


→ Pay attention
→ Streams
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3857 |
| 2 | jiangly | 3747 |
| 3 | orzdevinwang | 3706 |
| 4 | jqdai0815 | 3682 |
| 5 | ksun48 | 3591 |
| 6 | gamegame | 3477 |
| 7 | Benq | 3468 |
| 8 | Radewoosh | 3463 |
| 9 | ecnerwala | 3451 |
| 10 | heuristica | 3431 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 166 |
| 2 | -is-this-fft- | 161 |
| 3 | Qingyu | 160 |
| 4 | Dominater069 | 159 |
| 5 | atcoder_official | 157 |
| 6 | adamant | 155 |
| 7 | Um_nik | 152 |
| 8 | djm03178 | 151 |
| 9 | luogu_official | 150 |
| 10 | awoo | 148 |
→ Find user
→ Recent actions






Codeforces (c) Copyright 2010-2025 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Mar/04/2025 02:19:50 (j3).
Desktop version, switch to mobile version.
Supported by

Now test to see how large the N has to be for it to be faster than segment trees ;p Though I have to admit, I didn't think it could be made so compact.
Well for N=100000 it is definetely faster :D To test it just overload the < operator and there you go. You can use it with everything as long as you overload < operator. The query returns the position of the minimum.
And I didnt try to optimize it. I just stopped coding when it worked
I think it is faster for N>15000 or something like that. I looked at 282-1-D(birthday) problems test cases
That looks really nice :)
I know
You split array into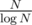 blocks of size
blocks of size  , then build sparse table for each block and for all
, then build sparse table for each block and for all 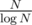 blocks. Am I right?
blocks. Am I right?
Yes you are right
But I dont actually build a sparse table like in regular rmq for the small blocks
then there are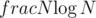 sparse tables, each of size
sparse tables, each of size 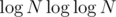 . Therefore total complexity equals to
. Therefore total complexity equals to 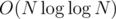 .
.
In order to build O(N) algorithm you have to go further and group blocks by its types, such that blocks with equal types will have equal sparse tables. It is exactly what Farach-Colton and Bender did
İt is not O(N) bits memory. İt is O(N) in a 32bit system.
As you can see I take 4 vectors, one of them holds the data which is O(N) and N/logN integers in another vector, N integers in another one and 2^(logN) integers which is N in another vector so total memory is O(N)
You are wrong with that part. The small blocks arent sparse tables. Please pay more attention to the code
If you are not satisfied please put a variable in every loop and increment it. And test it with different N. You will see a linear increase.
double post
"block" is a sparse table for log(n) blocks of "data". Right? What do "sblock" and "lookup" exactly do?
sblock is small blocks of size logn and it helps us extract the min in constant time from blocks of size logn
Nice One! But not efficient for large value of N.
This is from an ongoing contest.
UPD: Fixed.
actually its efficiency is the same for all N
Read the topic here e-maxx.ru/algo