


The contest is over. I guess it's OK to discuss the problems here.
It appears Ontology is not very difficult to most people. However, I don't even have a smart way to parse the parenthese-expression. All I did is just to generate a huge hash and transverse the relevant elements, and apparently it resulted in TLE. I wonder what kind of tree structure is recommended?
I have the similar issue in best representing the problem with appropriate data structure in Wombats too. Even if I tried randomized optimization, it is hard for me to construct a stuffed animal removal sequence.
What categories of algorithms do these two problems belong to?







Wombats can be solved with max.flow. Build a graph of dependencies (taking i forces us to take j) and solve a closure problem for it.
There are lot of ways to solve Ontology, i did it offline — storing map of prefixes (with hashes instead of original strings) for a subtree and solving all queries in single dfs.
I did in the same way for Ontology problem but instead of storing hashses I stored the string so TL for stress test.
I feel stupid. Not once in my life have I seen the closure problem, and googling it, it seems to be a somewhat standard problem. I guess there'a always more to learn.
For Ontology, can you elaborate a little bit, how you answered the queries? I tried your approach, and during the DFS I merged all of the children's unordered_maps with the parent's, and then answered the queries for that parent. This worked on first 75 test cases, but timed out on the last 25.
As for me, the most difficult problems were the machine learning problems. I got max score on all other ones.
BTW 3 hours before the end of the contest I was 2nd (in prize section). And then suddenly some rejudge happened and I got 5th place. Just 10 points from 3rd place. And 3 hours was really not enough for me to get them. All I want to say, is that doing rejudge 3 hours before week-long contest is not reasonable thing to do
P.S. To tell the truth, if I used some standard Machine Learning algorithm (Neural Network or SVM or smth else) instead of implementing som algorithmic ideas I would probably get much higher score.
Using standard ML algorithms took me to top-10 on both problems. Though I doubt my solutions got any usage pontential.
For the rest of the contest, wombats were too hard for me. I even saw I_love_Tanya_Romanova's comment about using maxflow before the contest was extended, but still did not manage to find a solution.
What were your standard algorithms? For instance, in Labeler problem I tried to learn binary classifiers for every topic based on bigrams, however it brought me slightly more than 100 pnts. With respect to Duplicate, it looks like idea with local sensitive hashing and/or any metric for text comparison + learning of weights(how much every field is important) may work, however I did not have time to submit it. I spent more time on algorithmic problems. (Managed to solve all of them, but I guess it took me more time than for you guys).
Btw, here is my code for Ontology problem. I used persitent segment trees to solve it.
I participated only in 8h version of contest, therefore my approach for Labeler is pretty straightforward.
For every word in input count it frequency and frequency of every topic in all questions where this word occurs (so you'll know how frequent given word is, and how frequent given topic is for given word); then throw away 40-50 most frequent words (because they are "I", "is", "the" etc., and they don't provide any information), and for all other pairs word/topic calculate value occurrences[topic][word]/entries[word] — this value is a score of given topic for every occurence of given word in a query.
After that for every query you just sum up scores of all topics over all words in this query and pick top10. This gives a bit more than 118 points.
I did not solve 'Sorted set', by the way, so overall my points are not good.
Algorithm for duplicate: I transform each question into a string "question_text" + names of topics + "view_count" + "follow_count" + "age". Each pair of questions (training and testing data) is represented as concatenation of strings for individual questions. Then I convert strings into Tf-idf vectors and do Logistic Regression on them. 140.60 points code.
Algorithm for labeler: Each string is converted into Tf-idf vector. I considered constant (250) potential labels for each question. After reading all questions, all useless (not appearing in any set of labels) labels are removed. Then Logistic Regression is applied in OneVsRest strategy (n_labels * (n_labels — 1) / 2 binary classifiers are trained to decide between each pair of labels). After that, some number of labels (based on estimated probability) are written as output. Strangely enough, the best number of them was exactly one label per question. 130.0 points code.
In both problems, I've played with parameters (of Tf-idf, LogR and feature selection) to achive maximum scores, without respect to any 'common sense'. Python's sklearn library provides good implementation of algorithms, so the code is short and easy to write (during the initial 8-hour contest I got 134.67 and 122.63 respectively).
By the way, Logistic Regression was used mainly because it supports sparse matrix representation returned by TfidfVectorizer, and also allows to count probabilities for each class.
good. That was exactly what I meant. But for me using Neural Network for Labelers seems more logical (than Logistic Regression). I will try it now and see the result
I got 130(21th place) on Duplicate and 120(9th place) on Labeler.
And the sad thing is that totally random solution gets 100 on Duplicate
Ontology can be solved online in O(n) with persistent trie and Euler tour technique.
Understanding and coding that solution should be the definition of masochism, but a great one nonetheless :D
Mind sharing the code please? Thanks
I haven't coded it when wrote that comment but well... Just for you, enjoy :) #Z5Qqn9
But now it takes about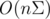 memory and don't pass all the tests :(
memory and don't pass all the tests :( 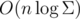 but I definitely don't want to write it :)
but I definitely don't want to write it :)
I believe persistent array in nodes of trie could help us make it
I did with persistent segment tree. How to do it in O(n)?
In Euler tour all descendants of node form continuous subsegment. With persistent trie you can answer the queries on the prefixes. So the answer is get(r) - get(l - 1).
Can you kindly share your code?
Watch the comment above :)
there's some pseudocode:
As for main problem: sort queries by distance of its topic from root; build trie for current topic; merge it with children topics (at each step merge lesser trie into larger); answer query.
I think Schedule is more curious problem. I came up with proper comparator (t1 + p1·t2 > t2 + p2·t1), but how to prove its correctness? Or there is obvious O(n2 or 3) solution?
I've solved the Wombats problem without using flows. The solution is dynamic programming.
Lets divide our tetrahedron into layers. For example, on the image above, the first layer consists of highlighted vertices, the second — of two zeroes on the bottom level and -2 on the blue level, third layer — the only red 1.
So, the layers are 2-dimensional pyramids with heights N, N - 1, ..., 1. Lets see what are the possible subsets of vertices that can be taken from one layer. Lets say our layer is 2D pyramid with height H, then we can divide the pyramid into H columns — first column has size H, second — (H - 1) and so on. Then every possible subset can be described with a non-increasing sequence H ≥ a1 ≥ a2 ≥ a3 ≥ ... ≥ aH, where ai means that we have taken ai topmost vertices from the i-th column. Lets call such a sequence a state of that layer.
The state of the next (smaller) layer depends only on the state of previous (larger) layer and the only condition that should be fulfilled (in addition to the non-increasing condition) is ai ≤ bi for every 1 ≤ i ≤ H, where ai is the state of layer H and bi is the state of layer (H + 1).
So, we can have a dynamic programming solution with S1 + S2 + S3 + ... + SN states, where Sk denotes number of possible states on the layer k. I suppose that Sk grows exponentially, thus we receive O(SN) states. With another (very simple) DP we can find that S12 < 106, so, this is efficient enough.
The transition of this DP is a bit tricky, but not hard, so I will omit it. I can say that the transition can be done in O(N2·SN) time (overall).
PS My code: ideone. Its complexity contains additional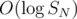 factor that can be reduced, for example, using trie for fast state search.
factor that can be reduced, for example, using trie for fast state search.