


Можно сделать очевидный вывод — наибольшей стоимостью отправки письма из i-го города будет являться максимум из расстояний от i-го города до первого и от i-го города до последнего (max(abs(xi - x0), abs(xi - xn - 1)). А минимальной стоимостью отправки будет являться минимум из расстояний до соседних городов (для i-го города соседними являются города с номерами i - 1 и i + 1), то есть (min(abs(xi - xi - 1), abs(xi - xi + 1)). Для всех городов, кроме самого левого и самого правого, это считается нормально. Так как у самого левого нет соседей левее, значит минимальная стоимость определяются однозначно (abs(xi - xi + 1)). Аналогично для самого правого города (abs(xi - xi - 1)).
567B - Берляндская национальная библиотека
Чтобы корректно обрабатывать события, нам необходимо знать, находится ли в библиотеке на данный момент человек. Для этого будем использовать массив in типа bool. Также заведём две переменные для хранения ответа и "текущего состояния" (в которой будет храниться количество человек, присутствующих в библиотеке на данный момент). Их обозначим ans и state соответственнно.
Итак, если к нам поступает запрос вида " + ai", то мы увеличиваем state на единицу, отмечаем, что этот человек зашёл в читальный зал (in[ai] = true) и пытаемся обновить ответ (ans = max(ans, state)).
Иначе же к нам поступает запрос вида " - ai". В данном случае если человек, который выходит из библиотеки, находился в ней, то нам просто нужно уменьшить state. Иначе мы понимаем, что если этого человека "не было" в библиотеке (in[ai] == false) и он выходит, значит он был в читальном зале ещё до начала рассматриваемого нами промежутка времени. Тогда мы в любом случае должны увеличить ответ на единицу. Также не стоит забывать, что необходимо отметить, что человек вышел из библиотеки (in[ai] = false).
567C - Геометрическая прогрессия
Давайте будем решать эту задачу относительно фиксированного среднего элемента. Это значит, что если мы фиксируем элемент ai, то наша прогрессия должна состоять из элементов вида ai / k, ai, ai·k. Заметим, что прогрессии со средним элементом ai не будет существовать, когда ai не делится нацело на k (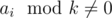 ).
).
При фиксированном среднем члене мы сможем отвечать на запрос вида "сколько существует подпоследовательностей — геометрических прогрессий, средний элемент которых стоит строго в позиции i". Очевидно, что это будет количество элементов слева от i-го, равных ai / k, умноженное на количество элементов, находящихся справа от i-го, равных ai·k. То есть мы можем отвечать на этот вопрос для каждого элемента, если будем знать количества элементов слева и справа от i-го. Для этого можно использовать ассоциативный массив (map). Будем хранить 2 map-a l и r, в l будем поддерживать все элементы строго левее i-го, а в r — строго правее i-го. Если идти по массиву слева направо, то l должен быть пустым, а в r должны быть все элементы. Пройдём циклом по всему изначальному массиву, постепенно обновляя map-ы (очевидно, что перед рассмотрением i-го элемента мы должны удалить его из r, а после рассмотрения — добавить его в l). Если ai будет делиться нацело на k, то добавляем к ответу l[ai / k] * r[ai * k] (стоит заметить, что как при перемножении, так и при обновлении ответа могут случаться переполнения типа int, поэтому проще всего все переменные хранить в long long).
Сначала нам необходимо понять, в каком случае мы можем утверждать, что Алиса соврала. Это случится, когда на поле размера n невозможно будет уместить k кораблей размера a. Для отрезка фиксированной длины len мы можем посчитать максимальное количество кораблей размера a, которые могут уместиться на таком поле. Каждый корабль занимает ровно a + 1 клетку, кроме одного крайнего. Поэтому для отрезка длины len формула для подсчёта будет выглядеть так: 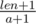 (чтобы не учитывать корабль, который занимает a клеток, а не a + 1, мы просто добавим одну <<фиктивную>> клетку в наш отрезок). Значит, для отрезка [l..r] наша формула должна выглядеть так:
(чтобы не учитывать корабль, который занимает a клеток, а не a + 1, мы просто добавим одну <<фиктивную>> клетку в наш отрезок). Значит, для отрезка [l..r] наша формула должна выглядеть так: 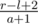 .
.
Для решения задачи нам надо хранить все отрезки [l..r], внутри которых все клетки "свободны" (то есть ни в одну из клеток отрезка не было произведено выстрела). Для удобства их можно хранить в множестве (std: : set), чтобы можно было легко найти нужный отрезок. Итак, будем обрабатывать выстрелы по очереди. Изначально количесво помещающихся кораблей будет равняться 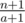 (это значит, что у нас есть один отрезок [1..n]). После каждого выстрела один из отрезков будет либо делиться на два отрезка меньшего размера, либо он будет просто уменьшаться в размере на единицу (если выстрел будет произведён в его край). Таким образом, если выстрел произведён в точку x, относящуюся к отрезку [l..r], то мы должны вычесть из нашего общего количества кораблей их количество на отрезке [l..r], удалить этот отрезок из множества и разделить его на два новых: [l..x - 1] и [x + 1..r] (если выстрел был произведён в край отрезка, тогда добавляется только один новый отрезок) и прибавить к количеству
(это значит, что у нас есть один отрезок [1..n]). После каждого выстрела один из отрезков будет либо делиться на два отрезка меньшего размера, либо он будет просто уменьшаться в размере на единицу (если выстрел будет произведён в его край). Таким образом, если выстрел произведён в точку x, относящуюся к отрезку [l..r], то мы должны вычесть из нашего общего количества кораблей их количество на отрезке [l..r], удалить этот отрезок из множества и разделить его на два новых: [l..x - 1] и [x + 1..r] (если выстрел был произведён в край отрезка, тогда добавляется только один новый отрезок) и прибавить к количеству 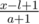 и
и 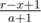 (соответственно, если появляется только один новый отрезок, то необходимо прибавить только одну величину).
(соответственно, если появляется только один новый отрезок, то необходимо прибавить только одну величину).
Если после обработки какого-то из выстрелов количество кораблей стало меньше, чем k, то это означает, что Алиса соврала нам, выводим номер этого хода. Если же после обработки всех выстрелов количество кораблей так и осталось не меньше, чем k, выводим - 1.
Сначала давайте разберёмся, какие рёбра не будут лежать ни на одном кратчайшем пути из s в t. Если запустить два алгоритма поиска кратчайших путей (из вершины s и из вершины t) и сохранить расстояния в массивах d1 и d2 соответственно, можно сделать следующий вывод: если у нас есть ребро (u, v), то оно будет лежать хотя бы на одном кратчайшем пути из s в t тогда и только тогда, когда d1[u] + w(u, v) + d2[v] == d1[t] (где w(u, v) — вес ребра (u, v)).
После того, как мы построили граф кратчайших путей из s в t, мы можем определить, какие из рёбер лежат на всех кратчайших путях. Если представить путь из s в t в виде отрезка [0..D], а расстояния между парами вершин, соединённых рёбрами в этом графе, в виде подотрезков данного отрезка (например, если у нас есть ребро (u, v), тогда данный подотрезок будет иметь вид [d1[u]..d1[v]]), то можно заметить, что все подотрезки каким-то образом касаются других подотрезков (некоторые также могут пересекаться с другими подотрезками). Ребро (u, v) будет лежать на всех кратчайших путях из s в t, если подотрезок [d1[u]..d1[v]] будет только касаться других подотрезков (внутренние пересечения с другими подотрезками недопустимы). Теперь мы можем однозначно отвечать "YES" для этих рёбер.
Остальная часть задачи более простая. Если ребро (u, v) с весом w не лежит на всех кратчайших путях, можно попробовать уменьшить его. Данное ребро будет лежать на всех кратчайших путях только в том случае, если его вес станет равен d1[t] - d1[u] - d2[v] - 1. Итак, если величина d1[t] - d1[u] - d2[v] - 1 (предполагаемый новый вес нашего ребра)строго положительна, тогда мы сможем уменьшить наше ребро так, чтобы оно лежало на всех кратчайших путях, выведем "CAN" и через пробел разность между старым и новым весами ребра. Иначе же выведем "NO".
Представим, что мы выставляем блоки по парам в порядке возрастания их высоты, начиная с левого и правого края. Так, например, два блока высоты 1 мы можем поставить в позиции 1 и 2, либо в позиции 1 и 2n, либо в позиции 2n - 1 и 2n. Отрезок незанятых мест таким образом изменится, и следующая по высоте пара блоков будет выставляться уже в образовавшиеся крайние позиции. В конце концов останутся две свободные позиции, куда необходимо поставить пару блоков высоты n.
Очевидно, вышеописанным способом строится любая корректная последовательность. Попробуем посмотреть на требования к высотам блоков со стороны такого способа построения последовательности. Поскольку блоки мы выставляем в порядке возрастания высот, то неравенства теперь ставят ограничения только на порядок расстановки блоков. Например, требование ''3 >= 5'' теперь означает, что ставить блок в позицию 3 мы можем только лишь если блок в позиции 5 уже поставлен (а значит он имеет меньшую высоту), или же в позициях 3 и 5 блоки нужно ставить одновременно (пара блоков одной высоты).
Для дальнейшего подсчета количества способов воспользуемся идеей динамического программирования. Будем считать dp[l][r] — количество способов поставить блоки, если свободные от блоков места образуют отрезок [l, r]. Высота пары блоков, которая будет ставится в крайние места отрезка однозначно определяется границами этого отрезка. Переберем один из трех вариантов расстановки очередной пары блоков (исключение составляет случай l = = r + 1). Теперь проверим, что такая расстановка не нарушает требования условия задачи. Будем рассматривать только ограничения, касающиеся позиций, на которые ставятся блоки в фиксированном варианте. Для любой "текущей" позиции должно выполняться "<" для любого еще не занятого места (которое находится внутри отрезка [l, r], но не совпадает с одним из двух "текущих" мест), ">" для любого занятого места (вне [l, r]), а ''='' выполняться только в случае сравнения двух "текущих" мест.
Такое динамическое программирование проще всего считать рекурсивно, "ленивой" динамикой.







Can you please provide me test case 61 or help me with this submission getting WA. http://codeforces.net/contest/567/submission/12359031
ct map stores count of numbers from right to left, mapp stores count of x and x * k in right. I changed the order of updating of mapp, ct and ans and got AC. http://codeforces.net/contest/567/submission/12377229
in last cycle ans += mapp[ar[i] * k]; must be first line, else if ar[i]*k == ar[i] you crushing logic of solution. This is possible not only k = 1, this is possible if ar[i] = 0. You can see test#61 is it.
P.S. after this correction there is no need to separate case k = 1.
Thanks I thought ar[i] * k == ar[i] only if k == 1 and forgot ar[i] == 0.
I spent about one hour trying to find a smart solution to problem B and I failed during the contest. But after the contest ended (of course), I found a beautiful idea. I use a map and a deque. The map is used to verify if a person has already been encountered. The deque keeps track for the "events". When a new "event" occurs it is tested: if ( — x ) is encountered and x doesn't belong to the map we will push_back the (- x) event and push_front the ( + x ) event. For all other cases ( +/- x ) is pushed_back. After that, the deque will be scanned, + increases the current nr and — decreases it. The maximum value for nr is saved and finally printed. I hope this beautiful solution will solve the problem forever.
Genius
Very easy to reason about solution!
I have a short solution too that passed during the contest here: 12371072
i had a much simpler idea. at first i checked through the list to count who was already there. then i just ran a simulation to find the answer :)
В задаче Е претесты даже не проверяют того, что участник не заметил, что граф ориентированный. Зачем так делать?
I solved problem C using DP... let dp[i][j] = the number of geometric progression with common ratio k starting from index i and with length j. now of course dp [i][1]=1. dp[i][j]=sum(dp[v][j-1]) where (v>i and a[v]=k*a[i]). one can use map to do this. the answer will be sum(dp[i][3]) where 1<= i <=n
Не могу понять, как в задаче 567D - Одномерный морской бой искать отрезок, которому принадлежит подбитая клетка, использую set?
Через upper_bound/lower_bound.
Есть сет интервалов, стреляешь в клетку x. Как узнаем, какому интервалу он принадлежит? Ищем первый интервал, гарантированно больший (x x). Это есть операция upper_bound. Что дальше? Мы нашли какой-то отрезок (l r). Возможны случаи: 1) это несуществующий отрезок; 2) l > x; 3) l = x. В первом случае поскольку гарантируется, что такой отрезок существует, то искомый отрезок — последний. Во втором случае искомый отрезок — отрезок, идущий перед (l r). А в третьем — сам отрезок (l r) является искомым.
Как-то так.
Большое спасибо за развёрнутый ответ.
Вообще говоря, на этапе, когда делаешь insert в set, результат выполнения этой функции — это пара {iterator, bool}. Булевый параметр даётся, чтобы можно было понять, вставился элемент в сет (значение true) или он уже там был (значение false). Соответственно, оптимально было бы выдернуть из этой пары итератор и уже от него отталкиваться. Но написать upper_bound() тупо проще, а уж разница между O(1) и O(logN) не настолько велика, чтобы вызвать таймлимит :)
Вообще-то тут разница не в O(1) и O(logN), а в O(С1*logN) и O(C2*logN). Ведь в любом случае нужно делать insert...
Проще всего хранить в сете пару (r, l) и при проверке клетки x брать lower_bound(make_pair(x, -1)). Скоро выложу авторские решения для лучшего понимания.
My solution for D is quite similar to described above, however it have got TL. I tried to store intervals in simple ArrayList and had to loop over it for every move to find the interval where target cell belongs. This approach is probably cause of TL. I saw solutions with TreeSet and some others, but i want to ask about my approach. Is there way to store my Intervals somehow to make access faster and avoid TL? http://codeforces.net/contest/567/submission/12377419
Instead of doing a linear search to find your interval, because of the way the set of intervals is structured(a number cant be in more than 1 interval) you can binary search for your desired interval.
But for these sorts of problems, c++ is much much MUCH better. You almost never need extra optimizations,intervals can be represented as pairs, and the set will automatically sort the pairs without any comparators needed. You can use the set::upper_bound function to find the desired interval(1 line of code whereas you would need to binary search, taking many more lines of code).
В задаче С — ошибка в тестах: 0 не может быть элементом геометрической прогрессии — по определению.
В данной задаче дано своё определение геометрической прогрессии, никакой ошибки нет.
How to apply binary search to problem C?, please.
By using map. In fact it's already a data structure with the time complexity
O(logN)Python's
dictand C++'s STLunordered_map(I think) are O(1).Wow. Can you give a further explanation?
dictandunordered_mapare just implementations of a hash table, which allow lookup in O(1).See: https://en.wikipedia.org/wiki/Hash_table
I did something a bit different from the intended solution (http://codeforces.net/contest/567/submission/12368255), but the intended solution still only needs write/lookup (and not sorting), so a hash table is adequate.
std::unordered_mapis not "ordered" (ie. you cannot do binary search on it).On top of that,
std::unordered_mapis really, really slow (faster thanstd::mapthough). I suggest not to think of it as O(1).I'll keep that in mind :)
Is there anything faster than
unordered_mapfor lookup in C++?No, unfortunately.
What I mean is, give it a bigger constant (say, 20,30) when evaluating your solution. Based on my own experience (I love solving State Space Search problems — which require a lot of it), it really is slow.
You can also consider writing your own implementation :)
I wrote mine just a few days ago with Simple Tabulation Hashing and Linear Probing (it doesn't support erase because of this) based on MIT Advanced Data Structures L10.
My poor implementation link in case you want to take a look.
You should have a look at this http://stackoverflow.com/questions/4846798/why-would-map-be-much-faster-than-unordered-map
It is O(1) on average, but O(n) at worst. For at worst.
at worst.
mapit is alwaysIn practice, it is too difficult to construct a test case that can significantly slowdown an
unordered_map.On codeforces, I see that the
unordered_mapprovides at least 2 times better performance than just amap.Even at worst case, you can play with
max_load_factorand hash function.This is all true, but you shouldn't view hash tables as a "magical bullet", the O(n) worst case can still strike. One needs to be aware of this.
I have encountered this on CF once: I used
unordered_map<int, int>as usual (with.reserve()too) and received unexpected TLE. After eliminating other factors, I changed the code tomap<int, int>— and the solution passed.I am the one who added "sortings" and "binary search" tags to C.
The top-level idea is to enumerate the middle point (call it a[i]),
then count the total number of a[i] / k (before i) and a[i] * k (after i).
To do this,
Implementation
did the same but with coordinate compression
12584852
Please ignore my ugly implementation as I am trying to get used to C++11...
But my concept is just do binary search on a vector<pair<int,int>>, no special data structure is needed :)
For problem D, simply use a map structure to record the free space (a consecutive empty square without shotpoint) on a shotpoint's left and right.
You can use the lower_bound and upper_bound functions (of map/set [IMPORTANT]) to find the nearest shotpoint, and update them.
When a shot happens a free space will be broken into 2, so calculate the sum of max number of ships of those 2 spaces and subtract it from the global sum of max number of ships.
Calculate the maximum number of ships could be placed in the space: (space+1)/(a+1)
(global sum of max number of ships = (n+1)/(a+1) before the 1st shot.)
when the global sum < k just print the current operation number and exit.
With exact same code I am getting TLE : http://codeforces.net/contest/567/submission/12382269
std::lower_bound is O(logn) if and only if you search above container with random-access iterators (you can for O(1) get any item: vector, array) and container is sorted.
Set has bidirectional iterator (you can for O(1) get only previous and next items) so std::lower_bound is O(n).
To get complexity O(logn) you need std::set::lower_bound. It is O(logn) in worst-case.
Thanks a lot! I wasn't aware of that. Got AC finally.
Another solution for D which works in O((m + n)·dsu): 12380878
Just process all shots in reverse order.
Can you give us an estimate on when the rest of the editorial will be posted?
Can anybody help me check my code of problem E: http://codeforces.net/contest/567/submission/12382102
Thanks!
You have a similar solution to mine. I think this might help you: http://codeforces.net/contest/567/submission/12375257
I think you have to push the vertex back into the queue even if dist[nex] == dist[cur] + d. Otherwise, the array way[] may not be updated for some vertex.
Consider the graph with two paths: S -> Z -> X -> T S -> A -> B -> C -> X -> T where the length of every edge is 1 (except edge (S, Z) and edge (Z, X) with length 2)
In this case, both are shortest paths. Yet, your code would only update way[X] but not way[T].
I think SPFA is not correct for calculating number of ways. You could count something many times. You have WA for this small test:
Yeah, thank you very much!
Is it because of the last two multiple roads?
You should change your Mod to 479001599. I found this number in this submission http://codeforces.net/contest/567/submission/12378788 of Solaris
I have no idea how the author of this submission can choose such prime number in his solution. Can someone help me explain this? Thanks in advance.
Thanks, it works!
Разбор збс. В основном они отстойные, но здесь все понятно. Спасибо!
ЗАЧЕМ ТАК ОРАТЬ???
I got WA in Problem D(i used binary search+Segment tree),i cannot understand where is my wrong.. here is my code http://codeforces.net/contest/567/submission/12385432
The ships cannot touch each other.
You didn't count it here. c+=(arr[i]-(a))/A; c+=(b-(arr[i]+2))/A; total=total-(t/A)+c;
OMG!!!
i had understood the problem C wrongly and it was so hard! but when i understand the corret form of problem i get AC in 10 mins! is it fair that i didn't go to div 1 for my bad English???? is it?
Every div1 programer need to know English?.. Very controversial to me:D
can anyone help me with some ideas about problem D ?
You can use binary search : try to put the first (l+r)/2 points and k recetangles without overlapping. If it is possible you try for greater value else you try for smaller. How you check if it is possible: Iterate over all point and check how many recentagles at most you can put between point i and point i+1. Also you should check how many recetangles you can put between 1 and a[1] and a[(l+r)/2] and n.
The second solution: You can use dsu or set. Start from behind and check if it is possible to put k recetangles when you have the first i points if it isn't possible you merge intervals [left andjacent point, a[i]] and [a[i],right adjacent point] and check it again.
in the first approach , do you mean by a[i] the "shot" number i ??
if it's the case , I don't agree with ,because "shots" are not given sorted by their position
thanks!
Yes, I mean that. You can sort shots every time — total complexity O ( n log ^2 n).
thank you !
Sorting doesn't always take Θ(nlogn) time. In this case it might be even easier to do a step of the binary search in linear time.
Adding small n logn each time would perfectly be O(nlognlogn)
you don't need to start from behind, just check the decrease of the max number of ship it can place when a shot happens (it's nlgn)
Can you please make me understand where is my solution wrong? Solution I cannot understand why my checker function is wrong??
I have spent a lot of time and I still cannot understand why this F function works Sol2
Actually what I am doing is putting the rectangles of length A between the positions.
Please help ! I am trying since yesterday!
A lot people were talking about it. You should divide with a+1 in check function ( reason- two ships can't touch each other ).
About F, I didn't read it, but also I don't believe I can help you... I am not on level to understand every solution for some F problem :)
The solution in details is to do a binary search against the array of moves — to find the first move, when it becomes impossible to put m ships on the board. As far as I see — this approach was used by the majority of div1 participants. Makes sense, as it is simple and now complex structures are needed at all.
So we have to write a function F(p), which returns whether it is possible to place the ships for a situation after move with number "p" .
The initialization step is to check F(m). If it is "true", then our result is immediately "-1". I.e. after "m" moves we are still able to place all the ships on the board.
We don't need to check the start of the moves, as according to the problem statement, initially it is possible to place the ships there.
And so we start the main loop to perform half-division search over moves. The initial interval to check is from 1 to "m". During every iteration we calculate F( (l + r) / 2 ). If it is positive, then out solution is somewhere in the right half of the current interval. If it is negative, then the solution is in the left half of the current interval. And so on.
The binary search is O(logN). The quite simple F is O(N). Thus the general time complexity is O(N * logN).
I like submission 12361499, where the concept is shown quite well.
My O(nlognlogn) solution got TLE. :/
Since E and F editorials aren't up yet, could anyone explain the approach?
Problem E
Problem F
I think Problem E needs more explanation.
In case you don't understand the discussion, reply below and I'll explain :)
It needs some graph theory facts.
PLease explain Problem E. I have been struggling hard since an hour to understand the editorial
I have explained his ideas in my other comment below.
My solution is based on this fact (This should be easier if you have some graph theory knowledge):
Very nice problems, vovuh, especially C, E and F which I liked very much, looking forward to your next round! :)
For E, let dist_s[i] be the distance from s to i and cnt_s[i] be the number of shortest paths from s to i. These values can be computed using Dijkstra's algorithm, check my submission for more details. Then, let dist_t[i] be the distance from i to t and cnt_t[i] be the number of shortest paths from i to t. Those values can be computed by reversing the edges and running Dijkstra's algorithm from t.
After that, there are some cases to be considered for each edge (from[i], to[i], length[i]), let's assume that shortest is the distance between s and t, which is dist_s[t] and dist_t[s] and current is equal to the current length which is length[i]+dist_s[from[i]]+dist_t[to[i]]:
1) If current is equal to shortest, then the edge will be used for sure only if all shortest paths from s to t pass through this edge. So if cnt_s[t] is equal to cnt_s[from[i]]*cnt_t[to[i]], then the answer is YES. Otherwise, we need to decrease it's length by 1, so if length[i]>1, then the answer is CAN 1. Otherwise, the answer is NO.
2) If current is greater than shortest, then we need to make current equal to shortest-1 so if current-(shortest-1)<length[i], then the answer is CAN (current-(shortest-1)). Otherwise, the answer is NO.
Note that the cnt_s and cnt_t values may be really really big so in the topic I read about taking them modulo some number, and maybe taking them modulo two different numbers is a better idea, it makes the chance of collision lower. By the way, when I used 10^9+7 as MOD, I got WA and when I changed it, the verdict became accepted. However, I doubt the author solution uses MOD so it will be good to see it soon.
For F the best I found is this comment by Errichto — http://codeforces.net/blog/entry/19590?#comment-244086
can anyone helps me in Problem E ... i think my approach is right but im getting a WA on case 37 : 12402935 any help is appreciated :)
Am I supposed to do Dijkstra with priority queue? I get TLE on the first test case with N=100000 & M=100000 otherwise.
[submission:1000776999]
Yes.
I took a look. Your submission runs in O(V2).
Reason: V Extract-Min & Relaxations, and Each iteration runs in O(V)
=> V * O(V) = O(V2)
Tried solving the C problem using two binary searches per index for find the number of terms a/k on left and a*k on the right. Ofcourse over a sorted sequence of the input data, sorted by size then by id if values are equal. Wondering why it timed out. http://codeforces.net/contest/567/submission/12399316
try this 200000 1 1 1 1 1 1 1 1 1....
Oh btw I really enjoyed the problemset.
later possible any means for example 2 hours later , 2 months later , 2 years later and 2 centuries and now what do you think?
Thanks for upd!
can any body help please, what is the bug in my solution for E ,does number of ways fit in long long? here
No. The number of ways can be something like 250000.
The more correct way to do this is to module the number by one or several(just to be safe) big prime number(s). This is still incorrect nonetheless, but has a very small error rate.
thanks. actually after trying 1000001447 as modulo i got AC.
someone please explain this part of problem E. How to find whether a given edge is visited for sure by the president vs may or may not case.
"Let's build shortest path graph, leaving only edges described above. If we consider shortest path from s to t as segment [0..D] and any edge (u, v) in shortest path graph as its subsegment [d1[u]..d1[v]], then if such subsegment do not share any common point with any other edge subsegment, except its leftest and rightest point (d1[u] and d1[v]), this edge belongs to every shortest path from s to t."
His idea is pretty interesting.
I am not sure if I understood it correctly, but here it goes:
D).The distance traversed starts from
0(Starting vertex) toD(Terminal).(u, v)on the shortest path graph.Suppose the shortest distance to u is
d(u)and the shortest distance to v isd(v)This edge essentially allows us to go from
d(u)tod(v).d(u)tod(v)" as an interval [d(u), d(v)]0toD.If an interval doesn't overlap w ith other intervals (from other edges),
then this means that if we would like to "pass through" any value of distance
this edge is the only way to go, which means this edge always exists in the shortest paths.
Hope this helps.
Hey thanks for replying. Couldn't understand the 5th point in your explanation. For example in the first test case: going from Node 1 to node 2 has cost 2. Then d(1) =0 , d(2)= 2, so the interval is [0,2], which is present no where else. But d(2)= 2, d(3)=7 , so interval is [2,7], which is also no where else present. So how do we make d(2),d(3) edge as an edge which is not always mandatorily visited vs only the d(1),d(2) as mandatorily visited by the president ?
d(3) = 9 actually.
[2, 9] overlaps with the interval [d(2), d(4)] = [2, 10]
Hey, thank you for the reply.
But if we search every edge with every other edge to find whether it is getting overlapped or not then wouldn't it cause a E^2 complexity , which is greater than E*log(V).
Also can u please suggest a method and the data structure for such verification ?
I think Sweep Line Algorithm should work here.
Basic idea is sort the intervals, first by starting point then by ending point.
Then scan the edges from left to right.
Complexity would be O(ElogE) = O(ElogV).
I didn't solve the problem this way, so I cannot really go into details on this. In case I made a mistake, let me know :)
my soln: http://codeforces.net/contest/567/submission/12425879
I submitted solution to E by checking each edge with every other edge. As we discussed, it is giving time limit exceeded for 19th case , which has 10^5 size of n.
I think, I am almost close to getting an AC. Just need a little help to cross the time limit barrier. Can u please explain how you solved, this interval verfication phase of the problem ?
Like I said, I didn't solve the problem this way.
You can perhaps look at the author's solution.
Problem E: can some one please help me understand how to improve the performance of my code ? I have used dijkstra's algo two times, 2nd time to get shortest dist from destination to other vertices,which takes 2*E*logV.
Now finding the interval that overlaps is taking E*E=E^2. How can i improve it better to reduce the time taken to identify whether a particular edge is for sure visited by the president vs not for sure case?
http://codeforces.net/contest/567/submission/12426802
You are checking overlap intervals online, while I did it offline, as said in the editorial, given a set of segments [l,r], we want to see if there is any other segments intersect it.
One way to do this is as follow:
Store all edges which are part of shortest path
Convert them into segments [l,r] as said in the editorial
Sort the segments O(E lg E)
Loop through segment, keep track the rightmost distance R you get so far, for each segment [l,r] check if l < R, it is being intersected if it's true O(E)
After this, the remaining segments are those without intersecting, which you must pass through it, total with O(E lg E)
Пора бы уже прикрепить его к раунду.
can anyone explain this line in the editorial of problem D
Each ship occupies a + 1 cells, except the last ship. Thus, for segment with length len the formula will look like (we add "fictive" cell to len cells to consider the last ship cell). This way, for [l..r] segment the formula should be http://codeforces.net/predownloaded/da/ab/daabfbc41456dfe3fc74f8b0eba284b1893a8abd.png .
why we have to use n+1 / (a+1) instead of (n/a). And also each ship occupies only a cells right..why it is a+1.
Ships cannot touch
can anyone explain how this code works? (author's D solution)
auto it = xs.lower_bound(mp(x, -1));At the problem F! Which sequences are answer for the first test case
From problem E after building the shortest path graph, we could simply find all bridges in that graph assuming it is undirected. Those would be the edges that would be "YES". My accepted solution doing the same: http://codeforces.net/contest/567/submission/27506292
The shortest path graph (call it G) would be a directed acyclic graph. We need to find all edges such that their removal would lead to no path from S to T. If we consider the undirected version of the G (call it U) then a bridge in U would also be a bridge in G. Further a bridge in U would always lead to two components that seperate out the nodes S and T. Hence a bridge in U would be a YES.
We need to prove the reverse i.e. an edge marked YES in G would be a bridge in U. Say in U we remove an edge marked YES. This should lead to two components, for if it didn't then there should be a back edge connecting the two components containing S and T, but since G is a DAG this isn't possible
Getting TLE for C. I have used DP, I dont know if I can optimize more using recursive DP. Please help me out:
http://codeforces.net/contest/567/submission/38002243