимума на отрезке, количество определённых элементов на отрезке, проверка упорядоченности сегмента, даже поиск k-го по счёту элемента. Например, с помощью дерева отрезков можно легко узнать, сколько нулей в заданном диапазоне или найти индекс k-го нуля в массиве. Кстати, именно такую задачу мы сейчас рассмотрим на практике.
Практическая часть
Давайте на примере рассмотрим задачу 2075F - Красивая последовательность возвращается с недавнего контеста Educational Codeforces Round 176 (Rated for Div. 2), решив её при помощи дерева отрезков и проведём аналогию в сравнении с решением "в лоб".
Рассмотрим решение данной задачи от wishgoodluck — 311252841. Идея данного алгоритма основана на «событийном подходе». Мы предварительно вычисляем два массива (назовём их l и r), которые фиксируют важные границы в исходной последовательности. Эти массивы помогают определить, для каких отрезков происходит «изменение» (увеличение или уменьшение вклада в итоговый ответ). Затем формируется вектор событий — каждый элемент этого вектора задаёт, что на определённом отрезке надо добавить или убрать некоторое значение. В финале итоговая длина искомой последовательности получается как максимальное суммарное изменение.
Ключевая задача заключается в том, чтобы быстро и эффективно обрабатывать множество событий, которые влияют на диапазоны индексов. Именно для этого и используется дерево отрезков.
В данном решении дерево отрезков применяется для двух операций:
- Диапазонное обновление (Range Update). Каждое событие из вектора v задаёт, что на отрезке [l,r] нужно прибавить либо +1, либо -1. Дерево отрезков с ленивыми обновлениями позволяет за O(log n) за одно событие обновить сразу весь отрезок, не проходясь по каждому элементу отдельно.
- Запрос максимума (Range Query). После каждого обновления нам нужно быстро узнать, каково максимальное значение на всём диапазоне. Корень дерева (Tree[1].v) всегда хранит максимум среди всех элементов. Это позволяет мгновенно (за O(1) после O(log n) обновлений) узнать текущее оптимальное значение, которое потом используется для вычисления ответа.
Таким образом, дерево отрезков здесь выступает как «агрегатор» всех событий, аккумулируя их влияние на заданных отрезках и позволяя быстро находить максимум.
Представьте себе задачу, где нужно на каждом шаге для каждого события обновить все элементы отрезка. Если диапазон имеет длину m, то наивное обновление занимает O(m) операций. При m∼n и O(n) событиях получаем O(n^2) операций. Это решение быстро станет неприемлемым по времени даже для средних размеров входных данных.
В отличие от этого, дерево отрезков позволяет обновлять целые диапазоны за O(log n) благодаря ленивой пропагации. Таким образом, даже если событий много, общая сложность становится O(n*log n).
Подводные камни и советы
Дерево отрезков — штука мощная, но при реализации можно допустить несколько типовых ошибок:
- Неправильное слияние результатов. Забудете, что нужно суммировать детей, или перепутаете левый/правый и вся логика разрушится. Внимательно определяйте, что хранит узел, и как это получается из информации детей.
- Границы отрезков. Легко ошибиться с индексами left, right и middle. Условились, что сегмент [left..right] включительный. Тогда middle = (left+right)/2 – левая часть [left..middle], правая [middle+1..right]. Если забудете +1 где нужно – получите перекрывающиеся или пропущенные индексы. Совет: отладьте на маленьком массиве, например, n=4 и выпишите на бумажке сегменты каждого узла, проверьте, что покрывают массив без пробелов и наложений.
- Рекурсия vs итерация. Мы рассмотрели рекурсивное решение для простоты понимания, но при n ~ 10^5 глубина рекурсии ~17 – это ок, а вот если бы n ~ 10^7, глубина ~24, всё ещё ок. При сильно больших n и особенно при большом количестве операций иногда предпочитают итеративные реализации во избежание накладных расходов и риска переполнения стека.
- Ленивые обновления. В нашем примере мы как раз их использовали, обновляя сразу целый диапазон. Обратите внимание, что реализация ленивых тегов сложнее — легко напутать с распространением изменений на детей. Если задача требует дерево отрезков с lazy, тестируйте на более простых примерах. Типичные ошибки: забыли запушить лейзи-тег перед дальнейшим спуском или перед подсчётом в узле — получите некорректные данные. Совет: написать отдельную функцию push(v) для распространения тега из узла v на детей, и вызывать где нужно, например перед переходом в поддеревья.
- Выбор между Fenwick (BIT) и деревом отрезков. Часто они взаимозаменяемы для простых задач на суммы, порядковую статистику. Fenwick легче кодится и требует памяти, но дерево отрезков более универсально, поддерживает сложные операций слияния. Если задача допускает Fenwick и вы не хотите тратить время на реализацию дерева — дерзайте с Fenwick, однако дерево отрезков must know для Div1-Div2 уровня.
Напоследок дам небольшой лайфхак — если задача просто требует многократных запросов суммы на отрезке без обновлений, то и дерево отрезков не нужно, достаточно просто будет заранее посчитать префиксные суммы за O(n) и потом каждый запрос обрабатывать за O(1).
Спасибо тем, кто дошёл до конца, удачного программирования :)
Предлагайте в комментариях, о чём мне ещё написать в следующем посту и какие темы ещё стоит изучить.







Auto comment: topic has been translated by Sunb1m (original revision, translated revision, compare)
Автокомментарий: текст был обновлен пользователем Sunb1m (предыдущая версия, новая версия, сравнить).
Thanks for it being very helpful for me
Thanks for your blog, it's really helpful for who wants to learn Segment Tree.
However, I believe there's a typo in the title, it's Segment Tree instead of Segmented tree.
agreed
Thank you! Sorry for my english, I don't have enough knowledge of it to write big texts fluently, so I have to use deepl.com translator. Even now when writing this reply I use it :)
No worries at all! Your message is perfectly understandable, and using a translator is a great way to communicate. Your English is already very good, and I appreciate your effort!
Auto comment: topic has been updated by Sunb1m (previous revision, new revision, compare).
Сегментное дерево, кровь из глаз!